
딥러닝 (Tensorflow) 을 이용한 추천시스템 개발
1. 글을 시작하기 전에
안녕하세요, 모바일 잠금화면 애드네트워크 버즈빌의 컨텐츠와 머신러닝 product manager 곽상훈 (Mike) 입니다. 버즈빌은 딥러닝을 이용하여 개인화된 컨텐츠를 자동 추천, 사용자 경험을 도우며 광고 플랫폼으로서의 기술적 우위를 보유하고 있습니다. 이 블로그에서는, 이러한 로직의 개발 과정과 결과를 소개하려고 합니다. 기초적인 neural network background 가 있다는 가정하에 코드는 최소화 하고 머신 러닝 모델의 high level design 위주로 기술하였으며, 자세한 수식/증명/예시/코드 등에 관해서는 도움이 될만한 참고 링크들을 첨부하였습니다.
2. 배경
10 년전만 해도 흔히 쓰이던 인공지능 기술들은 보편적인 기계 학습에 쓰이기엔 부족함이 많았습니다. 그 원인 중 하나는 자동 feature selection 의 부재였습니다. 자연어 처리를 위한 feature 들 (e.g. 형태소 분석), image recognition 을 위한 feature 들 (e.g. edge detection) 등, specialized 된 목적을 위해 각 분야의 전문가들이 제작한 handmade feature 들에 의존을 많이 했기 때문입니다. 최근에 재조명을 받고 있는 neural network -- 혹은 deep learning -- 은 자동 feature learning 을 통하여 이 고민을 해결해 주어 분야에 관계 없이 보편적인 기계 학습을 하기에 조금 더 적합한 기술입니다. Black box 라서 모델을 직관적으로 이해하기 어렵고, training 시간도 오래 걸리고, parameter tuning 에 많은 노력이 소요되는 등의 단점들이 있지만, 전반적인 pattern recognition 에 있어서는 기가 막힌 효과를 보인다는 것은 이미 증명이 되었습니다 (참고: http://karpathy.github.io/2015/05/21/rnn-effectiveness/). 처음 RNN 을 접하고 제 맥북으로 [이문열의 삼국지] 10권을 input 으로 위 링크에서 소개한 실험들과 비슷한 실험을 했는데 그럴싸한 결과가 나왔습니다 (따옴표, 물음표, 느낌표가 절묘합니다).
그 말을 듣자 원소의 말에 조조는 원소에게 물었다.
"너는 어디 없이 이렇게 말했다. 이 말 아래로 돌피지 않으면 반드시 그 군사들을 죽이려 드는 것이 있다. 이번에는 원소와 함께 그들을 치고 달리 어찌 한가지는 것이냐!"
그 말을 들고 조조가 다시 물었던 것이다.
"저희들은 모두 군량이 있으니 어떤 것이 오늘이오?"
원소는 조조가 그렇게 대답하며 말했다. "이 분은 무슨 말이냐?""그 자리 같은 사졸들을 죽여 그 말을 듣고 있습니다. 이미 저것입니다"_ 그럼 거두절미하고 이 강력한 툴을 이용하여 버즈빌에서 만든 추천 로직을 소개 하겠습니다.
3. Application
버즈빌이 미국과 유럽에서 서비스 중인 Slidejoy 에서는 유저들을 위해 락스크린에 광고 외에도 다양한 컨텐츠를 제공하고 있습니다. 200 개 이상의 content provider 들로부터 매 시간 10,000 개가 넘는 기사를 저장, 정제하여 카테고리 별로 유저들에게 제공합니다 (참고: https://techcrunch.com/2016/01/28/lockscreen-app-slidejoy-gets-a-newsy-new-feature/). 초기 (neural network 적용 이전) 에는 컨텐츠들을 간단한 unigram tf-idf 방식으로 grouping 하여 가장 많이 mention 된 토픽 순서로 모든 유저들에게 일괄적으로 보여줬습니다.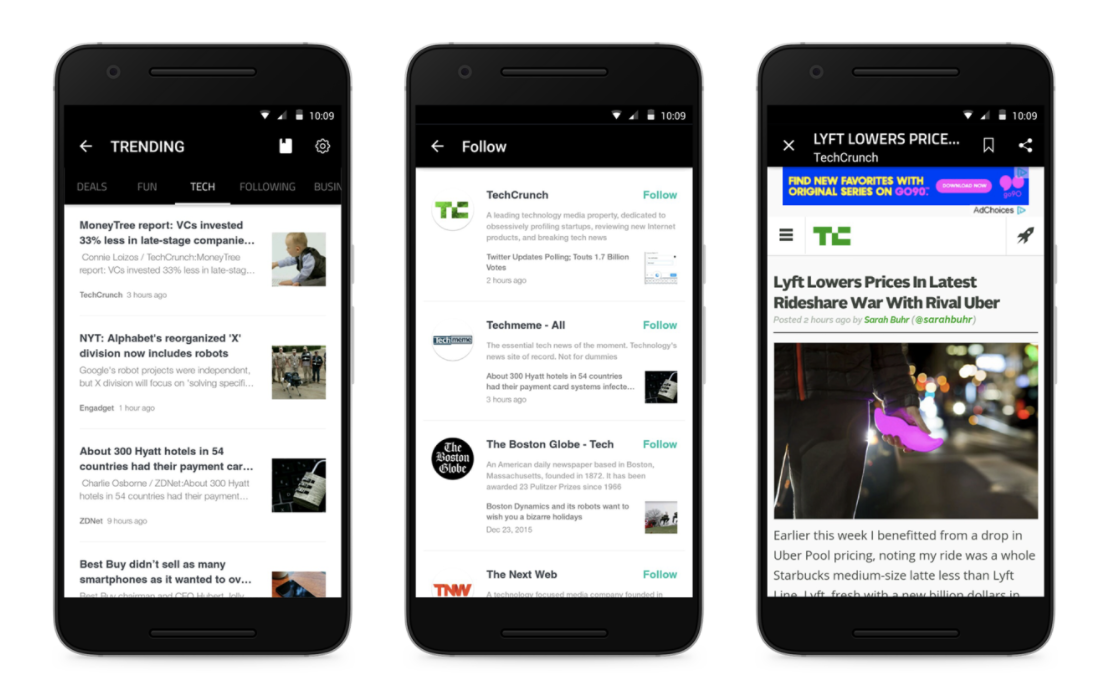
[Image Source: 테크 크런치 2016년 1월 기사, Lockscreen App Slidejoy Gets A Newsy New Feature]
하지만, 그 이후 보편적으로 popular 한 topic 외에도 개개인이 관심 있어할 만한 컨텐츠 제공의 필요성을 느껴 deep learning 을 이용하여 개인화 로직 개발을 시작했습니다. 모든 개인화 로직 개발은 최근에 빠른 adoption 을 보이고 있는 Google 의 Tensorflow 를 이용하였습니다.
