
피크 타임 Pod 245개를 100여개로 — DynamoDB SDK v2 전환으로 Go 서버 CPU 절반 줄이기
Server Engineer
세줄 요약
- Pyroscope 모니터링으로 CPU 점유가 높은 경로 파악
- DynamoDB wrapper 라이브러리 하위의 AWS SDK v1 unmarshal이 원인 — 라이브러리 메이저 버전 업데이트로 해결
- 요청당 CPU 59% 감소, 피크 타임 기준 HPA가 요구하는 파드 수 245개 -> 109개 감소
Supply 그룹에서 메인으로 운영 중인 Go 애플리케이션은 저녁 피크 시간마다 파드 수가 200여개 이상으로 늘어나는 패턴이 지속되고 있었습니다. 처음에는 피크 시간 기준으로 시간 당 7천만건의 요청을 처리하기 때문에 이 정도 파드 수(HPA)는 합당하다고 생각했지만 Pyroscope로 profiling한 결과, DynamoDB 클라이언트 라이브러리가 CPU 병목의 원인임을 파악하여 라이브러리 업그레이드만으로 요청당 CPU를 59% 줄이고 파드 수를 100여개 수준으로 낮출 수 있었습니다. 이번 글에서는 Pyroscope로 병목을 찾고 실제 지표로 개선 효과를 확인한 과정을 공유합니다.
Pyroscope에서 발견한 CPU 병목
Pyroscope에서 저녁 피크 시간대의 CPU profile을 확인했을 때 가장 먼저 눈에 들어온 것은 guregu/dynamo였습니다.
flame graph에서 DynamoDB 조회 경로가 넓었고 하위의 AWS SDK v1의 JSON unmarshal과 reflection 관련 호출이 길게 이어지고 있었습니다.
처음에는 요청량이 가장 많은 광고 서빙 API가 DynamoDB를 적극적으로 사용하기 때문에 DynamoDB 호출 수가 많은 것을 의심했습니다. 하지만 flame graph에서 네트워크 I/O는 거의 보이지 않았고 오히려 실제로 CPU Time을 많이 차지하는 부분이 어디인지 명확히 파악할 수 있었습니다. (해당 시간대 DynamoDB 모니터링에서 latency와 throttling이 관측되지 않은 점도 원인 파악에 도움을 주었습니다.)
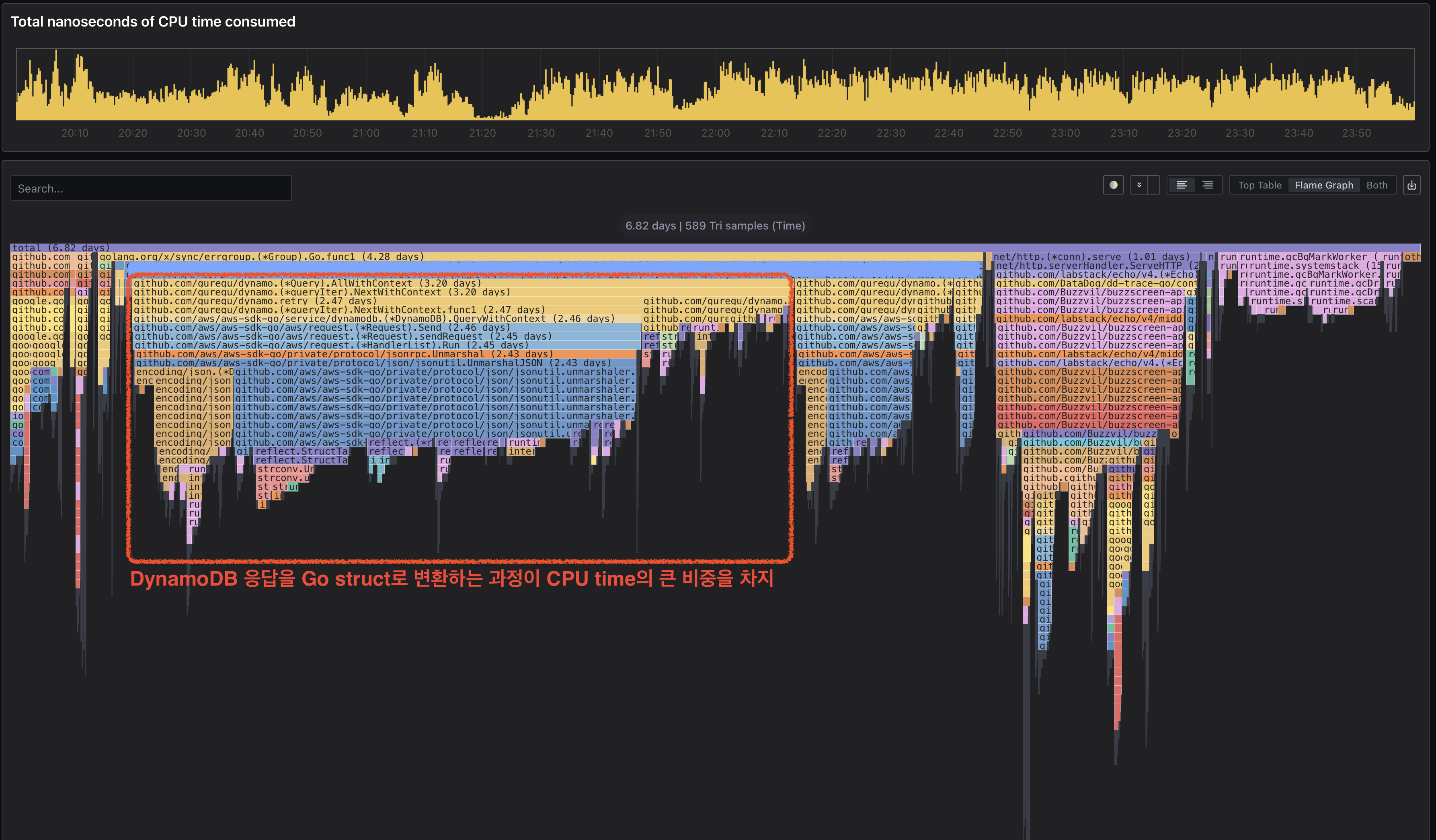 배포 전 피크타임 flame graph — guregu/dynamo 하위 경로가 전체 CPU의 절반 가까이를 차지하고 있습니다.
