The Flip
 Maxence Mauduit
Maxence Mauduit- 28 Feb, 2026
이 글은 영문 원본을 AI로 번역한 버전입니다. 요즘 업계에 이런 기대가 퍼져 있습니다. 언젠가 AI가 디자인 시스템을 만들어 줄 거라는 거죠. 프롬프트 하나 던지면 토큰, 컴포넌트, 인터랙션 패턴이 깔끔하게 나올 거라고요. 저는 정반대의 일이 벌어지고 있다고 생각합니 …
Read Article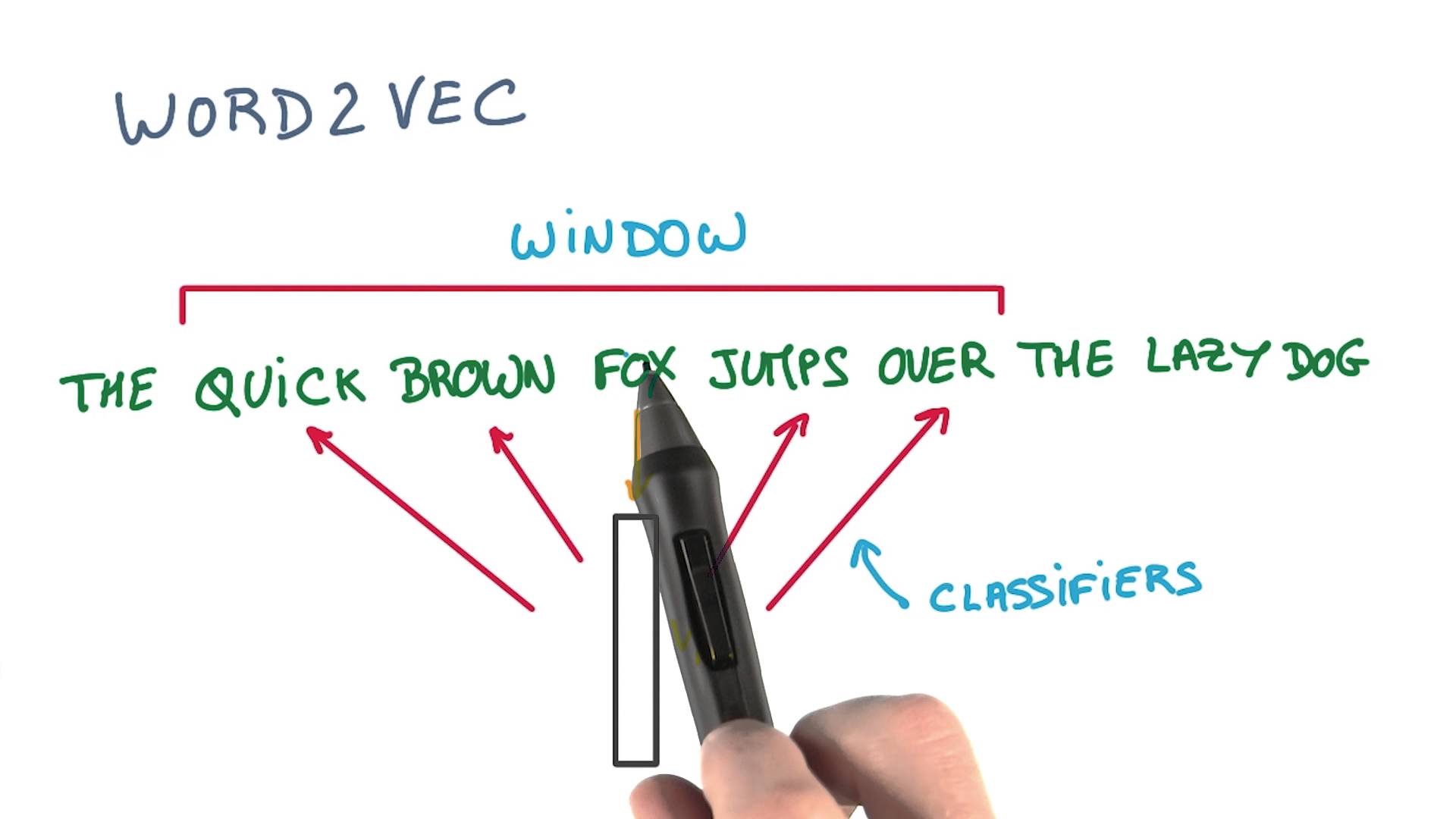
Honeyscreen, a key product of Buzzvil, serves not only ads which give reward point to users, but also various content. Users can see breaking news and hot content in their lock screen without opening social or portal apps. Likewise, serving high quality content to users is a very important task to solve to provide an improved Honeyscreen UX. To serve content efficiently, we focused on clustering content by category through machine learning. There are two approaches to cluster content:
We are trying to solve the problem using various machine learning techniques. To develop a more efficient clustering method, we used many Natural Language Processing (NLP) techniques such as Latent Dirichlet allocation (LDA) and Term frequency – Inverse Document frequency (TF-IDF). I’d like to introduce word2vec which is an easy, powerful, and efficient method, and explain how we used word2vec to cluster content.