4. 모델 설계
1) 데이타 수집: Slidejoy 컨텐츠를 제공함으로써 수집하는 데이타는 크게 다음과 같습니다.
- 유저 아이디, 성별, 나이 등의 기본 유저 데이타
- 카테고리, provider 아이디, 제목, description 등의 컨텐츠 데이타
- 컨텐츠 display 순서, 시간 및 클릭 여부 등 유저 interaction 데이타
Tensorflow 의 training input 으로 사용하기 쉽게 날짜별로 위의 데이타를 tfrecord (참고: https://www.tensorflow.org/api_docs/python/python_io/#tfrecords_format_details) 파일에 저장했습니다. 초기 training 을 위해서 총 3달 분량의 데이타를 사용했습니다.
2) 모델 components: Tensorflow 에서는 먼저 데이타를 담을 tensor (간단하게 vector 로 생각하면 됩니다) 들을 이용하여 데이타의 흐름 (input 부터 back propagation 까지) 을 정의하는 그래프를 만듭니다. 그래프 정의 시에는 모든 tensor 관련 연산은 tensorflow 함수를 이용해야 합니다 (참고:https://www.tensorflow.org/api_docs/python/array_ops/). 일반적으로 쓰이는 numpy 나 list 연산은 그래프에 적용이 안됩니다. 그래프 정의 후에 session 을 시작하여 그래프의 한 operation 에 실제 데이타를 흘려 (flow) 보내면 learning 이 진행됩니다. 그리하여 이름이 “Tensorflow” 인 것이죠. 머신 러닝을 처음 접하면 직관 적이지 않은 개발 방식이라 어색할 수 있지만, underlying 그래프만을 저장/로드/분석을 하기에 상당히 편리한 방식입니다.
- Objective
컨텐츠의 추천 로직은 기본적으로 ordering 을 유저의 취향에 맞게 하는 것이 목표 입니다. 유저의 취향은 여러 방식으로 정의할 수 있지만, 이 프로젝트에서는 유저의 컨텐츠 클릭 여부로 정했습니다. 유저/컨텐츠 정보를 input 으로 하여 neural network 가 최종적으로 유저가 클릭할 확률을 계산 하도록 했습니다.
- Input
일별로 구분된 training data set 을 랜덤하게 섞어서 모델에 feed 할 수 있도록 Tensorflow 에서 제공하는 shuffle_batch 함수를 사용했습니다. 앞에서 언급했듯이 저는 input 파일들을 tfrecord 포맷으로 저장하는데요, binary 포맷이라서 일반 csv/text 파일보다 월등히 빠릅니다. Tensorflow 의 batching 은 queue/dequeue 방식을 사용합니다 (참고: https://www.tensorflow.org/how_tos/reading_data/). 이를 사용하기 위해서는,
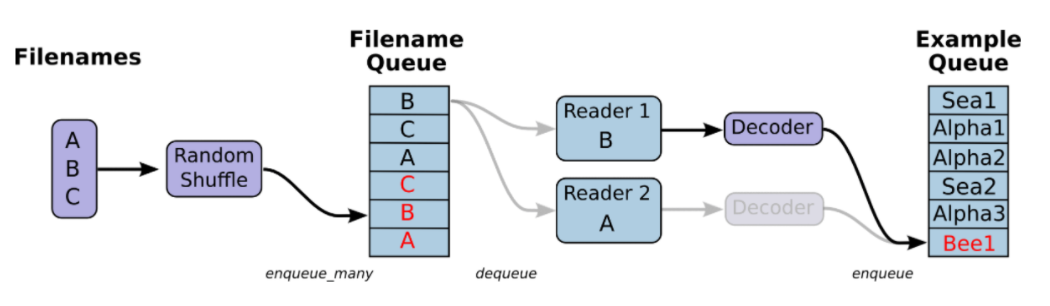
[Image Source: TensorFlow, 'Reading Data']
1. tf.train.string_input_producer 에 필요 파일들을 filename queue 에 추가하고
filename_queue = tf.train.string_input_producer(files)
2. Input producer 에서 dequeue 된 파일들로부터 데이타 포맷 (csv, tfrecord 등) 에 맞는 reader 를 통해서 생성된 example 을 또 queue 에 추가합니다
reader = tf.TFRecordReader()
_, serialized_example = reader.read(filename_queue)
3. 최종적으로 shuffle_batch/batch 를 통해서 queue 에 있는 example 들을 dequeue 하여 실질적으로 데이타를 graph 에 feed 해 줄 수 있습니다.