배포 전 피크타임 flame graph — guregu/dynamo 하위 경로가 전체 CPU의 절반 가까이를 차지하고 있습니다.
flame graph에서 드러나듯이 DynamoDB 조회 이후 "Response를 Go struct로 바꾸는 과정에서 CPU를 많이 소모한다"는 점을 확인했습니다. 일반적으로 JSON unmarshal의 CPU 비용이 높다는 사실을 알고 있었지만 실제 profiling 결과도 unmarshal 과정이 CPU를 오래 점유하는 것을 보여줬기에 그에 맞는 개선 방향을 잡을 수 있었습니다.
원인: wrapper 아래의 AWS SDK v1
당시 애플리케이션 코드는 DynamoDB를 직접 AWS SDK로 호출하지 않고 guregu/dynamo라는 wrapper 라이브러리를 사용 중이었습니다.
guregu/dynamo는 테이블, 쿼리, 조건식, struct marshal/unmarshal 같은 부분을 개발자가 쓰기 쉽게 감싸주는 wrapper로 실제 HTTP 요청, 인증 서명, DynamoDB protocol 처리, 응답 파싱은 AWS SDK가 담당합니다.
애플리케이션 코드
|
v
guregu/dynamo
|
v
AWS SDK for Go
|
v
DynamoDB
flame graph에서 guregu/dynamo가 넓게 보인 것은 wrapper 자체의 문제라기 보다, 내부에서 호출되는 AWS SDK v1의 DynamoDB 처리 비용까지 함께 집계되었기 때문입니다. 즉 근본적인 개선 방향은 SDK 처리 경로를 변경하는 것이었고 guregu/dynamo의 major version을 업데이트를 통해 내부에서 사용하는 AWS SDK도 함께 업데이트 되는 점을 확인했습니다. 이를 근거로 guregu/dynamo v1 -> v2 버전 업데이트를 결정했습니다.
| 라이브러리 | 내부에서 사용하는 AWS SDK |
|---|---|
github.com/guregu/dynamo v1 | github.com/aws/aws-sdk-go v1 |
github.com/guregu/dynamo/v2 | github.com/aws/aws-sdk-go-v2 |
겉에서 봤을 땐 단순히 wrapper 라이브러리의 버전 업데이트지만 근본적으로는 AWS SDK v1에서 AWS SDK v2로 DynamoDB 처리 방식을 변경하기에 큰 개선 효과를 기대할 수 있었습니다.
v1 -> v2 전환 작업
코드 변경 자체는 복잡하지 않았습니다.