Mikolov and Google engineers created word2vec, which is a neural network-based natural language processing algorithm that models words as vectors in high dimensional space. Over the years, word2vec has proven to bring a tremendous improvement in accuracy. word2vec assumes co-appearing words must be semantically similar, and defines the similarities of different words as the distances between corresponding word vectors. Additionally, word2vec is highly optimized so that a standard laptop can train such a model in reasonably short time. More concrete and mathematical details can be found in the paper mentioned in references. An interesting point of word2vec is that adding and subtracting content vectors has meaningful results. Those are results of adding and subtracting trained vectors of word2vec.
vector('Paris') - vector('France') + vector('Italy') = vector('Rome')
vector('king') - vector('man') + vector('woman') = vector('queen')
Like this, word2vec can represent not only vector embedding of words but also inference of words and complex meaning of words. word2vec has two model structures, Continuous Bag of Words (CBOW) and Continuous Skip-Gram. You can see an example below showing the difference between them.
Sentence : When I find myself in times of trouble mother Mary comes to me
CBOW Input : [When, I, find], [I, find, myself], [myself, in, times], ...
Skip-Gram Input : [When, I, find], [When, I, myself], [When, find, myself], ...
As you can see, the CBOW method takes sentences and uses the sliding window approach to define co-appearances. Skip-Gram, on the other hand, covers all the subsequences generated by CBOW and additionally includes subsequences that leave gaps skipped over. Obviously, CBOW takes shorter time and has advantages when the ordering of words matters, while Skip-Gram is more effective when a sparse data set is given and the ordering is relatively irrelevant.
Simply put, based on the frequency of words, word2vec places similar words into the vector space closer to each other. The neural network is one way of implementing such an approach that learns based on a large data set and iteratively adjusts distances between word vectors. Words, however, can be extended to mean not just words in the linguistics sense, but many other things. For example, I thought the click history of each user can be thought of as a sentence and the IDs of content articles as words. word2vec can then be used to learn how similar two words are, or equivalently how similar two content articles are! word2vec needs input as sentences made of several words, and we trained neural network with sentences made of content IDs as below.
User 1 : {campaign id | campaind ids which user 1 clicked} -> sentence 1
User 2 : {campaign id | campaind ids which user 2 clicked} -> sentence 2
...
We used python gensim word2vec model and trained model total 38 million + alpha sentences. It takes about 2.5 for learning time on a late 2013 13-inch MacBook Pro.
We defined similarity between content items as the cosine similarity of two vectors. Cosine similarity can be calculated through inner product of two vectors, so cosine similarity of equal content vectors is 1, and opposite content vectors is -1. With word2vec neural network model, some content items which have very high similarity in model look quite similar. We found that if similarity of the nearest content is higher than 0.95, we can think those contents are in same category. Here are the nearest top 10 contents list of one specific content. The nearest content similarity of these content items is higher than 0.95.
Content
- 역대급 미모 자랑하는 여자 아이돌
Similar content
1) 현아를 실제로 보면 이런 느낌이다
2) 마리텔 양정원의 사적인 필라테스
3) 어제 마리텔 생방하고 남초싸이트 뒤집은 양정원
4) 컴백 트와이스 쇼케이스 사진 9장
5) 꼬치 여신이 나타났다며 SNS서 확산되고 있는 사진
6) 게임광고에 처음 등장해 색다른 매력 뽐내는 I.O.I.
7) 남취향저격 귀염심쿵 여돌짤모음
8) 태양의 후예 이후 가장 덕본 스타 5명?
9) 아버지 당선에 큰 영향을 끼친 그녀의 미모
10) 슈가맨서 승리 거둔 완전체 I.O.I.의 '엉덩이'
These content items seem to be in the same category ‘Girl star’ and the accuracy is more than 95%. The nearest content similarity of this content is between 0.95 and 0.90.
Content
- 오마이뉴스_목사 꿈꾸던 신학생? 피해자에게도 꿈이 있었다
Similar content
1) TV데일리_성폭행 논란 유상무 '코빅' 통편집 '병풍 굴욕'
2) 인사이트 아트&컬처_전쟁을 하지 말아야 하는 이유
3) Insight_학생수 3명 부족해 폐교 위기 인천봉화초등학교
4) Insight_강남역 살인 사건에 프로레슬러 김남훈이 남긴 글
5) Insight_유상무 성폭행 신고 여성 국선 변호사 선임 신청했다
6) HuffPost_이제 학교폭력 가해자에 예외는 없다
7) 스낵_강남역 살인 '묻지마 VS 여혐' 당신의 생각은?
8) 스낵_이세돌 프로기사회 돌연 탈퇴! 불합리한 관행 탓
9) Insight_유럽 시골마을 떠오르는 강원도 원주 풍경
These content items are not exactly semantically similar. But they all fall in the category of “news”.