features = tf.train.shuffle_batch(
tensors=[serialized_example],
batch_size=batch_size,
capacity=capacity,
min_after_dequeue=min_after_dequeue,
)
4. Data feed 는 placeholder 에만 할 수 있습니다. Feed 를 받을 placeholder 들을 그래프 생성시에 define 해주면 됩니다.
# placeholder 들 생성
label = tf.placeholder(tf.int32, [None, ], name='y-input')
...
# queue runner 시작 및 feature 추출
sess = tf.Session()
coord = tf.train.Coordinator()
threads = tf.train.start_queue_runners(sess=sess, coord=coord)
features = sess.run(features)
# Cost/loss 계산을 위해 batch output 을 placeholder 들에 feed
feed_dict = {
label = features[0].values,
...
}
# feature 를 이용해서 cost 계산
sess.run(cost, feed_dict=feed_dict)
만약에 tfrecord 포맷으로 데이타를 write/read 할거라면 tensorflow 가 depend 하고 있는 python based protobuf library 를 C++ based protobuf 로 업데이트 할 것을 강력히 권장합니다. 무려 10 ~ 50배가 빨라집니다 (참고: https://github.com/tensorflow/tensorflow/blob/master/tensorflow/g3doc/get_started/os_setup.md#protobuf-library-related-issues)
- Embedding 처리
Sparse 한 feature (유저 아이디, 컨텐츠 카테고리 아이디, 유저 나이, 시간 등) 는 모두 embedding 처리합니다. Embedding 은 간단히 말해서 sparse 한 데이타를 dense 한 high dimensional vector space 에 프로젝트 해주는 lookup table/matrix 입니다. Embedding matrix 자체를 variable 로 설정하면 neural network 가 learning 을 하면서 weight 들과 함께 embedding matrix 도 업데이트가 되고, 결과적으로 비슷한 feature 들은 vector space 에서 grouping 되는 놀라운 현상이 발생합니다. Tensorflow 에서 embedding lookup 을 위한 함수들 (https://www.tensorflow.org/api_docs/python/nn/embeddings) 이 존재하여 손쉽게 embedding 을 적용시킬 수 있습니다.
embeddings = tf.get_variable(
'embedding',
initializer=tf.random_uniform([size, dimension], -1.0, 1.0)
)
y = tf.nn.embedding_lookup(embeddings, feature)
다만, 컨텐츠의 제목과 description 등의 단어들의 경우에는 variable 이 아니라 pre-trained 된 constant matrix (tf.constant) 를 사용합니다. 단어 embedding 의 경우 Wikipedia, Twitter 등에서 추출한 문서들을 이용하여 만들어진 많은 embedding matrix 들이 존재하고, 새로 embedding 을 training 해야 하는 수고를 덜 수가 있어서, pre-trained 된 embedding 을 사용하였습니다. 구체적으로, Stanford 에서 제공하는 Wikipedia + Gigaword embedding 을 사용하였습니다. Word embedding 의 자세한 methodoloy 는 http://nlp.stanford.edu/projects/glove/ 에 소개 되어 있습니다. 참고 링크를 읽어 보시면 알겠지만, 같은 context 에서 자주 같이 등장하는 단어들은 vector space 에서 가깝게 위치하고, 심지어 간단한 vector 연산도 적용이 됩니다 (v_king - v_queen ~= v_man - v_woman).
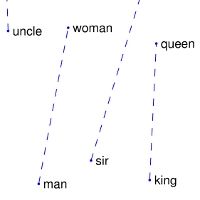
[Image Source: Global Vectors for Word Representation]
- Hidden Layers: 모델에는 크게 두가지 hidden layer 를 사용했습니다.
1. RNN layer 문장 feature (컨텐츠 제목 + description) 에는 RNN 을 적용 시켰습니다. RNN 적용 이전에 주로 image recognition 에 쓰이는 CNN 과 단방향 RNN 으로 실험을 해보았지만, 쌍방향 (bi-directional) RNN 의 효율이 가장 높았습니다 (하나의 layer 만을 사용했습니다). RNN cell 로는 기본 cell 의 vanishing/exploding gradient 문제를 보완한 LSTM (long short term memory) cell 을 사용했습니다 (참고: http://colah.github.io/posts/2015-08-Understanding-LSTMs/) Tensorflow 에서 RNN 은 크게 두가지 버전이 있습니다: 기본 (static) RNN 과 dynamic RNN. Dynamic RNN 은 그래프를 session 을 execute 할 때 만들어서 초기 그래프 생성 시간이 기본 RNN 보다 월등히 빠릅니다. 다만 documentation (https://github.com/tensorflow/tensorflow/blob/master/tensorflow/python/ops/rnn.py) 을 읽어 보시면 알겠지만, static RNN 은 output 을 계산 할 때 sequence length 에 맞춰서 모든 time step 을 계산 하지 않고 일찍 멈춥니다. 가령 컨텐츠 제목을 담은 embedded matrix 의 총 dimension 이 100 이라고 했을 때, 총 소요되는 rnn timestep 도 일반적으로 100 입니다. 그러나 sequence length 를 5로 지정하면 (컨텐츠의 제목이 짧아서) 5 번째 timestep 까지만 계산하고 early stop 을 합니다 (thus, saving number of computations).
