
-
 Abel Yoon
Abel Yoon
- 18 Apr, 2024
데이터 엔지니어의 Airflow 데이터 파이프라인 CI 테스트 개선기
들어가며 안녕하세요, 버즈빌 데이터 엔지니어 Abel 입니다. 이번 포스팅에서는 데이터 파이프라인 CI 테스트에 소요되는 시간을 어떻게 7분대에서 3분대로 개선하였는지에 대해 소개하려 합니다. 배경 이전에 버즈빌의 데이터 플랫폼 팀에서 ‘셀프 서빙 데이터 …
Read Article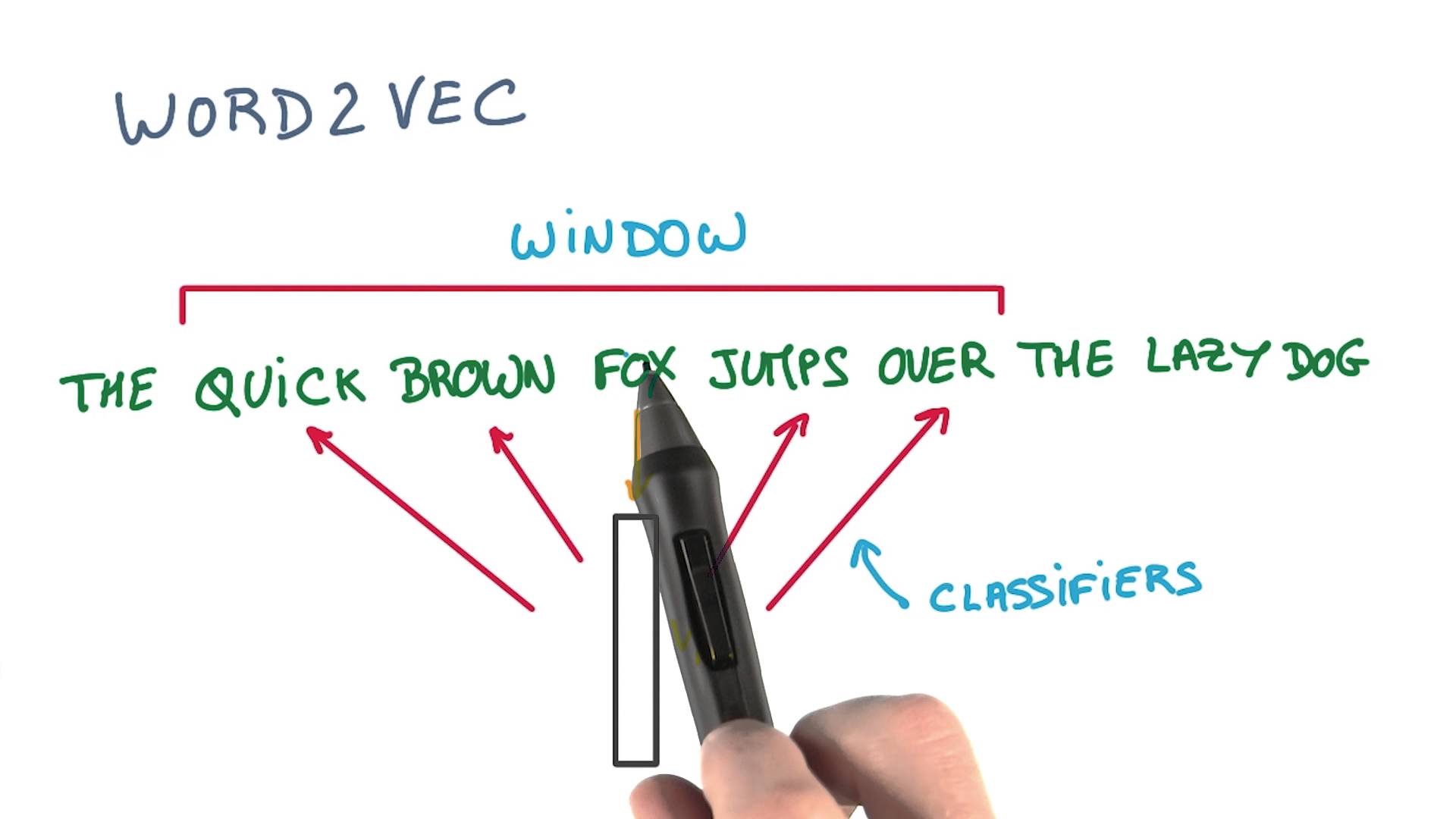
버즈빌의 대표 프로덕트인 허니스크린은 사용자들에게 포인트를 적립할 수 있는 광고 뿐 만 아니라 다양한 컨텐츠를 제공합니다. SNS에서 핫한 글들, 뉴스 등을 볼 수 있기에 사용자들은 SNS, 포털 앱을 실행하지 않아도 잠금화면에서 손쉽게 컨텐츠를 소비할 수 있습니다. 이처럼 허니스크린에서는 잠금화면에서의 컨텐츠 소비를 통해 더 개선된 사용자 경험을 제공하기에 질 좋은 컨텐츠를 적절한 사용자들에게 제공해주는 것은 매우 중요한 일입니다. 버즈빌은 효율적인 컨텐츠 추천을 위해 머신러닝을 이용해 컨텐츠를 비슷한 것 끼리 분류하는 클러스터링 작업에 집중하고 있습니다. 클러스터링 작업은 다음과 같은 2가지 접근법으로 진행되고 있습니다.
위와 같은 2가지 접근법으로 버즈빌에서는 다양한 머신러닝 기법을 이용해 문제를 해결하기 위해 노력하고 있습니다. 보다 효율적인 컨텐츠 클러스터링 방법을 만들기 위해 자연어처리(Natural Language Processing) 기법 중 Count-base method 인 Latent Dirichlet allocation(LDA), TF-IDF 등 다양한 방법을 시도하고 있습니다. 그 중에서도 가장 이용하기 쉽고, 좋은 결과가 나왔던 word2vec 방법에 대해 소개해드리고 버즈빌에서 이를 컨텐츠 클러스터링에 어떻게 활용하고 있는 지 소개해드리고자 합니다.
