-
 Abel Yoon
Abel Yoon
- 18 Apr, 2024
데이터 엔지니어의 Airflow 데이터 파이프라인 CI 테스트 개선기
들어가며 안녕하세요, 버즈빌 데이터 엔지니어 Abel 입니다. 이번 포스팅에서는 데이터 파이프라인 CI 테스트에 소요되는 시간을 어떻게 7분대에서 3분대로 개선하였는지에 대해 소개하려 합니다. 배경 이전에 버즈빌의 데이터 플랫폼 팀에서 ‘셀프 서빙 데이터 …
Read Article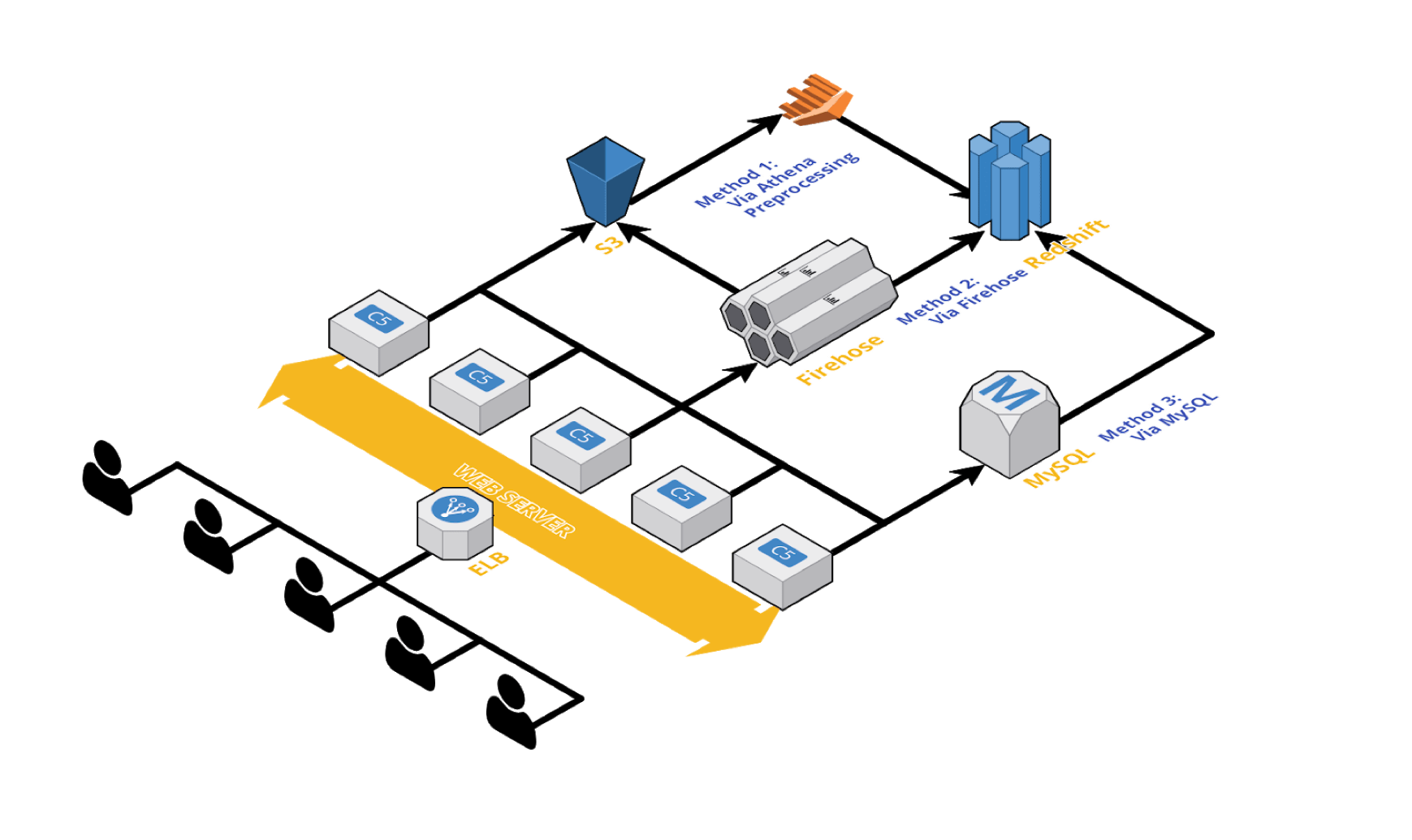
버즈빌에서는 미국과 일본을 비롯한 전 세계 30개국에서 1,700만 이상의 유저의 행동에 대한 데이터를 수집하고 있습니다. 이 데이터에는 유저들이 잠금화면에서 어떤 Action을 수행하는지부터 잠금화면에 어떤 광고가 노출되고 유저들이 어떤 광고를 클릭 하는 지 등의 정보들이 포함되는데요. 이러한 데이터는 여러 종류의 다른 소스로부터 오고 각기 다른 종류의 DB (MySQL, DynamoDB, Redis, S3 등등) 에 저장됩니다. 하지만 데이터를 분석하고 활용하기 위해서는 이렇게 흩어져서 저장된 데이터들을 한 곳으로 모으는게 필수적입니다. 그래서 저희 팀에서는 이렇게 다양한 소스로 부터 발생해서 다양한 DB에 저장된 데이터를 어떤 과정을 통해 한 곳으로 모을 것인가에 대해서 고민하게 되었습니다.