기존에는 github.com/guregu/dynamo를 사용했고 변경 후에는 github.com/guregu/dynamo/v2를 사용했습니다.
// before
import "github.com/guregu/dynamo"
err := table.
Get(hashKey, value).
AllWithContext(ctx, &items)
// after
import "github.com/guregu/dynamo/v2"
err := table.
Get(hashKey, value).
All(ctx, &items)
초기화 코드도 v2용 DynamoDB client를 사용하도록 개선했습니다.
ddb := dynamo.NewFromIface(infra.DynamoDBV2())
table := ddb.Table(tableName)
겉보기에는 메서드 이름에서 WithContext가 빠진 정도로 보이지만 unmarshal 메커니즘에는 꽤 큰 차이가 있습니다.
다만 wrapper의 메이저 버전과 그 아래 AWS SDK가 함께 바뀌는 작업인 만큼 배포는 한 번에 전체로 내보내지 않았습니다. 카나리 배포로 일부 트래픽에 먼저 적용해 에러율과 동작 이상이 없는지 확인한 뒤 점진적으로 확대했습니다.
적용 범위: 광고 서빙 경로의 공통 병목
이 변경은 단일 API의 최적화가 아닌 여러 광고 서빙 요청에서 공통으로 호출되는 사용자 조회 경로를 개선한 작업이었습니다. 광고 서빙 요청은 사용자 식별과 활동 이력, 타겟팅 데이터를 함께 조회한 뒤 후보 광고를 고르는 구조인데, 이때 사용자 관련 데이터는 모두 DynamoDB에서 공통 어댑터 경로로 저장·조회됩니다. 이 공통 경로가 무거워지면 특정 요청 하나가 아닌 광고 서빙 계열 요청 전반의 CPU 비용이 함께 올라갑니다.
코드 변경 자체는 비교적 적은 diff로 버전 업을 진행할 수 있었지만 영향 범위로 보면 작은 변경이 아니었습니다. Datadog APM indexed span 기준으로도 피크타임 1시간 동안 사용자 조회 경로는 천만 건 이상으로 관측됐습니다. 즉 이번 개선은 호출 빈도가 높은 공통 경로의 cost를 줄인 작업이었고 덕분에 서비스 전체 CPU 지표도 눈에 띄게 개선된 것을 확인할 수 있었습니다.
배포 전후 측정 결과
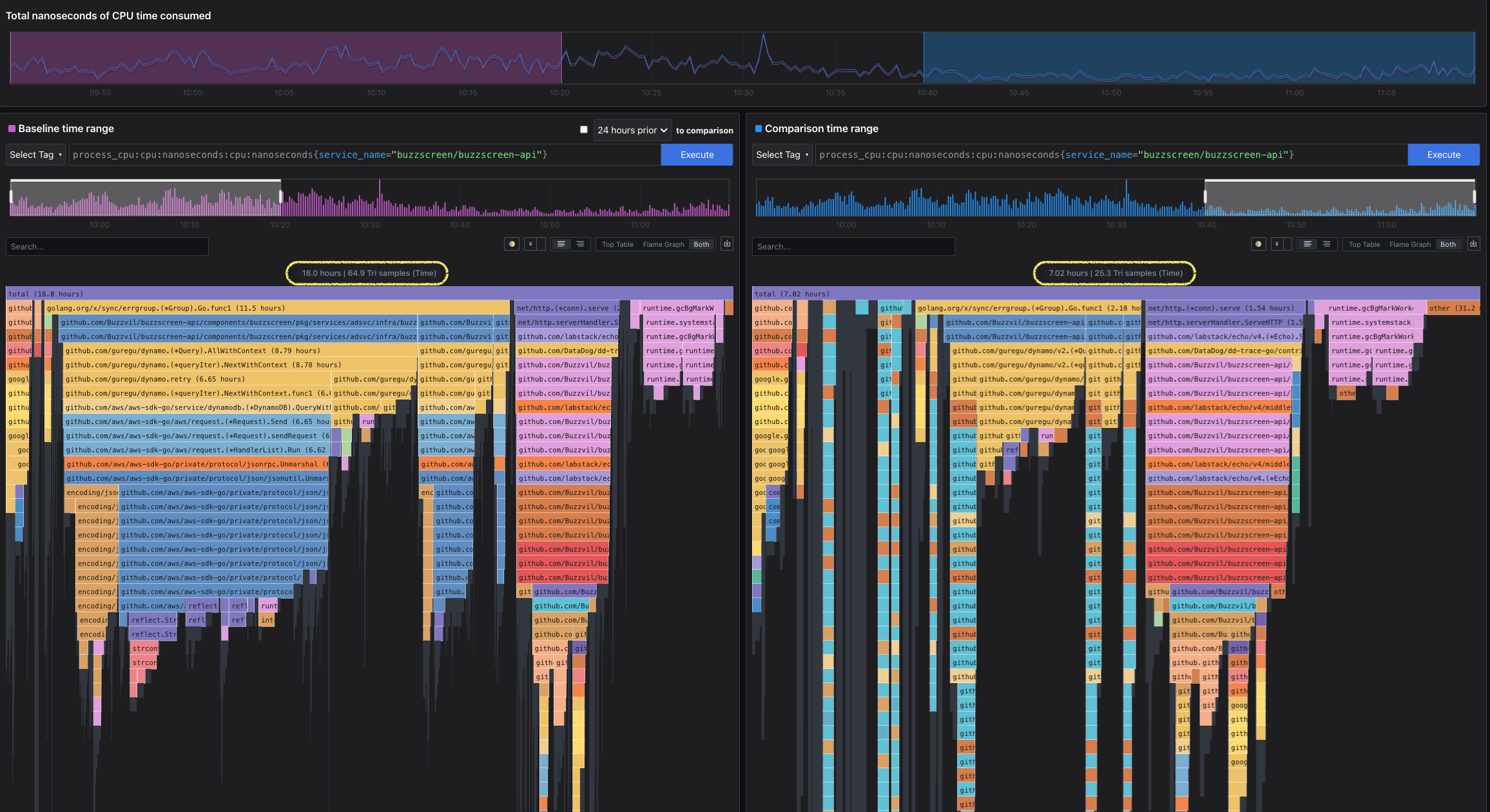 배포 전후 Pyroscope CPU profile 비교 — 배포 후 AWS SDK v1 unmarshal 경로가 사라졌습니다.
배포 전후 Pyroscope CPU profile 비교 — 배포 후 AWS SDK v1 unmarshal 경로가 사라졌습니다.