word2vec 은 2013년 Mikolov 등 구글 엔지니어들이 제안한 자연어처리 방식으로 단어를 vector space에 embedding 하고 벡터로 단어를 표현하는 것입니다. 이 방식을 통해 자연어 처리 분야에서 비약적인 정밀도 향상을 가능하게 하였습니다. word2vec의 알고리즘은 Neural Network에 같이 출연하는 단어들을 의미상 연관된 단어라고 가정하고 vector space 에서 두 단어 사이의 거리를 점차 줄이는 알고리즘입니다. 방법은 간단하지만 이 Neural Network를 학습시키는 데에는 많은 계산이 필요한데 word2vec은 최적화가 매우 잘 되어 있기에 빠른 시간 내에 학습을 시킬 수 있습니다. 구체적인 최적화 방법은 수학적으로 복잡하기에 여기서 언급하지 않고 궁금하신 분들은 아래 레퍼런스의 논문을 참고해주시기 바랍니다. word2vec의 흥미로운 점은 단어 벡터들끼리의 연산이 의미있는 결과를 가져온다는 점입니다. word2vec으로 학습시킨 벡터들을 연산하면 다음과 같은 결과가 나옵니다.
vector('Paris') - vector('France') + vector('Italy') = vector('Rome')
vector('king') - vector('man') + vector('woman') = vector('queen')
이처럼 word2vec 은 단순한 단어의 벡터 표현이 아니라 단어의 추론, 복잡한 개념까지도 표현이 가능합니다. word2vec 모델의 구조는 CBOW(Continuous Bag of Words), Continuous Skip-Gram 2 가지 방식이 있습니다. 아래의 예시를 통해 2가지 방식의 차이점을 쉽게 알 수 있습니다.
문장 : When I find myself in times of trouble mother Mary comes to me
CBOW Input : [When, I, find], [I, find, myself], [myself, in, times], ...