그리고 고민 끝에 각각의 DB에 저장된 데이터를 하나의 큰 데이터 스토리지에 모을 수 있는 ‘데이터 파이프라인’을 구축하는 계획을 세우게 되었습니다. 하지만 다양한 소스로부터 수집된 수많은 데이터들을 잘 유지해가며 하나의 큰 DB에 모을 수 있는 데이터 파이프라인을 구축하는 것이 쉽지 않았는데요. 이 포스팅을 통해서 버즈빌에서는 어떻게 각각의 데이터들을 수집하고 저장하는지 또 이런 데이터들을 통합하기 위한 파이프라인을 어떻게 구축했는지 공유하고자 합니다.
본격적인 이야기에 앞서 현재 버즈빌에서 모든 데이터가 모이는 데이터 스토리지로 사용 중인 RedShift에 대해 이야기하고 싶습니다. 개인적으로는 정말 쓰면 쓸수록 감탄이 나오는 데이터 스토리지라고 생각합니다. Redshift는 AWS에서 관리하는 SQL기반의 열기반 스토리지(SQL based columnar data warehouse)이며 복잡하고 대규모의 데이터 분석에 적합합니다. 고객들로부터 생성된 수많은 종류의 데이터를 기반으로 다양한 인사이트를 얻고자 하는 많은 기업들(Yelp, Coursera, Pinterest 등)이 사용하고 있는 솔루션 이기도 합니다. 버즈빌에서는 여러가지 특징을 고려하여 Redshift를 도입하게 되었는데요. 그 이유는 아래와 같습니다.