위 pyroscope compare 이미지는 배포 시각을 기준으로 배포 전 30분과 배포 후 30분을 비교했습니다. 배포 직후에는 구버전과 신버전 pod가 섞일 수 있어, 배포 후 첫 10분은 제외했습니다.
| 구간 | 시간 |
|---|---|
| 배포 시각 | 2026-06-26 10:30 KST |
| 배포 전 | 2026-06-26 09:50-10:20 KST |
| 배포 후 | 2026-06-26 10:40-11:10 KST |
Pyroscope의 CPU profile은 wall clock 시간이 아니라 CPU sample을 누적해서 표시합니다.
여러 pod와 여러 CPU core에서 소비한 시간이 합산되기 때문에 30분 구간을 조회하더라도 18h 같은 값이 나올 수 있습니다.
| 지표 | 배포 전 | 배포 후 | 변화 |
|---|---|---|---|
| Pyroscope CPU 샘플 | 18h | 7h | -61.0% |
| 요청 수 | 30,057,920 | 28,784,846 | -4.2% |
| 요청당 CPU | 2.149ms | 0.876ms | -59.2% |
요청 수가 약간 줄기는 했지만 CPU 감소폭과는 차이가 큽니다. 요청당 CPU로 보정해도 약 59% 개선됐기 때문에 실제 처리 비용이 줄었다고 보는 것이 자연스럽습니다.
CPU 해소 포인트
전체 CPU만 보면 결과는 알 수 있지만 원인은 알기 어렵습니다.
그래서 Pyroscope에서 cumulative CPU 기준으로 어떤 함수가 줄었는지 확인했습니다.
cumulative CPU는 해당 함수 자체에서 쓴 CPU뿐 아니라, 그 함수가 호출한 하위 함수에서 쓴 CPU까지 포함한 값입니다.
API handler나 repository 함수처럼 여러 일을 묶어서 수행하는 함수의 비용을 볼 때 유용합니다.
| 경로 | 배포 전 | 배포 후 | 변화 |
|---|---|---|---|
| 사용자 활동 조회 | 31,865s / 49.32% | 4,929s / 19.54% | -84.5% |
| 타겟팅 모델 조회 | 8,154s / 12.62% | 1,916s / 7.59% | -76.5% |
| AWS SDK v1 JSON unmarshal | 30,347s / 46.97% | 642s / 2.55% | -97.9% |
reflect.StructTag.Lookup | 8,724s / 13.50% | 840s / 3.33% | -90.4% |
runtime.scanobject | 6,159s / 9.53% | 2,864s / 11.35% | -53.5% |
가장 눈에 띄는 변화는 AWS SDK v1의 JSON unmarshal 비용입니다.