이와 다르게, dynamic rnn 에서는 early stop 을 안하고 지정된 sequence length 이후의 output 은 0 으로 padding 을 해줍니다. 두 함수의 input specification 도 다르기 때문에 유의 하시기 바랍니다.
저는 초기 그래프 생성 시간이 그리 길지 않아서 그냥 static RNN 을 사용했습니다.
def lstm_cell(layer_size):
return tf.nn.rnn_cell.LSTMCell(
num_units=layer_size,
forget_bias=1.0,
state_is_tuple=True
)
outputs, final_state_fw, final_state_bw = tf.nn.bidirectional_rnn(
cell_fw=lstm_cell(layer_size),
cell_bw=lstm_cell(layer_size),
inputs=input,
dtype=tf.float32,
sequence_length=sequence_length
)
2. Feed forward layer 위 RNN 에서의 output 과 embedding 된 input 들을 모두 concat 한다음에 multi-layer network 을 통하여 마지막 dimension 2 (click/no-click) 짜리 output 을 생성 하였습니다. 저는 Xavier weight initialization 을 사용했는데요, input 의 variance 를 유지시켜줘서 weight 때문에 input 이 소멸되거나 너무 증폭 되는 현상을 방지해줍니다 (참고: http://jmlr.org/proceedings/papers/v9/glorot10a/glorot10a.pdf). Layer 가 많은 network 에 아주 유용한 weight initialization 방식이죠.
- Cost Function
Neural network 의 최종 output dimension 을 2 로 하고, 확률 distribution 으로 바꾸기 위해서 output 의 softmax 를 계산을 합니다. Softmax 는 임의의 vector 값들을 확률로 바꾸기 위해서 가장 일반적으로 쓰이는 transform 방식이고, 식은 다음과 같습니다 (output vector z 로부터 계산된 c category 의 확률).
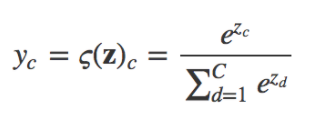
이 확률과 실제 클릭 여부 데이타 (label) 의 cross entropy 를 통하여 loss/cost 를 계산했습니다. Cross entropy 의 수식은 다음과 같습니다 (y 는 label, a 는 확률).
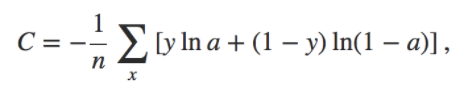
Mean squared error (y - a)^2 대신에 cross entropy 를 cost function 으로 사용한 이유는 확률이 0 이나 1 에 근접할 때에 gradient 가 점점 줄어드는 (결국 learning 이 느려지는) 문제를 보완하기 위해서입니다. 그리하여 일반적으로 categorization 을 다룰 때 주로 cross entropy 를 씁니다 (참고: http://neuralnetworksanddeeplearning.com/chap3.html).
이 전 과정 (softmax + cross entropy) 또한 Tensorflow 에서 softmax_cross_entropy_with_logits 라는 하나의 함수로 정의 되어 있어서 편합니다 (참고: https://www.tensorflow.org/api_docs/python/nn/classification)
3) Evaluation 및 Monitoring Training 데이타의 loss 값을 통하여 모델의 convergence 를 판단할 수 있지만, 모델의 실질적인 효과를 이해하기 위해서는 더 직관적인 metric 이 필요합니다. 일반적으로 데이타 categorization 의 효과를 판단할 때는 확률 (output 의 softmax 결과) 이 가장 높은 category 와 실제 label 을 비교하여 accuracy 를 계산합니다. 예를 들어, test 또는 evaluation data set 의 결과가 아래와 같다면, 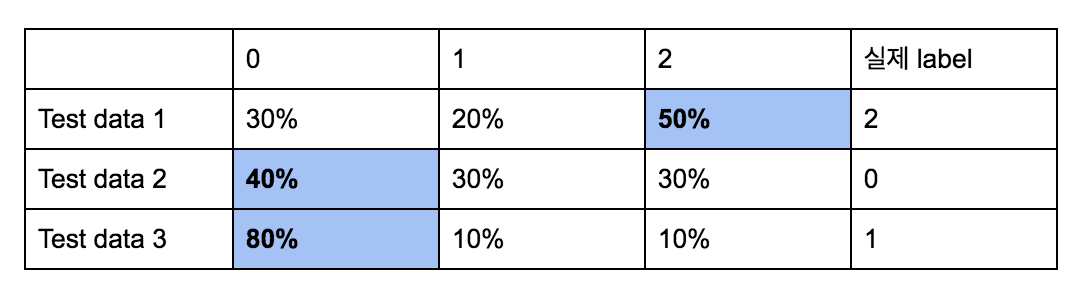 Accuracy 는 66.6% 가 될 것입니다. 하지만 컨텐츠의 클릭 같은 경우에는 대부분 (90% 이상) 의 데이타가 0 (no click) 이기 때문에 이와 같은 accuracy metric 으로는 모델의 효과를 판단하기 어렵습니다. 이와 같은 데이타 bias 와 관계없이 클릭할 확률과 클릭 여부 데이타만을 가지고 모델의 효과를 판단하기 위해서 AUC (area under curve) 값을 사용했습니다. 자세한 AUC 의 정의는 http://www.dataschool.io/roc-curves-and-auc-explained/ 를 참고하시면 됩니다. 간단히 소개하자면,
