
Weighted Random Shuffling Algorithms
버즈빌에서는 잘 알려진 허니스크린, 버즈스크린 이라는 프로덕트 외에도 광고의 서빙 및 최적화를 담당하는 버즈애드라는 프로덕트를 운영하고 있습니다. 근본적으로, 광고의 효율을 높이려면 효율을 사전에 계산 할 수 있는 "스코어링" 과정이 반드시 필요합니다. 예를들어, 허니스크린에 N개의 아이템(광고 및 컨텐츠)중에서 K (<= N) 개를 선택하여 내보내고 싶은 상황을 가정해 봅시다. 여기서 K개의 아이템을 정하는 기준은 다양 할 수 있습니다. 랜덤하게 K개를 무작위로 선택할수도 있고 CTR (Click Through Rate) 기준으로 정렬하였을 때 높은 K개를 선택할 수 있습니다. CTR 예측과 같은 정교한 스코어링 모델을 만드는 것은 쉽지않은 일입니다. 하지만 설령 높은 정확도를 가지는 이러한 모델이 있다하더라도 정렬과 같은 결정적(deterministic)인 방식은 여전히 문제점을 가지고 있습니다. 첫번째, CTR과 같은 스코어는 시간 및 조건에 따라 변화 할 수 있는 값입니다. 같은 광고나 컨텐츠를 중복해서 노출 한다면 해당 광고에 대한 유저의 피로도가 높아져 CTR은 떨어지게 됩니다. 반대로, 시간이 지남에 따라 관심사가 변하여 이전에는 흥미없던 컨텐츠를 소비하게 될 수도 있습니다. 둘째, 콜드 스타트 문제를 겪게 됩니다. 잠금화면에 노출되는 광고 및 컨텐츠는 유저가 능동적으로 선택하여 볼 수 없습니다. 왜냐하면 유저는 미리 할당 된 광고 및 컨텐츠들만 소비하기 때문입니다. 따라서, 실제로는 유저가 더 좋아하는 잠재적 광고나 컨텐츠가 있을지라도 우리의 할당 최적화 모델은 편향 된 데이터를 바탕으로 다음 노출 아이템을 선택하게 됩니다. 스코어링 모델이 주어질 때 위 두가지 문제를 해결하는 좋은 방법중 하나가 바로 Weighted Random Shuffling 이라는 랜덤 알고리즘 입니다.
Overview
Weighted Random Shuffling (줄여서 WRS) 은 이름에서 알 수 있는 것 처럼 $latex a_1, a_2, .., a_n$ 의 양수의 정수 즉, 가중치들이 주어 졌을 때 이를 고려하여 섞는 방법을 말합니다. 가중치를 고려하는 샘플링이지만 한번 뽑힌 원소는 다시 고려하지 않는(sample without replacement) 샘플링을 WRS이라 부릅니다. 더 정확하게는, 가중치 배열 W =$latex w_1, w_2, .., w_n$ 와 이미 샘플한 집합 S = $latex s_1, s_2, .., s_n \subset W$ , W와 S의 원소들의 가중치 합 $latex Sum_W$와 $latex Sum_S$ 가 주어질 때, 가중치 $latex a_i \in A-S$를 가진 원소가 배열의 가장 앞에 위치할 확률 $latex a_i/(Sum_W-Sum_S)$을 보장하는 샘플링입니다. 예를들어 A = [1,2,3] 의 가중치 배열이 주어질 때 각각의 원소는 각각의 순서에 아래의 확률을 가지고 위치하게 됩니다. 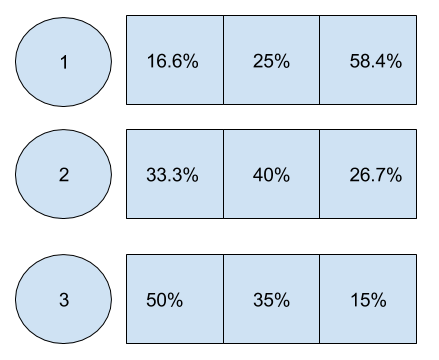 WRS을 통해 섞은 후 앞에서 부터 K개를 선택하게 되면 결정적 방식이 가진 단점들을 보완하여 아래와 같은 다양한 상황에 이용 될 수 있습니다.
