The Flip
 Maxence Mauduit
Maxence Mauduit- 28 Feb, 2026
이 글은 영문 원본을 AI로 번역한 버전입니다. 요즘 업계에 이런 기대가 퍼져 있습니다. 언젠가 AI가 디자인 시스템을 만들어 줄 거라는 거죠. 프롬프트 하나 던지면 토큰, 컴포넌트, 인터랙션 패턴이 깔끔하게 나올 거라고요. 저는 정반대의 일이 벌어지고 있다고 생각합니 …
Read Article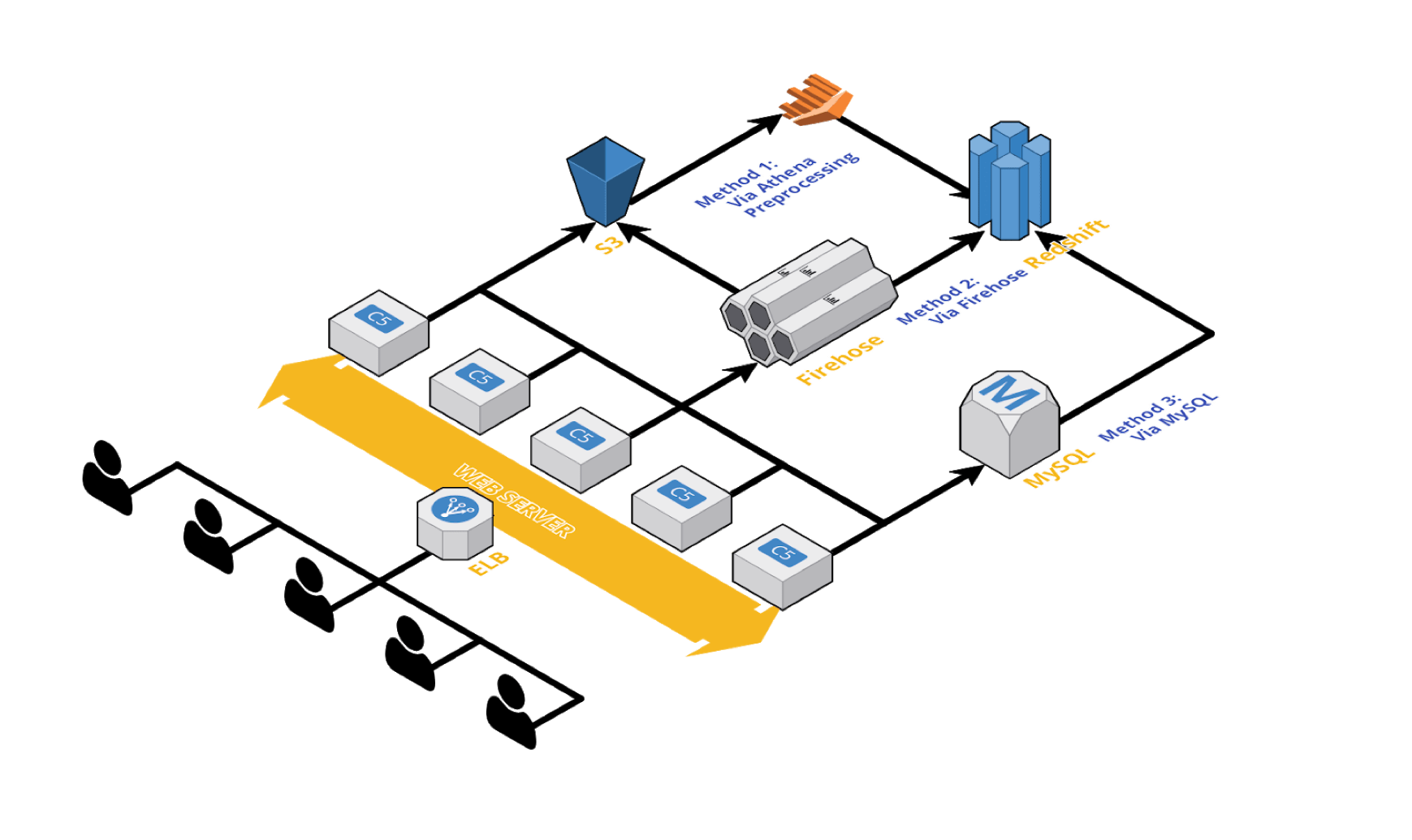
At Buzzvil, we are keeping track of activities of more than 17 million user in more than 30 nations. Such activities include various screen-related activities, AD impressions, AD clicks, AD conversions and beyond. These data comes from multitude of sources and usually get stored in different types of databases ( MySQL, DynamoDB, Redis, and even S3). By having these data in a single storage, we were able to analyze cross-service and cross-platform metrics with ease.
