
-
 Zune Seo
Zune Seo
- 30 Apr, 2024
AWS 비용 최적화 Part 1: 버즈빌은 어떻게 월 1억 이상의 AWS 비용을 절약할 수 있었을까
버즈빌은 2023년 한 해 동안 월간 약 1.2억, 연 기준으로 14억에 달하는 AWS 비용을 절약하였습니다. 그 경험과 팁을 여러 차례에 걸쳐 공유합니다. AWS 비용 최적화 Part 1: 버즈빌은 어떻게 월 1억 이상의 AWS 비용을 절약할 수 있었을까 (준비중) …
Read Article
Zune Seo

광고 서버는 리워드 광고 플랫폼을 운영 중인 버즈빌에게 있어서 핵심적인 구성요소입니다. 광고 서버의 주요 기능 중 하나는 광고주가 설정한 여러 가지 타게팅 조건에 맞는 유저에게 광고를 송출하는 타게팅 기능입니다. 버즈빌은 허니스크린이라는 잠금화면 리워드 광고 앱을 운영하기 시작한 초기 시절부터 광고 서버를 직접 구축해 운영해왔습니다. 이후 리워드 광고 플랫폼으로의 전환을 거치며 유저 수, 광고 수가 급격히 늘어나고 타게팅 조건 또한 다양해지면서 수평 확장할 수 있는 광고 서버를 구축할 필요성이 커지게 됐습니다. 이 과정에서 초기 MySQL 기반으로 구축되어 있던 시스템을 엘라스틱서치로 전환하였고 이에 대해 자세한 이야기를 해보려고 합니다.
광고 서버에는 두 가지 도전 과제가 존재합니다.
광고 송출 최적화를 위해 활용 가능한 특성 두 가지를 알아보겠습니다.
앞으로 풀어갈 문제를 이해하기 쉽게 하기 위해 간단하게 광고 모델을 정의하고 시작하겠습니다.
Lineitem
광고의 타게팅 정보를 담고 있는 테이블입니다.
| Column | Description |
|---|---|
| id | Self-explanatory |
| is_active | Self-explanatory |
| target_country | Possible values are KR, US, … |
| target_gender | Possible values are ALL, M, and F |
| target_carrier | Possible values are ALL, VERIZON, TMOBILE, … |
Creative
광고 이미지와 같은 유저에게 보이는 광고의 속성을 담고 있는 테이블입니다. Lineitem 테이블과 1:1 관계를 맺습니다.
| Column | Description |
|---|---|
| id | Self-explanatory |
| lineitem_id | Self-explanatory |
| image_url | Self-explanatory |
Action
광고를 통해 사용자가 달성하기를 원하는 액션에 대한 정의를 담고 있는 테이블입니다. Lineitem 테이블과 1:1 관계를 맺습니다.
| Column | Description |
|---|---|
| id | Self-explanatory |
| lineitem_id | Self-explanatory |
| action_type | Possible values are landing, install, purchase, … |
| action_metadata | JSON serialized metadata for action |
미국에 사는 버라이즌 통신사를 쓰는 여성에 대한 타게팅 조건을 만족하는 광고를 한번에 조회하는 예제 쿼리는 다음과 같습니다.
SELECT
*
FROM
lineitem
INNER JOIN
creative
ON
lineitem.id = creative.lineitem_id
INNER JOIN
action
ON
lineitem.id = action.lineitem_id
WHERE
lineitem.is_active = 1
AND lineitem.target_country = 'US'
AND lineitem.target_gender in ('ALL', 'F')
AND lineitem.target_carrier in ('ALL', 'VERIZON')
이 접근법은 여러 테이블에 엑세스가 발생하는 문제점이 있으며 where 조건이 복잡하여 인덱스를 활용하기 어려워 풀 스캔을 통해 데이터를 조회하게 됩니다.
다수 테이블 join 문제
세 개의 테이블을 join한 결과를 별도의 광고 송출 캐시에 동기화합니다. 꼭 외부에 존재하는 캐시가 아니더라도 MySQL 내에 캐싱 테이블을 만들 수도 있습니다. 이 캐시는 일종의 materialized view라고 생각할 수 있습니다.
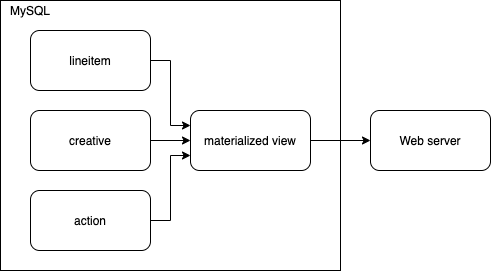
복잡한 where 조건 문제
타게팅 조건에 따라 {is_active}:{target_country}:{target_gender} 형태의 이름을 가지는 테이블을 각각 만듭니다. 예를 들면 아래와 같은 테이블들이 존재할 수 있습니다.
0:KR:M1:KR:M1:US:ALL1:US:M1:US:F캐싱 테이블을 쪼개두면 앞선 예제 쿼리에서는 1:US:ALL 과 1:US:F 두 개의 테이블만 검색해보면 되기 때문에 풀 스캔해야 하는 데이터를 크게 줄일 수 있습니다.