배포 전에는 전체 CPU의 거의 절반이 github.com/aws/aws-sdk-go/private/protocol/jsonrpc.Unmarshal 아래에 있었습니다.
배포 후에는 이 비중이 2.55%까지 내려갔습니다.
배포 전후 4일: HPA가 요구하는 파드 수 절반으로
배포 직후 1시간 비교는 즉각적인 효과를 보여주지만 HPA는 피크 시간과 평상시를 오가며 반응하므로 스케일링 효과는 더 긴 구간에서 검증해야 정확합니다. 그래서 배포 전 4일과 배포 후 4일을 다시 비교했습니다.
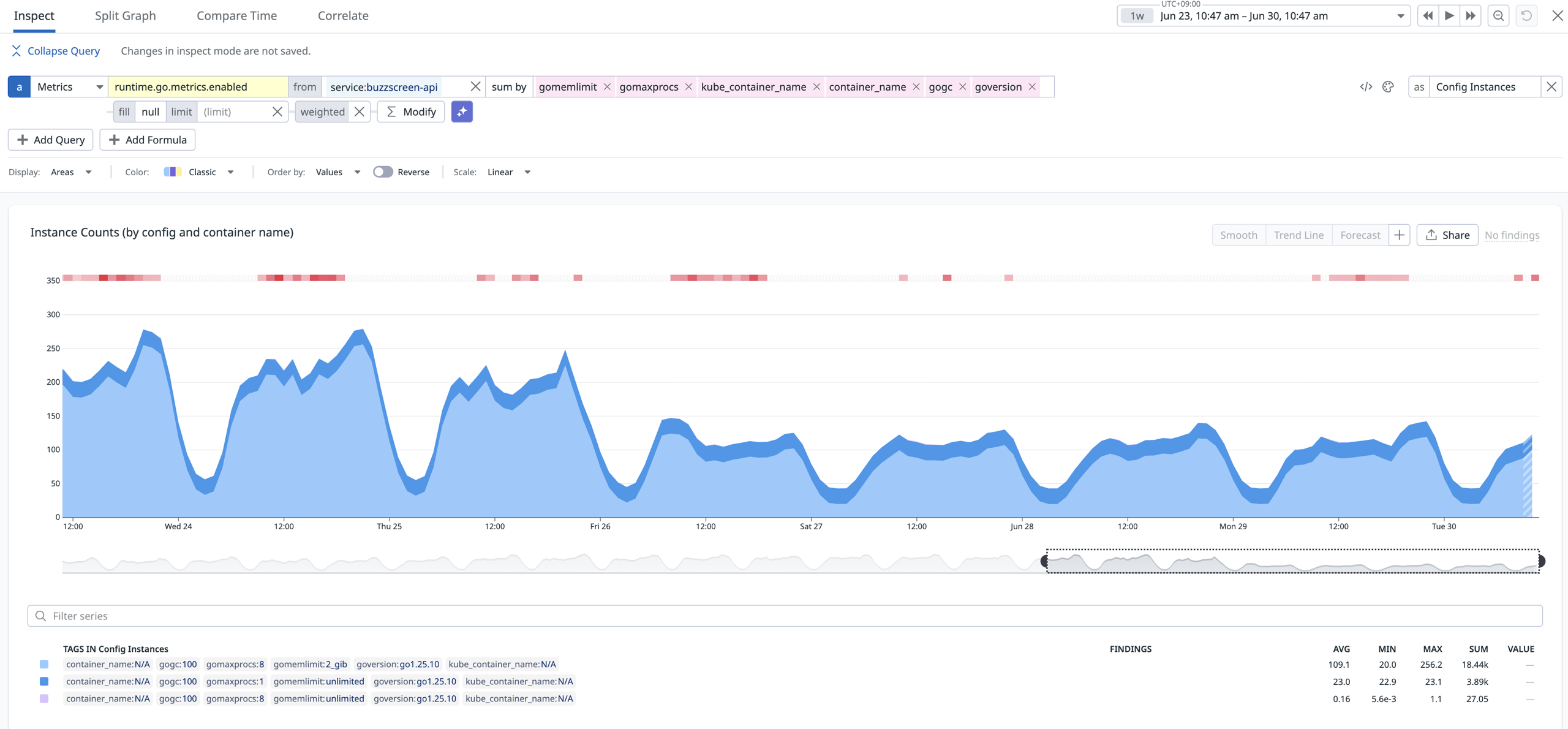 배포(6/26) 전후 일주일간 pod instance 수 추이 — 매일 반복되던 피크의 높이가 배포 이후 눈에 띄게 낮아졌습니다.