Building and maintaining a data pipeline that directs the data from multiple sources to a single data warehouse was a challenge for our team. And here is how we did it!
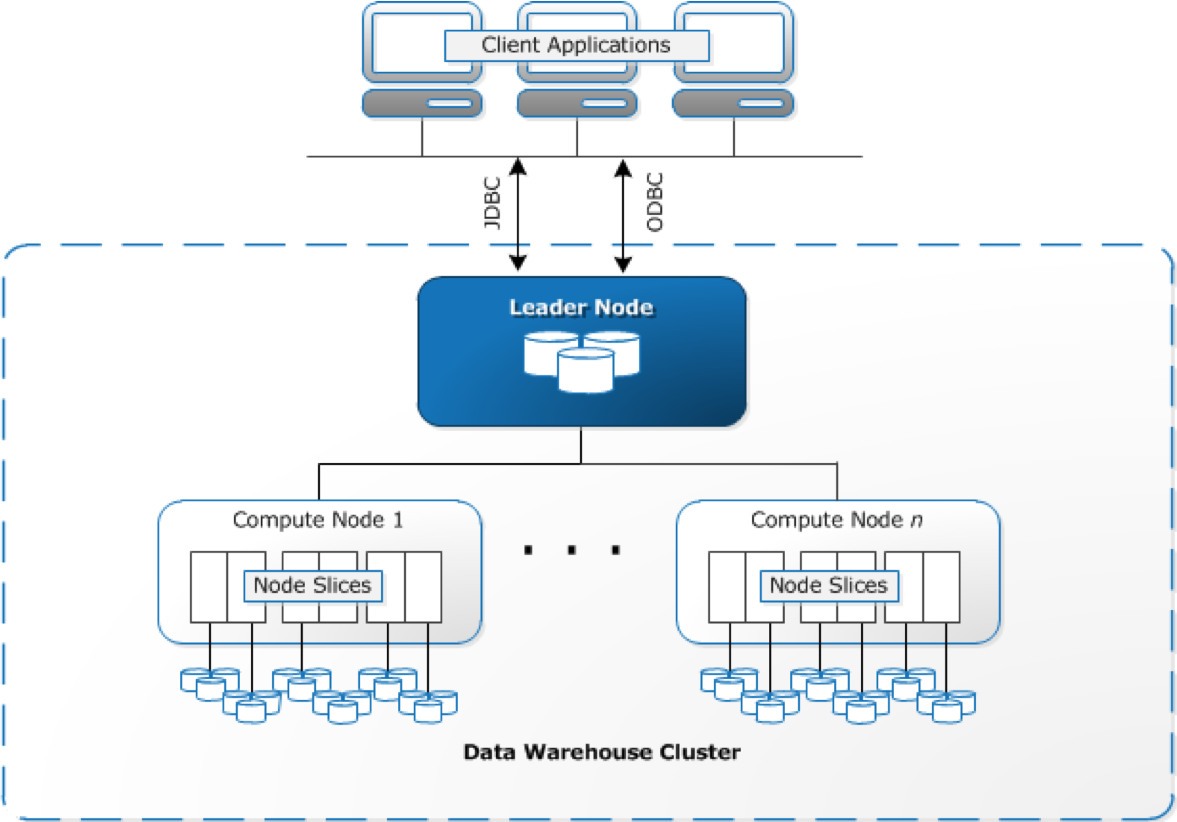
Before we discuss the pipeline, Redshift, our main data warehouse is worth mentioning in this blog post. It has surprised us since the beginning and is continuing to do so. Redshift is an AWS-managed, SQL based columnar data warehouse suited for complex and large-scale analytics. It is a solution well adapted by many enterprises customers (Yelp, Coursera, Pinterest, etc.), to drive insight from various types of data generated from their customers. At Buzzvil, we adapted Redshift because of the following reasons:
 However, there are some drawbacks as well:
However, there are some drawbacks as well:
There are mainly 3 ways that we use to deliver data to Redshift.

Why?