We tested our accuracy of model with labeled content tag data. These are the nearest content list of the ‘Webtoon’ and ‘Beauty’ tags:
Webtoon Tag
- 배틀코믹스_너의 목표는 이놈들보다 빨리 나를 처리하는 것이다
- 배틀코믹스_혹시 운동은 아니겠지요?
- 배틀코믹스_그녀의 롤 실력만 믿고 가는거야!
- 배틀코믹스_아빠는 너희 얼굴만 보면 다 견딜 수 있었단다
- 배틀코믹스_돈도 없는데 무슨 히어로야!
- SNAC_충무공 이순신 장군은 왜 일본도를 들었을까?
- 배틀코믹스_난 그런 흔해빠진 상대가 아니라고
- 뉴스1_안녕 멍뭉아 냐옹아 만나서 반가워 헤헷 :)
- 배틀코믹스_럼블이 수영장에서 봉변당한 트리스타나를 구할수 있을까?
- 배틀코믹스_제 안의 흑염룡을 깨워버렸어요!!
Beauty Tag
- piki_아이라인을 좀 더 예쁘게 그리기 위한 소소한 팁 7
- HuffPost_블랙헤드는 무엇이며 대체 어떻게 없애나?
- Insight_나쁜 남자한테 끌리는 여성은 성적 판타지’ 있다
- piki_블랙헤드 제거를 위한 최상의 방법 찾기
- 대학내일_피부 뒤집어졌을 때가장 먼저 해야 할 일 8
- wikitree_씨스타 소유가 요즘 한다는 '다이어트' 비법
- HuffPost_생리로 당신의 건강을 확인하는 법 5가지
- 타임보드_일주일만에 출렁이는 팔뚝살 빼는법!
Accuracy of the ‘Webtoon’ tag is about 80%, and the ‘Beauty’ tag is about 75%. By analyzing, we find that content which has no relation with tags have very many clicks or very few clicks. The content which has very many clicks make this error because it can be close to any contents during learning, and the content which has very few clicks make this error because of lack of learning data.
These are similar content items with high CTR content:
wikitree_씨스타 소유가 요즘 한다는 '다이어트' 비법 -> CTR : 28.14%
StyleShare_봄이 기다려질 땐 포근한 비누향을 뿌려요 -> CTR : 18.6%
wikitree_힙합계 '금수저 래퍼' 5인 -> CTR : 22.0%
Nylon korea_올 봄 유행 립컬러부터 각질없이 레드립 바르는 TIP -> CTR : 26.4%
Similar content with high CTR content are also have high CTR. It is hard to think they are in same category, but all of their CTR is higher than 10%. Compared to average CTR of content are 3-4%, it is a very high CTR value.
Like summation or subtraction of word vectors has meaning in word2vec, we wonder whether summation or subtraction of content vectors has meaning. These are the results.
- The most similar content with Beauty - Beauty + Webtoon = Meaningless.
- The most similar content with Beauty - Beauty + Webtoon + High CTR content = Meaningless.
- Webtoon + High CTR content + Webtoon = High CTR content
We think the result of the first try will be the nearest content to ‘Webtoon’, but we cannot find any meaning in the result. In the second try, we predict the result will be high CTR content in ‘Webtoon’, but it is also hard to find any meaning. And on the third try, the computation of three vectors is high CTR content in ‘Webtoon’. The average CTR of content in ‘Webtoon’ is about 4%, and the average CTR of result content are about 8%. We cannot get good results due to a of lack of tag data, so we think we can get better results with more tag data.
We can get a high accuracy neural network model with users’ click history without users’ comments and critics. Furthermore, this model can be improved with human-labeled content tag data. And word2vec can be applied to many clustering cases because of the short learning time. Clustering with word2vec is the first step of efficient content curation. We are going to build a content curation system that can predict content vector which has no click history with machine learning methods such as TF-IDF and paragraph2vec. Stay tuned to our blog as we continue to post updates and solutions to interesting problems that come our way. We will keep you updated!
[http://arxiv.org/pdf/1301.3781.pdf] [http://arxiv.org/pdf/1405.4053v2.pdf] [https://code.google.com/archive/p/word2vec/] [https://arxiv.org/pdf/1411.2738.pdf]
Maxence Mauduit이 글은 영문 원본을 AI로 번역한 버전입니다. 요즘 업계에 이런 기대가 퍼져 있습니다. 언젠가 AI가 디자인 시스템을 만들어 줄 거라는 거죠. 프롬프트 하나 던지면 토큰, 컴포넌트, 인터랙션 패턴이 깔끔하게 나올 거라고요. 저는 정반대의 일이 벌어지고 있다고 생각합니 …
Read Article Jed Jeon
Jed Jeon안녕하세요, 버즈빌 Supply Platform 팀의 Jed입니다. 대규모 트래픽 환경에서 낮은 지연 시간과 높은 가용성은 중요한 요소입니다. 따라서 버즈빌에서는 “Single-digit millisecond performance at any scale” …
Read Article