Accuracy 는 66.6% 가 될 것입니다. 하지만 컨텐츠의 클릭 같은 경우에는 대부분 (90% 이상) 의 데이타가 0 (no click) 이기 때문에 이와 같은 accuracy metric 으로는 모델의 효과를 판단하기 어렵습니다. 이와 같은 데이타 bias 와 관계없이 클릭할 확률과 클릭 여부 데이타만을 가지고 모델의 효과를 판단하기 위해서 AUC (area under curve) 값을 사용했습니다. 자세한 AUC 의 정의는 http://www.dataschool.io/roc-curves-and-auc-explained/ 를 참고하시면 됩니다. 간단히 소개하자면,
- 다양한 threshold value 를 가지고 true positive rate 대비 false positive rate 를 그래프에 plot 한 후 그 그래프의 넓이를 구합니다
- 결과적으로, 계산된 클릭 확률 (p_1, p_2, p_3, ... , p_n. 0 <= p_x <= 1) 들과 그에 따른 category (c_1, c_2, c_3, ... , c_n. c_x = 1 or 0) 들이 있고
- 모든 (p_x, p_y) tuple 에 대해서 p_x > p_y 일 때 c_x > c_y 이면 AUC 값이 1 이 됩니다.
- 반대로, 모든 (p_x, p_y) tuple 에 대해서 p_x > p_y 일 때 c_x < c_y 라면 AUC 값은 0 이 됩니다
- 일반적으로 확률 값이 랜덤이라면 AUC 는 ~0.5 이기 때문에, 0.5 이상이라면 계산된 확률 값이 의미가 있다는 것을 알 수 있습니다
간편한 AUC 계산을 위해서 sklearn 에서 제공하는 함수를 사용했습니다 (참고: http://scikit-learn.org/stable/modules/generated/sklearn.metrics.roc_auc_score.html) 4) Tuning
- Overfit
보통 같은 training data 를 반복해서 training 하다보면 training cost 는 계속 감소하지만 evaluation/test cost 는 줄지 않는 경우가 많습니다. Training data 에 모델이 overfit 되서 그런건데요, 이를 보완하기 위한 방안들이 몇가지 있습니다.
데이타: 간단하며서도 가장 효과적인 방법입니다! Training 데이타량을 늘리는 겁니다.
L2 regularization: Weight 가 너무 커지는 것을 방지합니다. High level 로 보자면, weight 가 커지면 input 에 따라서 output 의 swing 도 커지기 때문에 (예를 들어, 다양한 input 의 noise 에 model 이 fitting 될 수 있어서), 일반적인 input 을 위한 model 을 만들기 어려워집니다.
# weight 를 이용한 l2 regularization
for weight in weights:
cost += l2_reg_lambda * tf.nn.l2_loss(weight)
Dropout: 간단하며서도 가장 효과적인 방법입니다! Training 데이타량을 늘리는 겁니다.
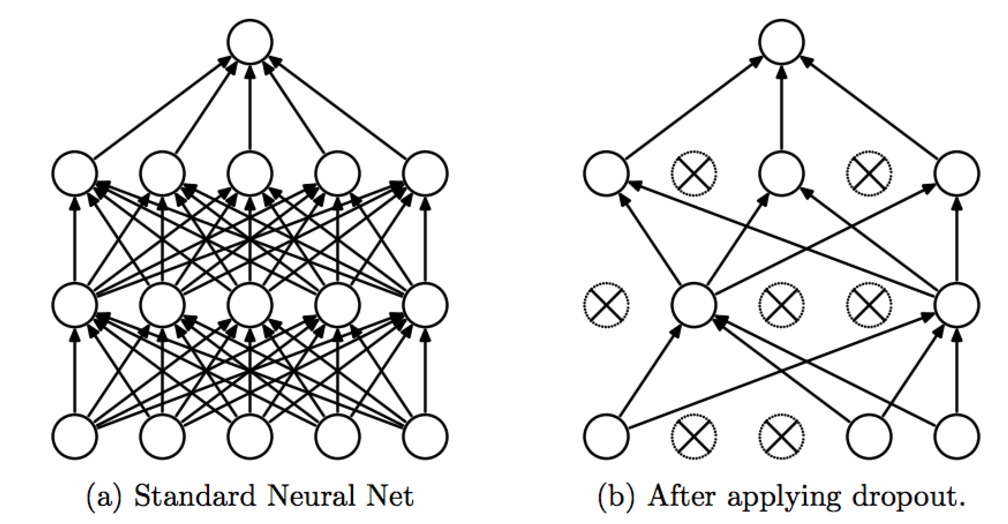
[Image Source: A simple way to prevent neural networks from overfitting]
위의 참고 그럼처럼 일정 확률로 node 를 없앤 채로 training 을 시킵니다. High level 로 보자면, 매번 랜덤한 다른 set 의 node 를 가지고 모델을 training 하기 때문에 여러개의 model 을 가지고 training 한 후 average 하는 효과를 가져옵니다. 결국 regularization 과 비슷하게 좀 더 일반적인 model 을 만들 수가 있습니다.