Skip-Gram Input : [When, I, find], [When, I, myself], [When, find, myself], ...
위의 예시 처럼 CBOW 방식은 한 문장에서 연속적인 단어들을 입력값으로 집어 넣는 것으로 문맥을 통해 단어를 예측할 수 있는 모델입니다. Skip-Gram은 이와 반대로 한 문장 안에서 발생할 수 있는 단어 모음(Bag of words)를 모두 입력값으로 취하기에 단어를 통해 문맥을 예측할 수 있는 모델입니다. CBOW는 입력값이 Skip-Gram보다 적기 때문에 학습 시간이 더 짧고 잦은 빈도로 등장하는 단어에 대해 정확한 결과를 도출해낼 수 있습니다. Skip-Gram은 학습 시간이 더 길지만 작은 데이터셋에 대해 효율적이고 자주 등장하지 않는 단어에 대해 더 높은 정확도를 갖습니다.
위의 내용을 요약하자면 word2vec은 한 문장 내에서 단어의 등장 빈도 데이터를 바탕으로 이를 단어를 벡터 스페이스에 embedding 하는 작업입니다. neural network를 통해 각 단어가 같이 등장한 빈도가 높으면 두 단어 벡터의 거리를 가깝게 하고, 빈도가 낮으면 두 닺어 벡터의 거리를 멀게함을 통해 단어벡터를 만드는 것입니다. 저는 이를 허니스크린 유저들의 컨텐츠 클릭 히스토리에 적용시키면 컨텐츠들을 효율적으로 클러스터링할 수 있을 것이라 생각했습니다. “비슷한 컨텐츠는 같이 클릭한 사람이 많은 컨텐츠이다"라고 가정을 한다면, word2vec을 통해 컨텐츠간 유사도를 정의할 수 있지 않을까 생각했습니다. 한 유저가 클릭한 컨텐츠 ID 이력을 1개의 문장이라고 생각하고, 컨텐츠 ID를 각각의 단어라고 생각한다면 위의 가설을 기반으로 word2vec을 통해 컨텐츠를 vector space에 embedding 해서 유사한 컨텐츠들 끼리 클러스터링 할 수 있지 않을까 생각했습니다. word2vec은 여러 개의 단어로 이루어진 문장(sentence)들을 입력하고 학습을 진행하는데 아래와 같이 캠페인 id들로 이루어진 문장을 학습시켰습니다.
유저 1 : {캠페인 ID | 유저 1이 클릭한 캠페인 ID} -> 문장 1
유저 2 : {캠페인 ID | 유저 2이 클릭한 캠페인 ID} -> 문장 2
...
유저 380만명에 대해 위와 같은 380만개의 문장들을 만들었습니다. 그리고 유저가 클릭한 컨텐츠의 시간 순서에 따라 결과값이 영향을 받지 않게 하기 위해 컨텐츠 ID 순서를 임의로 섞어주었으며, 우연 오차를 방지하기 위해 임의로 섞은 10개의 문장들을 학습시켰습니다. 그리고 추가적으로 모델의 검증에 사용할 라벨데이터를 학습시켰습니다. ‘게임’, ‘웹툰’, ‘여행’, ‘연애’ 등의 태그를 몇몇 컨텐츠에 달았고 neural network에 다음과 같은 문장으로 학습시켰습니다.
['웹툰', 컨텐츠ID1, '웹툰', 컨텐츠ID2] ...
총 문장 (3800만 + 알파)개에 대해서 학습시켰고 word2vec 모델은 파이썬 gensim 라이브러리에 있는 모델을 이용했습니다. 학습시간은 2013 맥북 프로 13인치에서 약 2시간 30분이 소요되었습니다.