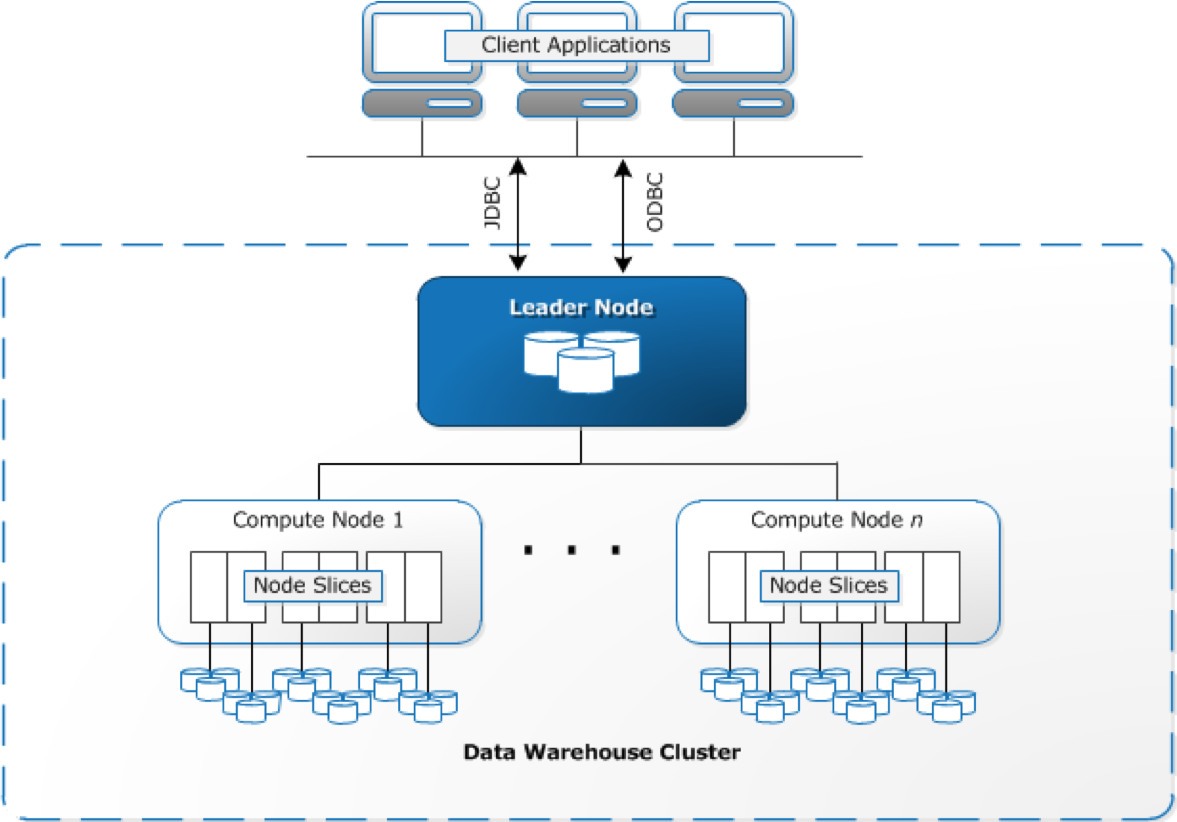
하지만 몇 개의 아쉬운 점들도 있습니다. :
버즈빌이 구축한 데이터 파이프 라인은 크게 3갈래의 메인 루트가 있습니다.

Why?
전처리 작업(Preprocessing)이 필요한 가장 큰 이유는 들어오는 데이터의 어마어마한 크기 때문입니다. 또 어떤 데이터들은 너무 raw하기 때문에 애널리스트나 데이터 사이언티스트가 분석에 활용할 수 있는 형태로 바꾸기위해 전처리가 필요하기도 합니다. 버즈빌에서는 이런 데이터들을 처리하기 위해서 AWS Athena를 사용하고 있습니다. Athena는 과금 방식이 Athena 쿼리로 읽은 데이터의 사이즈를 기반으로 하기 때문에 다른 EMR이나 MapReduce solution들을 사용했을때보다 상대적으로 적은 비용으로 활용할 수 있다는 장점이 있습니다.
How?
Pros?
Cons?
Why?
Kinesis Firehose는 Redshift, Elasticsearch, S3와 같은 최종 목적지까지 다양한 데이터들을 안정적으로 옮길 수 있는 파이프라인을 제공할 뿐 아니라 Fluentd와 매끄럽게 잘 연동된다는 점에서 굉장히 뛰어난 서비스 입니다. Fluentd는 서버로부터 firehose까지 데이터가 안정적이고 꾸준하게 전달 될 수 있도록 도와줍니다. 따라서 firehose와 fluentd의 연동을 통해서 따로 두개의 파이프라인 ( SERVER -> S3, S3 -> Redshift) 을 관리할 필요 없이 데이터 소스부터 최종 저장소까지 이어지는 하나의 파이프 라인만 관리할 수 있게 됩니다.
How?