The primary reason for such preprocessing step is the sheer size of the incoming data. Some data might be too raw for analysts and data scientists to query directly. Thus, we utilized AWS Athena (https://aws.amazon.com/athena/) to leverage the fact that AWS only charges us for the size of the data read by the Athena query. If we are to preprocess the data through EMR or other MapReduce solutions, we might have to spend much more on computing costs in order to process more than
How?
1. Send data to S3
2. Aggregate/Process using Athena
3. Load the processed data into Redshift (COPY command)
Pros?
1. Serverless (No need to manage EMR clusters or servers)
2. Cheap ($5 for each 1TB read from S3)
Cons?
1. During peak hours (12:00 AM UTC), some queries might fail. -> We do not recommend running mission-critical logics on Athena.
2. Does not (yet) provide the full functionality of PRESTO DB.
Why?
Kinesis Firehose is excellent as it not only provides a stable pipeline to various data destinations such as Redshift, Elasticsearch and S3, but also seamlessly integrates with Fluentd which provides a steady and stable stream of data from servers to firehose.With firehose-fluentd integration, rather than having to manage two separate pipelines ( SERVER -> S3, S3 -> Redshift ), we only have to manage and monitor a single data pipeline from the source to the sink.
How?
(https://docs.aws.amazon.com/firehose/latest/dev/what-is-this-service.html) 1.Create Firehose delivery stream with correct data format and ingestion period of your choice.
conf["user_activity"] = {
"DataTableName": "user_activity",
"DataTableColumns": "user_id, app_id, activity_type, timestamp",
"CopyOptions": "FORMAT AS JSON "s3://buzzvil-firehose/sample/user_activity/jsonpaths/user_activity_log-0001.jsonpaths" gzip TIMEFORMAT AS "YYYY-MM-DDTHH:MI:SS" ACCEPTINVCHARS TRUNCATECOLUMNS COMPUPDATE OFF STATUPDATE OFF",
"jsonpaths_file": "buzzvil-firehose/sample/user_activity/jsonpaths/user_activity_log-0001.jsonpaths",
}
configuration = {
"RoleARN": "arn:aws:iam::xxxxxxxxxxxx:role/firehose_delivery_role",
"ClusterJDBCURL": "jdbc:redshift://buzzvil.xxxxxxxxx.us-west-2.redshift.amazonaws.com:5439/sample_db",