컨텐츠간 유사도는 컨텐츠 벡터간 cosine similarity로 정의했습니다. 두 벡터의 내적을 통해 두 벡터간 코사인 값을 계산하고 이를 유사도라고 정의했습니다. 즉 동일한 컨텐츠에 대해서는 1, 정 반대의 컨텐츠에 대해서는 -1 유사도를 갖습니다. 특정 컨텐츠는 학습된 모델에서 유사하다고 판단한 컨텐츠들과 실제로 유사했습니다. 가장 유사한 컨텐츠의 유사도가 0.95 이상인 경우 해당 컨텐츠와 유사도가 큰 컨텐츠들은 모두 같은 태그에 속했다고 볼 수 있었습니다. 아래는 실제 학습한 모델을 기반으로 얻어낸 결과로 한 컨텐츠와 가장 가까운 10개의 컨텐츠를 나타낸 것입니다. 아래의 컨텐츠는 가장 유사한 컨텐츠의 유사도가 0.95 이상인 컨텐츠입니다.
컨텐츠
- 역대급 미모 자랑하는 여자 아이돌
유사 컨텐츠
1) 현아를 실제로 보면 이런 느낌이다
2) 마리텔 양정원의 사적인 필라테스
3) 어제 마리텔 생방하고 남초싸이트 뒤집은 양정원
4) 컴백 트와이스 쇼케이스 사진 9장
5) 꼬치 여신이 나타났다며 SNS서 확산되고 있는 사진
6) 게임광고에 처음 등장해 색다른 매력 뽐내는 I.O.I.
7) 남취향저격 귀염심쿵 여돌짤모음
8) 태양의 후예 이후 가장 덕본 스타 5명?
9) 아버지 당선에 큰 영향을 끼친 그녀의 미모
10) 슈가맨서 승리 거둔 완전체 I.O.I.의 '엉덩이'
‘역대급 미모 자랑하는 여자 아이돌’ 컨텐츠와 관련된 컨텐츠들은 유사도가 0.95 이상으로 매우 높았으며 이들 또한 여자 연예인 관련 컨텐츠였습니다. 이러한 컨텐츠에 대해서는 유사 컨텐츠 정확도가 95% 이상이었습니다.. 아래의 컨텐츠는 가장 유사한 컨텐츠의 유사도가 0.95보다 작고 0.90 이상인 컨텐츠입니다.
컨텐츠
- 오마이뉴스_목사 꿈꾸던 신학생? 피해자에게도 꿈이 있었다
유사 컨텐츠
1) TV데일리_성폭행 논란 유상무 '코빅' 통편집 '병풍 굴욕'
2) 인사이트 아트&컬처_전쟁을 하지 말아야 하는 이유
3) Insight_학생수 3명 부족해 폐교 위기 인천봉화초등학교
4) Insight_강남역 살인 사건에 프로레슬러 김남훈이 남긴 글
5) Insight_유상무 성폭행 신고 여성 국선 변호사 선임 신청했다
6) HuffPost_이제 학교폭력 가해자에 예외는 없다
7) 스낵_강남역 살인 '묻지마 VS 여혐' 당신의 생각은?
8) 스낵_이세돌 프로기사회 돌연 탈퇴! 불합리한 관행 탓
9) Insight_유럽 시골마을 떠오르는 강원도 원주 풍경
이 컨텐츠들은 내용 간 큰 유사성은 없지만 전체적으로 뉴스라는 범주에 속한다고 볼 수 있었습니다. 다음은 제일 유사한 컨텐츠 유사도가 0.90 미만인 컨텐츠 입니다.
컨텐츠
- piki_장기자랑 시간 남학생들이 많이 불렀던 단골 곡 10
유사 컨텐츠
1) piki_동성애자들이 투쟁한 전대미문의 사건
2) piki_한때 전국을 장악했던 홈쇼핑 상품 BEST10
3) piki_1997년 전설의 H.O.T 모든 게 '최초'였던 그들
4) piki_자도자도 피곤하다면 배게 불면을 의심하라!