배포(6/26) 전후 일주일간 pod instance 수 추이 — 매일 반복되던 피크의 높이가 배포 이후 눈에 띄게 낮아졌습니다.
| 항목 | 배포 전 4일 | 배포 후 4일 | 변화 |
|---|---|---|---|
| Datadog CPU avg | 690 cores | 369 cores | -46.6% |
| Datadog CPU p95 | 1,418 cores | 788 cores | -44.4% |
| HPA desired p95 | 245 | 109 | -55.3% |
| 요청 수 | 5.06B | 4.58B | -9.5% |
| 에러율 | 0.0549% | 0.0510% | 소폭 개선 |
| 평균 duration | 2.61s | 2.54s | 소폭 개선 |
피크 시간대 HPA가 요구하던 파드 수(p95)는 245개에서 109개로 감소했습니다. 같은 기간 요청 수 감소는 -9.5%에 그쳤기에 단순 트래픽 감소보다 요청당 처리 비용을 드라마틱하게 감축한 것으로 볼 수 있었습니다.
요일 효과를 배제하기 위해 배포 일주일 전과 배포 다음 날, 같은 요일·같은 시간대의 Kubernetes 지표도 나란히 놓고 확인했습니다.
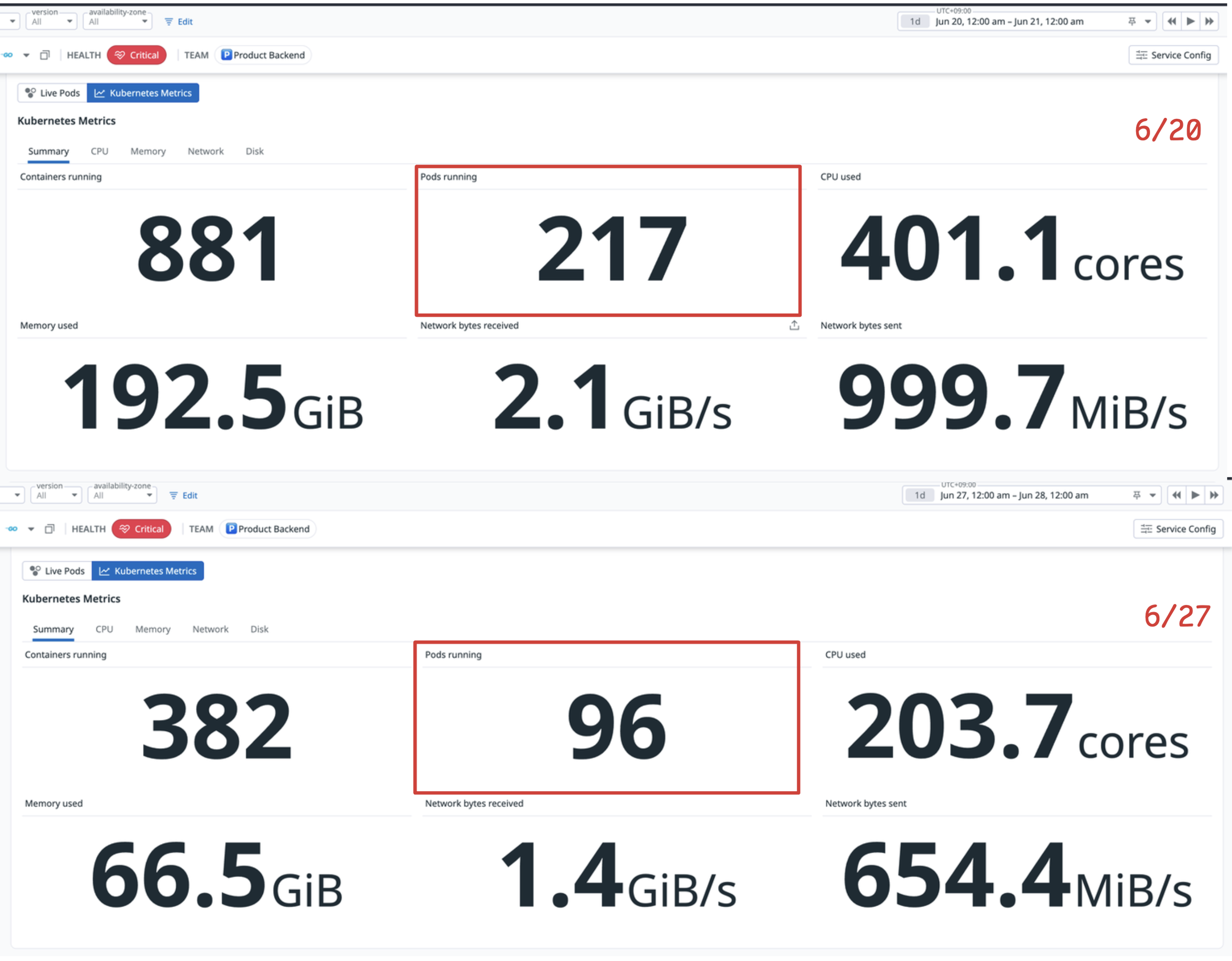 배포 일주일 전(6/20, 위)과 배포 다음 날(6/27, 아래) 같은 시간대 비교 — running pod 217개 → 96개, CPU 401.1 cores → 203.7 cores.