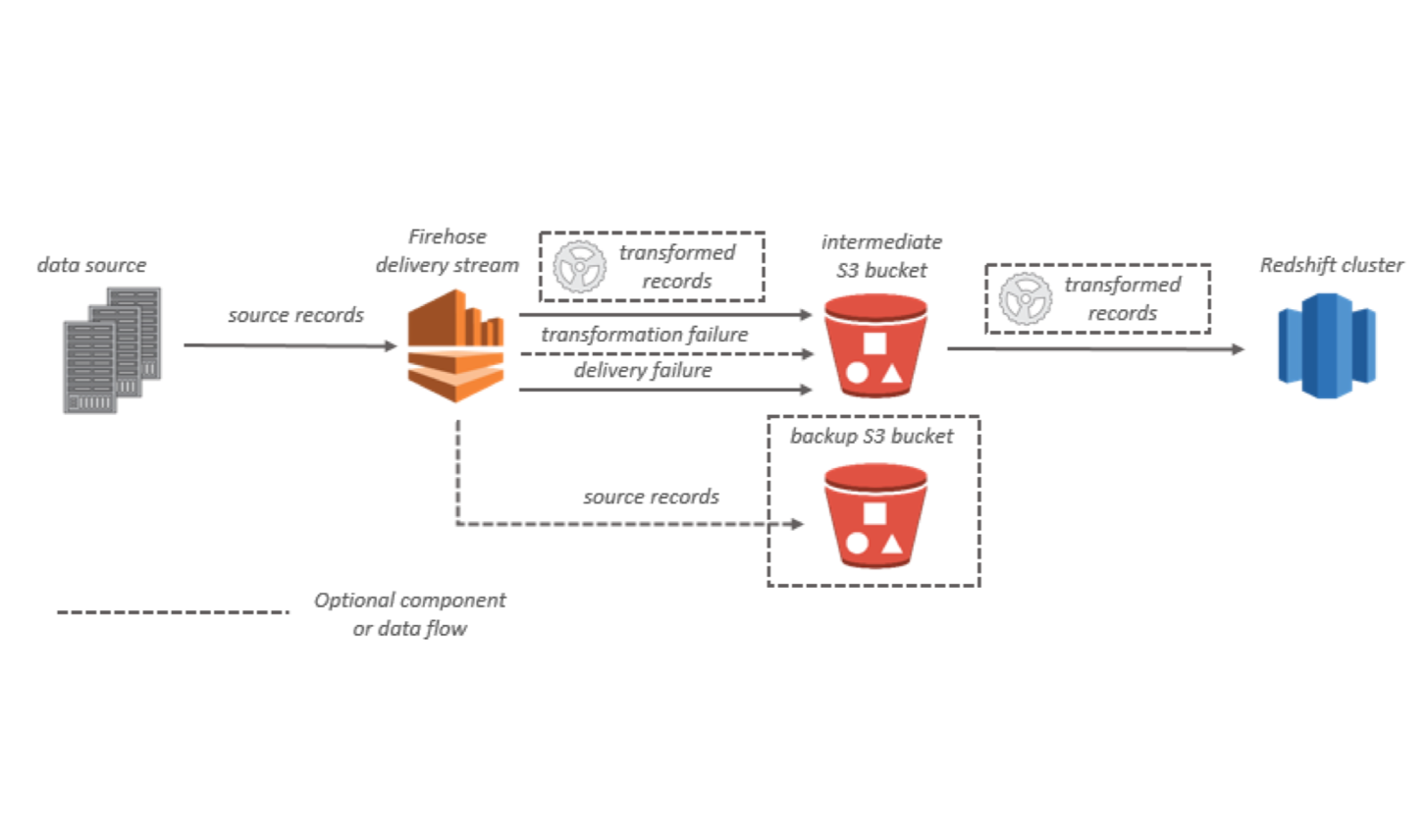
(https://docs.aws.amazon.com/firehose/latest/dev/what-is-this-service.html)
conf["user_activity"] = {
"DataTableName": "user_activity",
"DataTableColumns": "user_id, app_id, activity_type, timestamp",
"CopyOptions": "FORMAT AS JSON "s3://buzzvil-firehose/sample/user_activity/jsonpaths/user_activity_log-0001.jsonpaths" gzip TIMEFORMAT AS "YYYY-MM-DDTHH:MI:SS" ACCEPTINVCHARS TRUNCATECOLUMNS COMPUPDATE OFF STATUPDATE OFF",
"jsonpaths_file": "buzzvil-firehose/sample/user_activity/jsonpaths/user_activity_log-0001.jsonpaths",
}
configuration = {
"RoleARN": "arn:aws:iam::xxxxxxxxxxxx:role/firehose_delivery_role",
"ClusterJDBCURL": "jdbc:redshift://buzzvil.xxxxxxxxx.us-west-2.redshift.amazonaws.com:5439/sample_db",
"CopyCommand": {
"DataTableName": sample_table,
"DataTableColumns": conf[type]["DataTableColumns"],
"CopyOptions": conf[type]["CopyOptions"],
},