WRS을 통해 섞은 후 앞에서 부터 K개를 선택하게 되면 결정적 방식이 가진 단점들을 보완하여 아래와 같은 다양한 상황에 이용 될 수 있습니다.
- 다양한 광고/컨텐츠 풀에서 주어진 조건에 맞는 K개 선택하기
- A/B 테스팅의 확장 버전인 Multi Armed Bandit 의 한 전략으로 사용하기
이러한 Weighted Random Shuffling 을 간단하게 구현한다면 $latex O(n^2)$의 시간복잡도를 가진 방법을 생각해 볼 수 있습니다.
Naive Approach
WRS 알고리즘은 주사위를 반복해서 던지는 과정으로 생각할 수 있습니다. 가중치 배열의 길이가 $latex N$일 때, 이 주사위는 $latex N$면을 가지고 있으며 각각의 눈이 나올 확률은 주어진 배열의 가중치들과 같습니다. 단, 주사위를 반복해서 던지면서 이미 나온 면들은 지워야 합니다. 즉, 주사위가 $latex N$면, $latex N-1$면, ..., 1면을 순서대로 가지게 되는거죠. 실제로 주사위를 던지는 과정은 $latex [0, W)$ 구간의 랜덤한 숫자 $latex T$를 정한 후, 각각의 가중치를 순회하면서 $latex W[i-1] < T[i] <= W[i],\ where\ T[i] = T - sum\ of\ already\ chosen\ weights\ up\ to\ i$ 인 $latex i$번째 면을 반환하는 방식으로 구현할 수 있습니다. 의사코드로는 아래와 같습니다.
func throw_dice (arr_weights) {
W <- sum(arr_weights)
T <- RANDOM(0, W) // sample uniformly from [0, W)
cumsum <- 0
FOR i in 0..n-1, DO {
IF T-cumsum <= arr_weigths[i], THEN
RETURN arr_weights[i]
cumsum += arr_weights[i]
}
}
이 알고리즘은 최악의 경우에$latex O(n^2)$의 수행시간을 가집니다. 큰 인풋 $latex N$의 경우에 이 알고리즘을 반복적으로 수행하기엔 부담스럽습니다. 수행 시간의 상한이$latex O(n^2)$ 보다 더 빠른 방법은 없을까요?
Binary Search Tree
위 방법을 개선하는 인사이트중 하나는 가중치 배열의 누적합(cumulative sum)을 구한 뒤 이진탐색을 통해 $latex cum\_w[i-1] < T[i] <= cum\_w[i]$ 을 만족하는 $latex i$를 찾는 방법입니다. 이는 전처리 과정에 $latex O(N)$, 탐색에 $latex O(logN)$ 만큼의 시간을 소비합니다. 해당 과정을 $latex N$번 반복한다면, 전처리 과정의 오버헤드 때문에 Naive 방법과 다르지 않는 $latex O(N^2)$의 수행시간이 걸리게 됩니다. 이를 개선하려면 이진 검색 트리 자료구조(https://en.wikipedia.org/wiki/Binary\_search\_tree)를 이용하는 방법이 있습니다. 이진 검색트리 자료구조를 사용하면 샘플링 후 누적합을 $latex O(logN)$ 만에 업데이트 할 수 있게 됩니다. 그럼 어떻게 이진 탐색 트리를 만들고 이를 이용하여 탐색 및 업데이트를 하는지 설명해보겠습니다.