배포 일주일 전(6/20, 위)과 배포 다음 날(6/27, 아래) 같은 시간대 비교 — running pod 217개 → 96개, CPU 401.1 cores → 203.7 cores.
파드 수 감소는 그대로 인프라 비용 절감으로 이어졌습니다. 해당 서비스가 사용하는 EKS 클러스터의 일 비용은 $400대에서 $250 수준으로 내려왔습니다.
v2에서는 무엇이 달라졌나
DynamoDB 조회는 동일하게 수행하는데 v2에서는 무엇이 개선됐기에 CPU를 절반 수준만 소모할까요?
v1: reflection 기반 generic JSON 처리
배포 전 profile에서 가장 크게 보인 함수는 AWS SDK v1의 JSON unmarshal 경로였습니다.
주목해야 할 단어는 reflection입니다.
reflection은 런타임 중 타입 정보를 들여다볼 수 있는 기능입니다.
예를 들어 어떤 struct에 필드가 몇 개 있는지, 각 필드의 tag가 무엇인지, 이 값이 pointer인지 slice인지 등의 정보를 런타임에 확인할 수 있습니다.
하지만 매 요청, 응답 item, 필드마다 reflection이 반복되면 CPU 비용이 커집니다.
AWS SDK v1의 DynamoDB AttributeValue는 하나의 큰 struct에 여러 타입을 포인터 필드로 들고 있습니다.
type AttributeValue struct {
B []byte
BOOL *bool
L []*AttributeValue
M map[string]*AttributeValue
N *string
S *string
// ...
}
DynamoDB의 값 하나는 이 struct 하나로 표현됩니다. 값이 문자열이면 S 필드에만 값이 들어가고 나머지 필드는 전부 nil이며, 숫자면 N에만 값이 들어가는 식입니다.
그래서 값을 읽을 때마다 "어떤 필드가 채워져 있는지"를 하나씩 확인해야 실제 타입을 알 수 있고, 이 확인 작업이 응답의 모든 item, 모든 필드에서 반복됩니다.
또 AWS SDK v1의 JSON protocol 코드는 struct field와 tag를 reflection으로 훑습니다.
Pyroscope에서 reflect.StructTag.Lookup이 크게 보인 이유도 여기에 있습니다.
실제 flamegraph에서 보인 흐름은 아래와 같습니다.
사용자 조회 경로
|
v
guregu/dynamo v1 Query.AllWithContext
|
v
aws-sdk-go v1 jsonrpc.Unmarshal
|
v
jsonutil.unmarshalStruct
|
v
reflect.StructTag.Lookup
DynamoDB 조회 후 응답을 Go struct로 바꾸는 과정에서 runtime reflection이 너무 많이 수행되고 있었습니다.
v2: 생성된 serializer와 union 타입
AWS SDK v2의 DynamoDB AttributeValue는 v1과 모양이 다릅니다.