"Username": db_user,
"Password": db_password,
"S3Configuration": {
"RoleARN": "arn:aws:iam::xxxxxxxxxxxx:role/firehose_delivery_role",
"BucketARN": "arn:aws:s3:::firehose_bucket",
"Prefix": "buzzvil/user_activity/",
"BufferingHints": {
"SizeInMBs": 64,
"IntervalInSeconds": 60
},
"CompressionFormat": "GZIP",
"EncryptionConfiguration": {
"NoEncryptionConfig": "NoEncryption",
}
}
}
2. Fluentd docker containers을 각각의 서버에서 세팅하고 실행합니다.
<source>
@type tail
path /var/log/containers/buzzad/impression.json
pos_file /var/log/containers/td-agent/impression-json.pos
format none
tag firehose.impression
</source>
<match firehose.impression>
@type kinesis_firehose
region us-west-2
delivery_stream_name "prod-buzzad-impression-stream"
flush_interval 1s
data_key message
</match>
3. Firehose에서 데이터를 잘 모아서 Redshift 문제없이 보내고 있는지 모니터링 합니다.
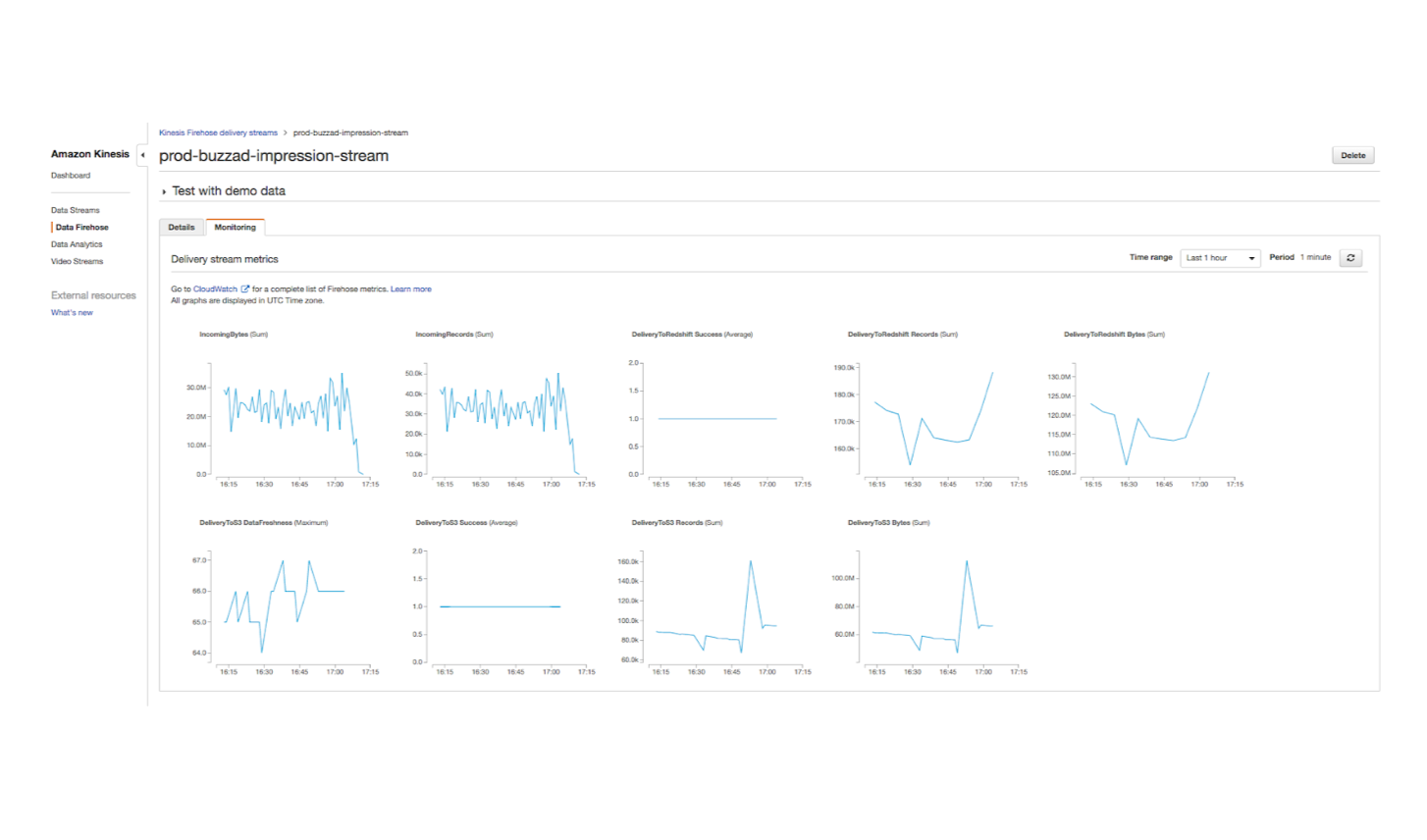
Cons?
Why?