5) piki_평소 연락 없던 사람에게 받으면 언짢은 카톡 7
6) mango_내 위의 한계를 테스트 해보겠어! 전주 먹방여행 코스
7) piki_레전드 유행어를 남긴 추억의 TV광고 10편
8) piki_시급 2만 원을 준다는 기묘한 홀서빙 알바
9) mango_ 4월에 꼭 가봐야 할 맛집 리스트 30곳
제일 유사한 컨텐츠 유사도가 0.90 미만이지만 대체적으로 피키캐스트 글이라는 공통점이 있었습니다. 그러나 맛집, 여행 관련 컨텐츠가 추천되었기 때문에 유사도가 0.80 미만이면 같은 태그에 속한다고 볼 수 없었습니다. 이처럼 컨텐츠 벡터간 유사도가 감소함에 따라서 컨텐츠들이 같은 범주에 속한다고 판단하기가 어려움을 알 수 있었습니다.
특정 캠페인에 태그를 달아서 학습시킨 데이터 기반으로 모델의 정확도를 테스트하였습니다. 다음은 웹툰과 미용 태그에 가장 가까운 컨텐츠들 목록입니다.
웹툰 태그
- 배틀코믹스_너의 목표는 이놈들보다 빨리 나를 처리하는 것이다
- 배틀코믹스_혹시 운동은 아니겠지요?
- 배틀코믹스_그녀의 롤 실력만 믿고 가는거야!
- 배틀코믹스_아빠는 너희 얼굴만 보면 다 견딜 수 있었단다
- 배틀코믹스_돈도 없는데 무슨 히어로야!
- SNAC_충무공 이순신 장군은 왜 일본도를 들었을까?
- 배틀코믹스_난 그런 흔해빠진 상대가 아니라고
- 뉴스1_안녕 멍뭉아 냐옹아 만나서 반가워 헤헷 :)
- 배틀코믹스_럼블이 수영장에서 봉변당한 트리스타나를 구할수 있을까?
- 배틀코믹스_제 안의 흑염룡을 깨워버렸어요!!
미용 태그
- piki_아이라인을 좀 더 예쁘게 그리기 위한 소소한 팁 7
- HuffPost_블랙헤드는 무엇이며 대체 어떻게 없애나?
- Insight_나쁜 남자한테 끌리는 여성은 성적 판타지’ 있다
- piki_블랙헤드 제거를 위한 최상의 방법 찾기
- 대학내일_피부 뒤집어졌을 때가장 먼저 해야 할 일 8
- wikitree_씨스타 소유가 요즘 한다는 '다이어트' 비법
- HuffPost_생리로 당신의 건강을 확인하는 법 5가지
- 타임보드_일주일만에 출렁이는 팔뚝살 빼는법!
웹툰 태그의 정확도는 약 80퍼센트, 미용 태그의 정확도는 약 75퍼센트로 나왔습니다. 여기서 해당 태그와 관련이 없는 컨텐츠들에 대해 분석을 해보니 클릭 수가 매우 많거나 매우 적은 컨텐츠들이었습니다. 클릭수가 매우 많은 컨텐츠들은 학습 과정에서 모든 컨텐츠들과 가까워질 수 있기 때문에 이러한 오차가 발생했고, 클릭수가 매우 적은 컨텐츠들은 학습 데이터가 부족하기 때문에 오차가 발생했다고 볼 수 있습니다.
CTR(Click-through rate)이 높은 컨텐츠와 유사한 컨텐츠들은 다음과 같다.
wikitree_씨스타 소유가 요즘 한다는 '다이어트' 비법 -> CTR : 28.14%
StyleShare_봄이 기다려질 땐 포근한 비누향을 뿌려요 -> CTR : 18.6%
wikitree_힙합계 '금수저 래퍼' 5인 -> CTR : 22.0%
Nylon korea_올 봄 유행 립컬러부터 각질없이 레드립 바르는 TIP -> CTR : 26.4%
컨텐츠 노출 횟수 대비 클릭, 즉 CTR이 높은 컨텐츠와 유사한 컨텐츠들을 뽑았는데 이들은 모두 CTR이 높은 컨텐츠들이었습니다. 같은 범주에 속하는 컨텐츠라고 볼 수 없었지만 모두 CTR이 10% 이상이었습니다. 컨텐츠의 평균 CTR이 3-4%라는 걸 고려하면 이는 매우 높은 수치임을 알 수 있습니다.
word2vec에서 단어 벡터끼리의 연산이 의미있었던 것 처럼 컨텐츠 벡터끼리의 연산도 의미가 있을까 싶어서 진행해 보았습니다. 연산 결과는 다음과 같습니다.