하나의 큰 struct에 모든 타입을 넣는 대신, 타입별 struct를 나누고 interface로 묶는 union 형태를 사용합니다.
type AttributeValue interface {
isAttributeValue()
}
type AttributeValueMemberS struct {
Value string
}
type AttributeValueMemberN struct {
Value string
}
type AttributeValueMemberM struct {
Value map[string]AttributeValue
}
문자열이면 AttributeValueMemberS, 숫자면 AttributeValueMemberN처럼 실제 값의 타입이 분리됩니다.
serializer와 deserializer는 이 타입을 기준으로 switch를 수행합니다.
switch v := av.(type) {
case *types.AttributeValueMemberS:
// string 처리
case *types.AttributeValueMemberN:
// number 처리
case *types.AttributeValueMemberM:
// map 처리
}
이 방식은 generic reflection 기반 JSON 처리보다 DynamoDB 응답 구조에 더 특화되어 있습니다. AWS SDK v2는 service model을 기반으로 생성된 serializer/deserializer 코드를 사용합니다. 쉽게 말하면 “응답이 어떤 모양인지 실행 중에 매번 알아내는 코드”가 아니라, “DynamoDB response가 어떤 모양인지 알고 있는 코드”에 가깝습니다.
여기에 guregu/dynamo/v2 쪽도 struct 타입 정보를 캐싱합니다.
v1에서는 struct field를 매번 훑는 비용이 profile에서 fieldsInStruct로 잡혔고, v2에서는 type cache를 통해 field 처리 계획을 재사용합니다.
정리하면 변화는 다음과 같습니다.
| 구분 | v1 | v2 |
|---|---|---|
| DynamoDB 래퍼 | guregu/dynamo | guregu/dynamo/v2 |
| AWS SDK | aws-sdk-go v1 | aws-sdk-go-v2 |
| AttributeValue 표현 | 포인터 필드가 많은 큰 struct | 타입별 struct를 나눈 union 형태 |
| protocol 처리 | reflection 기반 generic JSON 처리 비중 큼 | 생성된 DynamoDB serializer/deserializer 사용 |
| struct field 처리 | 반복 reflection 비용이 profile에 크게 노출 | 타입 정보 캐시 활용 |
단순히 메이저 버전 업그레이드를 해서, 혹은 SDK v2가 빠르기 때문이 아니라 v2 전환으로 reflection 기반 JSON decode와 struct tag 탐색이 줄었고 이 변화가 CPU 개선으로 이어졌습니다.
작은 벤치마크로 다시 확인하기
운영 profile만으로도 방향은 충분히 보였지만, marshal/unmarshal 자체의 차이를 확인하기 위해 비슷한 형태의 struct로 작은 벤치마크도 돌려봤습니다. 벤치마크는 Go 1.24 Mac 로컬 환경에서 실행했습니다. 운영 환경을 그대로 재현한 것은 아니므로 절대값보다는 경향만 확인하는 용도입니다.
| 작업 | v1 | v2 | 차이 |
|---|---|---|---|
| Marshal | 약 2.5-2.7µs / 47 allocs | 약 0.8-1.0µs / 17 allocs | 약 2.5-3배 빠름 |
| Unmarshal | 약 2.3-2.7µs / 23 allocs | 약 2.1-2.4µs / 10 allocs | 할당 수 절반 이하 |
이 벤치마크도 production 결과와 같은 방향을 가리켰습니다. 특히 marshal 쪽은 시간과 allocation 모두 크게 줄었고, unmarshal 쪽은 시간 차이보다 allocation 차이가 더 뚜렷했습니다.
Go 애플리케이션에서 allocation이 줄면 그 자체로도 좋지만 더 중요한 점은 GC가 나설 일이 줄어든다는 점입니다.
이번 profile에서도 runtime.scanobject의 절대 CPU가 6,159s에서 2,864s로 감소한 것을 확인할 수 있었습니다.
마무리
Pyroscope로 CPU 병목의 원인을 파악하고도, 라이브러리 전환 하나로 이렇게 드라마틱한 리소스 개선이 나올 것이라고는 예상하지 못했습니다. 버전업 작업 자체는 AI Agent의 도움으로 손쉽게 마칠 수 있었고 그 변경이 실제 지표 개선으로 이어지는 것을 확인할 수 있어 의미있는 경험이었습니다. 이번 변경으로 서버 비용은 일 $400에서 $250 수준으로 내려왔고 월 기준으로는 $3,500~$4,500를 절감할 수 있었습니다.
구현이 쉬워진 것과 별개로 문제를 인식하고 원인을 파악하는 것은 여전히 엔지니어링이 필요한 영역이라 생각합니다. 성과를 내는 일이 점점 쉬워지는 AI 시대에, 엔지니어에게 필요한 역량이 무엇인지 다시금 생각하게 되는 경험이었습니다.