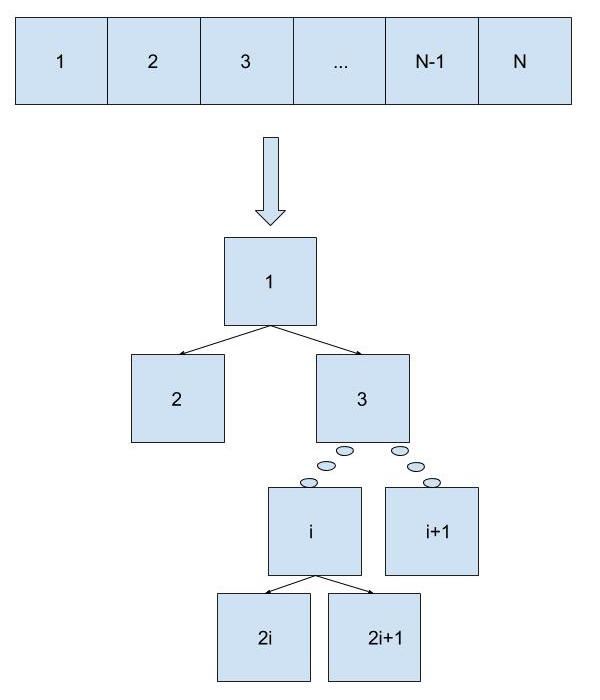
Tree Construction
먼저 주어진 가중치 배열을 이용해 트리를 생성하기 위해서 새로운 클래스를 정의할 수도 있지만 주어진 배열을 그대로 이용할 수 있는 간단한 트릭이 있습니다. 인덱스를 0부터 카운트하지 않고 1부터 카운트하면, 모든 인덱스 $latex i$에 대해 왼쪽, 오른쪽 자식을 각각 $latex 2i, 2i+1$로 표현할 수 있습니다. 트리를 생성하기 위해서 먼저 편의상 첫번째 원소를 이진 검색 트리의 루트로 표현합니다. 그 후, $latex n$번째 원소부터 거꾸로 배열을 순회하면서 자신의 가중치를 부모의 가중치에 더해줍니다. 즉, 모든 원소 $latex i$에 대해 $latex (weight,\ total\_weight\_of\_subtree\_rooted\_at\_i)$ 를 계산합니다.
Search and Update
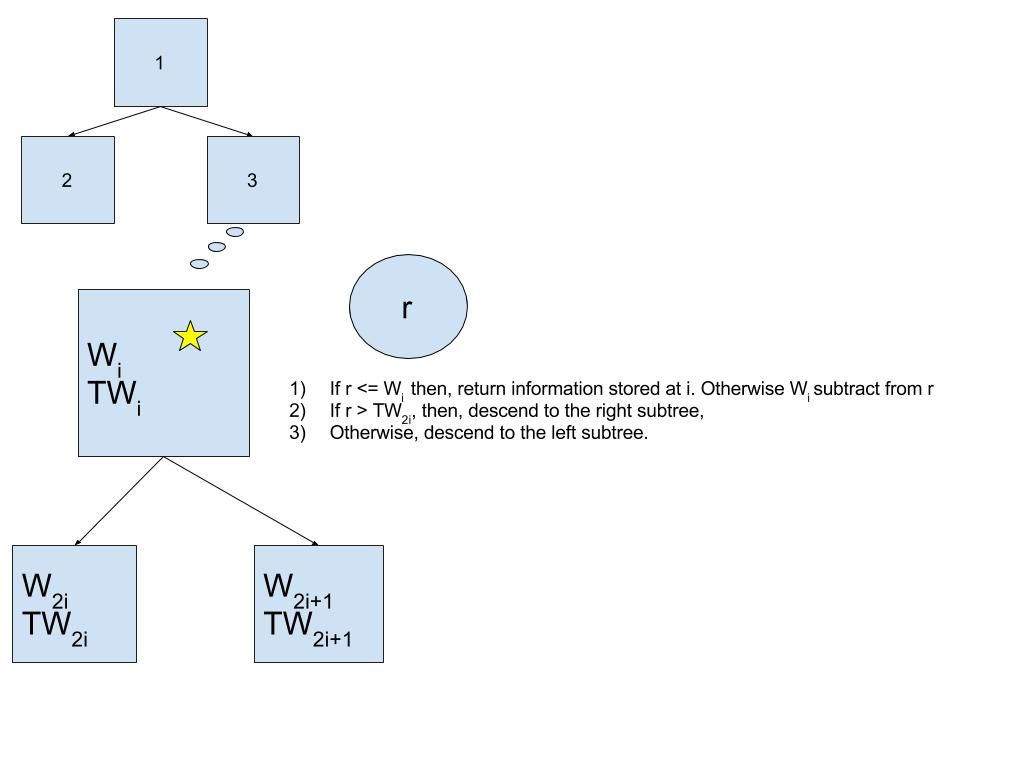 위 방식으로 트리 $latex T$를 만들고 나면 검색과 업데이트는 간단해집니다. 각각의 샘플에 대해서 우리가 원하는 원소는 다음의 과정을 통해 결정됩니다.