- 미용에 제일 가까운 컨텐츠 - 미용 + 웹툰 = 의미 찾기 어렵다.
- 미용에 제일 가까운 컨텐츠 - 미용 + 웹툰 + 높은 CTR 컨텐츠 = 의미 찾기 어렵다.
- 웹툰 + 높은 CTR 컨텐츠 + 웹툰 컨텐츠 = 높은 CTR의 웹툰 컨텐츠
첫번째 시도는 미용에 제일 가까운 컨텐츠에서 미용 태그를 빼고 웹툰 태그를 더하는 연산이었는데 웹툰과 제일 가까운 컨텐츠가 나올 것으로 예상했으나 전혀 다른 결과가 나와 의미를 찾기 어려웠습니다. 두번째 시도는 첫번째 시도와 유사하지만 높은 CTR을 갖는 컨텐츠를 찾는 연산인데 마찬가지로 예상과 전혀 다른 결과가 나와 의미를 찾기 어려웠습니다. 세번째 시도에서는 웹툰 컨텐츠 중 높은 CTR 컨텐츠를 찾는 연산인데 이를 통해 높은 CTR의 웹툰 컨텐츠를 찾을 수 있었습니다. 웹툰 태그의 컨텐츠들은 평균 4%의 CTR을 가졌으나 연산을 통해 얻은 컨텐츠들은 평균 8%의 높은 CTR을 가졌습니다. 현재 태그 데이터가 부족해 좋은 결과를 얻지 못했지만, 추후에 더 많은 태그 데이터를 추가하여 더 좋은 결과를 얻을 수 있을 것으로 기대됩니다.
별점 기록, 유저 평가 기록 없이 유저의 클릭 이력만 가지고 word2vec을 이용하여 높은 정확도의 컨텐츠 클러스터링 모델을 얻을 수 있었습니다. 이렇게 얻은 모델은 높은 정확도를 갖고 있었으며 추후에 사람이 지정한 태그 데이터를 추가하여 모델의 정확도를 발전시킬 수 있습니다. 또한 학습시간도 짧기에 이와 같은 방식으로 word2vec을 사용하여 다양한 클러스터링에 응용할 수 있을 것입니다. word2vec을 이용한 컨텐츠 클러스터링은 효율적인 컨텐츠 추천의 첫 단계입니다. 앞으로 클릭 이력이 없는 컨텐츠가 어떠한 벡터를 갖는 컨텐츠인지 예측하기 위해 TF-IDF, Paragraph2Vec 등 머신러닝을 이용해 효율적인 컨텐츠를 추천 시스템을 구축하고자 합니다. 앞으로도 기술적으로 진보하고 있는 버즈빌을 많이 주목해 주시고 다양한 소식으로 찾아뵙겠습니다.
[http://arxiv.org/pdf/1301.3781.pdf] [http://arxiv.org/pdf/1405.4053v2.pdf] [https://code.google.com/archive/p/word2vec/] [https://arxiv.org/pdf/1411.2738.pdf]
Abel Yoon
들어가며 안녕하세요, 버즈빌 데이터 엔지니어 Abel 입니다. 이번 포스팅에서는 데이터 파이프라인 CI 테스트에 소요되는 시간을 어떻게 7분대에서 3분대로 개선하였는지에 대해 소개하려 합니다. 배경 이전에 버즈빌의 데이터 플랫폼 팀에서 ‘셀프 서빙 데이터 …
Read Article
 Kay Lee
Kay Lee
안녕하세요. Demand Product 팀의 Ad Management 파트에서 서버 개발자로 일하고 있는 Kay입니다. 제가 팀에 합류한 지도 어느덧 2년이 되어가는데요, Ad Management 파트(이하 AdM)은 무슨 일을 하는지 간단하게 소개하고 재미있게 했던 …
Read Article