- Tensorboard
모델 설계 후 여러가지 방법으로 training 과정을 monitor 할 수 있지만, 가장 간편한 방식이 tensorflow 에서 제공하는 tensorboard 입니다. 매 iteration weight/bias 값의 변화 추이, accuracy 및 cost 의 변화 추이 등을 모니터 할 수 있습니다. 개인적으로 많은 도움이 된 부분은 graph visualization 입니다. 데이타의 dimension, 흐름, training 되고 있는 variable 등이 잘 정리 되어 있습니다 (참고: https://www.tensorflow.org/versions/master/how_tos/graph_viz/)
Tensorboard 를 이용하기 위해서는:
그래프 정의시 필요한 scalar 값마다 summary 기록 후 최종 merge
tf.scalar_summary(‘cost’, cost)
...
merged = tf.merge_all_summaries()
Session 생성 후 summary writer 정의
Writer = tf.train.SummaryWriter([directory], sess.graph)
매 iteration step 마다 summary 기록 추출
summary, ... = sess.run([merged, ... ], feed_dict=...)
writer.add_summary(summary, step)
- Parameter optimization
Tuning 가능한 parameter 들이 많습니다: learning rate, batch size, dropout rate, l2 regularization rate 등등. 사실 이 parameter 들을 조정 하는 공식은 없습니다. 다양한 변화를 주면서 얼마나 빨리 converge 하는지, AUC 값은 어떤지, 등을 꾸준히 monitor 하면서 optimal 한 값들을 찾아 나가야 합니다: It is more art than science.
위의 모델 설계 과정을 거친 후 모델을 3달 분량의 데이타를 이용하여 총 100 epoch 정도 training 시켰습니다. Evaluation 데이타는 한 유저의 1주일 간의 컨텐츠 소비 데이타를 가지고 생성하였습니다. 유저마다 클릭 확률이 다르기 때문에 여러 유저가 섞인 데이타로 결과를 test 하지 않았습니다. 물론 evaluation data 는 training data 에 포함이 안 되었습니다. Training 끝 무렵엔 evaluation data set 에서 ~0.7 의 AUC 값이 consistent 하게 나왔습니다. 만족스러운 AUC 값이 나온 후 이 모델을 이용해서 실제 유저들에게 개인화된 컨텐츠를 제공하여 클릭률 증가를 살펴 보았습니다.
5. 시스템
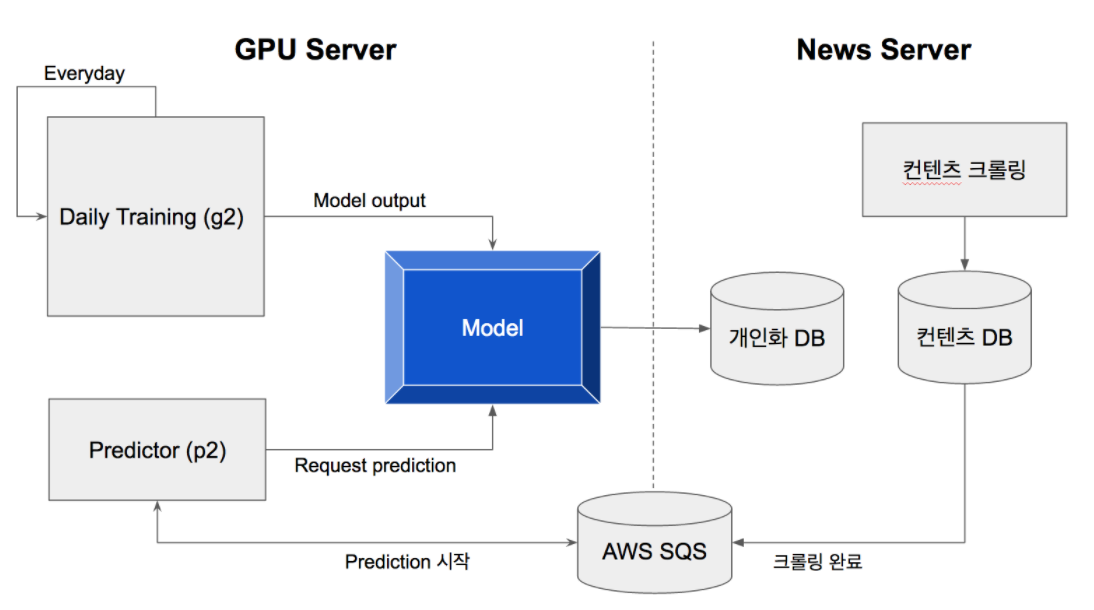 Slidejoy 에 이 모델을 적용 시키기 위해 크게 두 component 가 있습니다: Daily training 과 prediction.
Slidejoy 에 이 모델을 적용 시키기 위해 크게 두 component 가 있습니다: Daily training 과 prediction.