위 방식으로 트리 $latex T$를 만들고 나면 검색과 업데이트는 간단해집니다. 각각의 샘플에 대해서 우리가 원하는 원소는 다음의 과정을 통해 결정됩니다.
- 가중치 배열 $latex w_1, w_2, .., w_i$ 가 주어졌을 때, 먼저 $latex [1, W)$ 구간의 랜덤한 유리수 $latex r$를 하나 샘플합니다. $latex W$는 모든 가중치의 합입니다.
- 트리 $latex T$의 각각의 노드 $latex i$ 는 $latex (w_i, tw_i)$ 를 가지고 있습니다. $latex tw_i$는 노드 $latex i$를 루트로하는 자식트리의 가중치 합을 나타냅니다. 이제, 루트에서 검색을 시작합니다. 지금까지 트리를 따라 검색을 하여 노드 $latex i$에 도달했을 때, 현재의 $latex r$값과 $latex w_i$ 값을 비교하여 $latex r$이 작거나 같으면 해당 원소를 리턴합니다. 만약 위 조건이 참이 아니면, 왼쪽 자식 트리의 토탈 가중치합과 다시한번 비교합니다. 이때, 왼쪽 자식에 속한 모든 가중치의 합보다 $latex r$이 크다면 왼쪽 자식의 모든 노드는 고려대상이 아니기 때문에 오른쪽 자식 트리로 검색을 재게합니다. 1) 왼쪽자식으로 탐색 한다면 $latex r$ 을 $latex r = r - w_i$ 로 업데이트하고 2)오른쪽 자식으로 탐색한다면 $latex r = r - w_i - tw_{2i} $ 로 업데이트 합니다. 즉, 누적합을 계산하는 대신에 $latex r$을 줄여나가게 됩니다.
- 우리가 원하는 원소 $latex i$를 찾았다면, 해당 원소의 가중치를 0으로 업데이트 합니다. 해당 원소의 가중치가 0이라면 2번 조건은 항상 거짓이기 때문에 해당 원소는 다시 뽑히지 않게 됩니다. 해당 원소를 찾은 뒤, 부모를 거쳐 트리의 루트까지 올라가면서 거쳐가는 원소의 $latex tw_i$ 을 업데이트합니다.
각각의 탐색과 업데이트는 $latex O(logN)$의 시간이 듭니다. 따라서 위 과정을 $latex N$번 반복하면 $latex O(NlogN)$의 시간이 들게 됩니다.
Optimization Tricks
실제 프로덕션 환경에서 위 알고리즘을 사용시 적용할 수 있는 몇가지 팁이 있습니다.
- 위 방식으로 만들어진 BST는 가중치 배열의 원소가 홀수개라면 모든 노드의 자식이 0개 혹은 2개인 꽉찬 이진트리가 되고 (full binary tree), 짝수개라면 한개의 노드를 제외한 모든 노드의 자식이 0개 혹은 2개입니다. 실제 트리를 만드는 과정에서 원본 가중치 배열의 순서는 중요하지 않습니다. 가중치를 내림차순 정렬한 배열을 이용하여 BST를 만들면 가중치가 높은 원소들이 트리의 상위에 위치하게 되어 평균 검색 횟수를 줄일 수 있습니다.
- WRS로 접근할 수 있는 문제들의 정의에 따라 다르겠지만, WRS을 적용해야 될 가중치 배열이 동적으로 빠르게 변하지 않는 경우에는 이미 만들어진 트리를 레디스, 맴캐시등의 캐시 구조에 저장한 뒤 반복해서 사용할 수 있습니다. 본문에 소개된 이진 탐색 트리를 사용하는 방법 외에도 전처리 과정의 오버헤드는 있지만 해당 과정을 캐싱하여 오버헤드를 줄이고 검색/업데이트를 상수시간에 수행할 수 있는 알고리즘도 존재합니다 (alias method).
Wrapping it up...
버즈빌에서는 빠르게 확장하는 환경속에서 효율적인 플랫폼이 되기위해 많은 중요한 문제들을 적절한 알고리즘과 자료구조를 사용하여 해결하고 있습니다. 앞으로도 모바일 광고시장의 선두자가 되기위해 기술적인 혁신을 거듭하는 버즈빌을 주목해주세요.