여러대의 RDS MySQL DB로부터오는 데이터간의 sync를 맞춰가며 Redshift로 데이터를 복제하기 위해서는 3가지의 테크닉을 활용해야만 합니다. (이 방법은 소개하고 있는 세 메인 루트 중에서 가장 매력도가 떨어지는 방법입니다..)
How?
FULL_COPY
INCREMENTAL_COPY
UPDATE_LATEST_COPY
Pros?
Cons?
어떤 데이터를 다루는지에 따라서 위에서 소개한 3가지 방법 중 어떤 방법을 활용해야할지가 달라진다고 할 수 있습니다. 예를 들어 Transactianl log 같은 데이터들의 경우에는 firehose를 통해 전달하는 방법이나 먼저 aggregate하는 과정을 거친 후에 Redshift에 저장하는 식으로 처리를 해야 합니다. 그리고 MySQL에 저장된 fact table같은 데이터들은 CDC (change data capture) sync method를 통해서 Redshift에 데이터를 전달하고 동기화를 하는 과정이 필요합니다. 버즈빌에서는 위에서 소개해드린 3가지 방법을 적절히 조합해가면서 BD 매니저나 애널리스트들이 서비스간 플랫폼간의 데이터분석을 쉽게 할 수 있는 데이터 환경을 구축하기 위해서 노력하고 있습니다.
Abel Yoon
들어가며 안녕하세요, 버즈빌 데이터 엔지니어 Abel 입니다. 이번 포스팅에서는 데이터 파이프라인 CI 테스트에 소요되는 시간을 어떻게 7분대에서 3분대로 개선하였는지에 대해 소개하려 합니다. 배경 이전에 버즈빌의 데이터 플랫폼 팀에서 ‘셀프 서빙 데이터 …
Read Article
 Kay Lee
Kay Lee
안녕하세요. Demand Product 팀의 Ad Management 파트에서 서버 개발자로 일하고 있는 Kay입니다. 제가 팀에 합류한 지도 어느덧 2년이 되어가는데요, Ad Management 파트(이하 AdM)은 무슨 일을 하는지 간단하게 소개하고 재미있게 했던 …
Read Article