-
Daily training 은 지속적으로 진행됩니다. 다만 매일 가장 최근 60일 데이타만을 이용해서 training 합니다. 하루의 training 이 끝나면 모델 parameter 들을 p2 instance 로 옮겼습니다. 모든 training 데이타를 이용해서 다시 training 하는건 시간도 많이 소요 될 뿐 아니라, 유저의 성향이 바뀔 수도 있기 때문입니다.
Training 을 위해서 AWS 의 g2.2xlarge instance 를 사용하였습니다. AWS 에서는 크게 두가지 GPU 서버를 제공하는데요 (g2, p2), 차이점이라면 p2 는 ~40% 정도 더 비싼 대신에 더 강력한 (3x GPU memory, 3x processing cores, 등등) GPU 를 사용한다는 것입니다. 이 프로젝트를 진행할 때 한 iteration 처리 속도는 p2.xlarge 가 g2.2xlarge 에 비해서 ~40% 가량 빨랐습니다. -
Prediction 은 time sensitive 하기 때문에 조금 더 빠른 p2.xlarge instance 를 사용했습니다. 컨텐츠 수집이 끝나면 우선 AWS SQS 에 완료 메세지를 남겼습니다. Prediction instance 에서 이 메세지를 받으면 3,000 명의 테스트 유저들마다 매 시간 10,000 개 이상의 컨텐츠들의 확률을 계산하고 결과를 Redis 에 남겼습니다.
6. 결과
모델의 효과를 파악하기 위해서 A/B 테스트를 진행했는데요, Slidejoy 컨텐츠의 active user 3,000 명을 추출하여 크게 3 그룹으로 나눴습니다.
- 그룹 A: 랜덤한 컨텐츠가 보여집니다
- 그룹 B: Unigram TF-IDF 방식으로 기사들을 묶어서 가장 popular 한 토픽 순서대로 모든 유저들에게 일괄적으로 같은 컨텐츠가 보여집니다
- 그룹 C: Neural network 에서 계산된 확률이 높은 순서대로 유저별로 개인화된 컨텐츠가 보여집니다
2 주일동안 테스트를 해서 충분한양의 impression/click 을 확보한 후 결과를 살펴보니 그룹 B 가 A 보다 클릭 비율이 22% 높았고, 그룹 C 가 B 보다 25% 높았습니다 (statistically significant). 간단한 모델이지만 실질적인 application 에서 의미있는 결과를 도출 할 수 있었습니다.
7. 글을 마치며
이 프로젝트는 컨텐츠의 개인화를 위하여 시작을 했지만, 버즈빌에서는 neural network 기술을 광고 타게팅, 매출 증대, operation 자동화, 마케팅 등의 다양한 분야에 빠르게 적용시킬 예정입니다. 블로그 서두에 언급했듯이, neural network 의 장점은 각 분야에 specialized 된 feature 들을 고민할 필요가 없어서 하나의 generalized 모델을 여러 목적으로 사용하는 것이 가능합니다. 그래서 저희의 next step 으로는 다양한 형태의 data 를 input 받아서 다양한 형태의 prediction 을 할 수 있는 generalized 된 모델과 시스템을 만드는 것입니다. 필요에 따라서는 이 모델 위에 마치 레고처럼 특수한 layer 를 추가하거나 필요 없는 layer 는 생략 할 수 도 있겠지요. 위에 설명한 추천 로직은 앞에서도 언급했듯이 상당히 간단한? 모델입니다. 이와 비교해서 최근에 neural network 로 바꿔서 좋은 평가를 받고 있는 Google translate 의 모델을 보면 경외감이 듭니다 (참고: https://arxiv.org/abs/1609.08144) 그만큼 저희의 장기적인 목표를 위해서는 개선 할 수 있는 부분이 많습니다.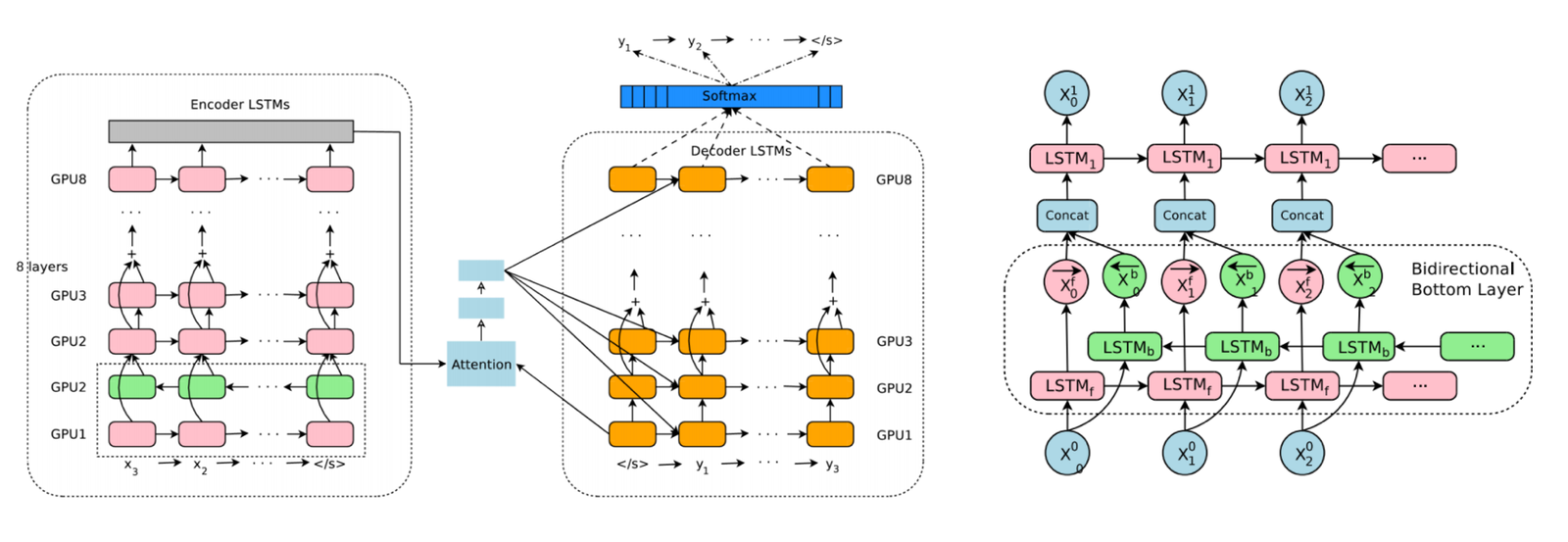
[Image Source: Google's Neural Machine Translation System]
1.병렬 구조