"CopyCommand": {
"DataTableName": sample_table,
"DataTableColumns": conf[type]["DataTableColumns"],
"CopyOptions": conf[type]["CopyOptions"],
},
"Username": db_user,
"Password": db_password,
"S3Configuration": {
"RoleARN": "arn:aws:iam::xxxxxxxxxxxx:role/firehose_delivery_role",
"BucketARN": "arn:aws:s3:::firehose_bucket",
"Prefix": "buzzvil/user_activity/",
"BufferingHints": {
"SizeInMBs": 64,
"IntervalInSeconds": 60
},
"CompressionFormat": "GZIP",
"EncryptionConfiguration": {
"NoEncryptionConfig": "NoEncryption",
}
}
}
2.Setup and run Fluentd docker containers in each server.
<source>
@type tail
path /var/log/containers/buzzad/impression.json
pos_file /var/log/containers/td-agent/impression-json.pos
format none
tag firehose.impression
</source>
<match firehose.impression>
@type kinesis_firehose
region us-west-2
delivery_stream_name "prod-buzzad-impression-stream"
flush_interval 1s
data_key message
</match>
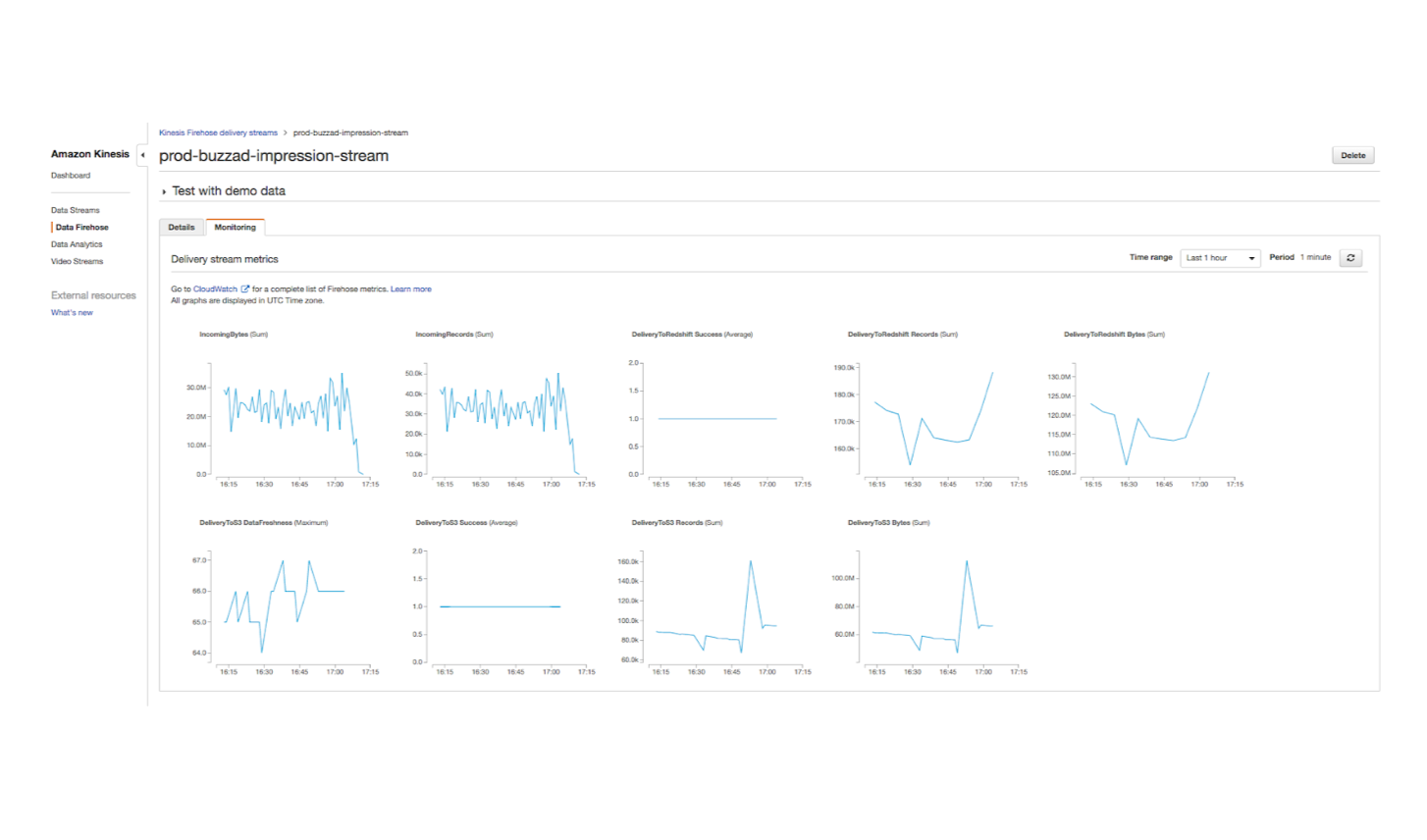
3.Monitor as data is captured by Firehose and are sent to Redshift.
Pros?
Cons?
Why?
In order to sync subsets of data from multiple RDS MySQL databases, we had to employ three different techniques to copy the relevant data to our Redshift cluster (This is the least glamorous option of the three).
How?
FULL_COPY
INCREMENTAL_COPY
UPDATE_LATEST_COPY
Pros?
Cons?
These three methods differ by the type of data that is being delivered to the target sink. For example, transactional, log type data would be delivered by firehose or be aggregated and then loaded to Redshift. On the other hand, fact tables from MySQL might be synced to Redshift via a specific type of CDC (change data capture) sync method. A combination of these 3 methods allows our analysts and BD managers to query cross-service or cross-platform data with ease.
Maxence Mauduit이 글은 영문 원본을 AI로 번역한 버전입니다. 요즘 업계에 이런 기대가 퍼져 있습니다. 언젠가 AI가 디자인 시스템을 만들어 줄 거라는 거죠. 프롬프트 하나 던지면 토큰, 컴포넌트, 인터랙션 패턴이 깔끔하게 나올 거라고요. 저는 정반대의 일이 벌어지고 있다고 생각합니 …
Read Article Jed Jeon
Jed Jeon안녕하세요, 버즈빌 Supply Platform 팀의 Jed입니다. 대규모 트래픽 환경에서 낮은 지연 시간과 높은 가용성은 중요한 요소입니다. 따라서 버즈빌에서는 “Single-digit millisecond performance at any scale” …
Read Article