위 디자인에서 보면 알겠지만 (참고 문서에서도 설명이 되어있고), 단방향 보다 효과가 좋은 bi directional RNN 을 한 layer 만 사용한 이유는 model parallelism 을 극대화하기 위해서 입니다. 예를 들어, 한 단방향 RNN layer 의 첫번째 time slot 계산이 끝나면 바로 그 다음 RNN 의 첫번째 time slot 을 계산 할 수 있기 때문입니다 (쌍방향일 경우 모든 timeslot 이 계산 되어야 다음 layer 를 계산 할 수 있습니다). 결국 여러 gpu 를 사용해서 여러 layer RNN 을 병렬 구조로 계산을 할 수 가 있게 됩니다.
Model parallelism 외에도 중요한 것이 data parallelism 입니다. 여러 개의 모델을 동시에 돌려서 하나의 shared model parameter 들을 업데이트 하도록 하는 방식입니다.
위에서도 언급했듯이 수많은 실험을 통해서만 parameter 들의 optimal 한 값과, 중요한 feature 들을 찾아 낼 수 있습니다. 그러기 위해서는 최대한 많은 실험을 빠르게 돌려야 하는데, 이러한 병렬 구조들이 가장 optimal 한 모델을 구현하는데 큰 도움이 될 것 입니다.
2. Automated tuning
실험 (모델에서 feature 를 빼고 metric 들을 monitor 하면서) 을 통해서 어떠한 feature 가 중요한지 또 중요하지 않은지를 판단해서 중요한 feature 들을 더 emphasize 하는 과정이 필요 합니다. 예를 들어 컨텐츠의 제목의 유무가 AUC 값의 증가에 큰 영향을 미친다면, 컨텐츠 제목 RNN 의 복잡도를 늘려서 모델이 제목의 context 를 더 잘 이해할 수 있도록 보완 할 수 있습니다. 또한, 앞서 언급했던 learning rate, regularization rate, dropout rate 등등의 다양한 parameter 들을 실험을 통해서 optimize 를 해야 하는데요. 이러한 과정의 많은 부분들을 자동화 하는 시스템을 설계 하는 것이 generalized model 을 만드는 데에 key 가 될 것입니다.
3. Reinforcement Learning
Supervised learning 이외에도 neural network 를 이용한 reinforcement learning 모델이 많이 공개 되었습니다 (DQN, A3C 등등). 주로 state space 가 작으면서 well-defined 되어 있는 게임에 많이 적용이 되었는데, 광고/컨텐츠 allocation policy 에도 효과적으로 사용될 수 있을 것 같습니다.
4. TFlearn (http://tflearn.org/)
저는 이 프로젝트를 진행하면서 tensorflow 에서 제공하는 함수들을 사용했지만, 사실 더 간단한 library 가 있습니다. 바로 tflearn 인데요, 여러 반복적인 graph 생성 operation 들 (placeholder 생성, weight/bias 정의, regularization, dropout, 등등) 을 high level 함수들로 묶은 library 입니다.
모델 구현을 하면서 귀찮고 또 실수도 잦은 부분이 tensor 들의 dimension 지정하고, 필요에 따라서 reshape 하는 것인데, TFlearn 에서는 이러한 반복적이고 소모적인 operation 들을 깔끔하게 해결 해 줍니다. 예를 들어, 아래 두 줄의 코드로 weight, bias, activation, regularization, dropout 이 전부 포함된 feed forward layer 를 생성 할 수 있습니다.
dense1 = tflearn.fully_connected(
input_layer,
64,
activation='tanh',
regularizer='L2',
weight_decay=0.001
)
dropout1 = tflearn.dropout(dense1, 0.8)
성능과 정확성등을 더 알아봐야 하지만, 실수를 줄이고, tensorflow 를 처음 접하거나 간단한 모델을 구현 하는 데에는 안성맞춤 인 것 같습니다. 앞으로, 딥러닝에 기반한 다양한 neural network 기술 연구가 어떻게 버즈빌의 서비스를 변화시킬 지 개인적으로도 기대가 큽니다.