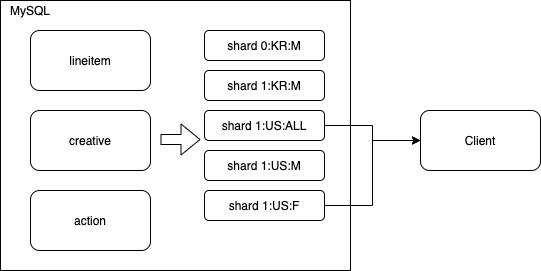
앞선 해결 방법은 타게팅 조건이 복잡하고 많아질 수록 캐싱 테이블의 숫자가 기하급수적으로 증가하기 때문에 확장성이 부족합니다. 확장성을 확보하기 위한 노력을 더 하기전에 “바퀴를 재 발명"하지 않을 방법을 고민했고 검색엔진을 활용하는 아이디어를 떠올리게 되었습니다. 예를 들어 구글은 다양한 키워드를 이용해 방대한 웹 페이지를 빠르게 검색해줍니다. 검색 엔진에서의 검색 키워드를 광고 시스템에서의 사용자 정보(국가, 나이 성별 등등)로 대입해서 생각해보면 두 시스템이 비슷한 종류의 일을 한다고 생각할 수 있습니다. 버즈빌에서는 광고 서버를 위한 검색 엔진으로 엘라스틱서치를 선택하였습니다.
검색엔진이 빠르게 검색할 수 있는 이유는 바로 inverted index를 활용하기 때문입니다. Inverted index의 원리에 대해서는 Elastic 사의 블로그에 잘 설명되어 있습니다. Invented index를 원리에 대해서 알고 있다는 가정하에 여기서는 앞서 보여드린 lineitem 샘플 데이터가 어떻게 인덱싱이 되는지를 알아보겠습니다.
Lineitem 샘플 데이터
예제에서 활용할 Lineitem 샘플 데이터는 아래와 같습니다.
| id | is_active | target_country | target_gender | target_carrier |
|---|---|---|---|---|
| 1 | 0 | KR | M | TMOBILE |
| 2 | 0 | KR | M | VERIZON |
| 3 | 1 | KR | M | TMOBILE |
| 4 | 1 | US | ALL | TMOBILE |
| 5 | 1 | US | ALL | VERIZON |
| 6 | 1 | US | M | ALL |
| 7 | 1 | US | M | TMOBILE |
| 8 | 1 | US | M | VERIZON |
| 9 | 1 | US | F | ALL |
| 10 | 1 | US | F | TMOBILE |
| 11 | 1 | US | F | VERIZON |
샘플 데이터에 대한 인덱스 데이터
아래의 표는 각 term에 대해 인덱싱된 document id를 나타냅니다.
| Term | Documents |
|---|---|
| is_active:0 | 1,2 |
| is_active:1 | 3,4,5,6,7,8,9,10,11 |
| target_country:KR | 1,2,3 |
| target_country:US | 4,5,6,7,8,9,10,11 |
| target_gender:ALL | 4,5 |
| target_gender:M | 1,2,3,6,7,8 |
| target_gender:F | 9,10,11 |
| target_carrier:ALL | 6,9 |
| target_carrier:TMOBILE | 1,3,4,7,10 |
| target_carrier:VERIZON | 2,5,8,11 |
처음에 봤던 샘플 쿼리를 처리하기 위해 어떻게 동작할지 생각해보기 위해 where 조건을 다시 가져왔습니다.
lineitem.is_active = 1
AND lineitem.target_country = 'US'
AND lineitem.target_gender in ('ALL', 'F')
AND lineitem.target_carrier in ('ALL', 'VERIZON')
위의 쿼리는 다음과 같은 집합 연산으로 변환할 수 있습니다.
(is_active:1) ⋂ (target_country:US) ⋂ ((target_gender:ALL) ⋃ (target_gender:F)) ⋂ ((target_carrier:ALL) ⋃ (target_carrier:VERIZON))
= (3,4,5,6,7,8,9,10,11) ⋂ (4,5,6,7,8,9,10,11) ⋂ ((4,5) ⋃ (9,10,11)) ⋂ ((6,9) ⋃ (2,5,8,11))
= (3,4,5,6,7,8,9,10,11) ⋂ (4,5,6,7,8,9,10,11) ⋂ (4,5,9,10,11) ⋂ (2,5,6,8,9,11)
= (5,9,11)
이렇게 inverted index는 데이터를 풀 스캔하지 않고도 복잡한 조건에 대해 효율적으로 조회를 할 수 있습니다.
한편으로 검색엔진은 일종의 추천 엔진으로 생각할 수 있습니다. 구글은 우리가 입력한 키워드에 가장 알맞은 결과를 순위를 매겨 순서대로 리턴해줍니다. 광고 시스템도 유저의 정보를 바탕으로 가장 적절한 광고를 골라주어야 합니다. 기존의 데이터베이스에서는 단순히 필터링 기능만을 제공했다면 엘라스틱서치를 활용하면 필터링뿐만 아니라 다양한 스코어링 로직을 활용해 광고 순위를 매기는 것도 가능합니다. 심지어 엘라스틱서치에 머신러닝 기능까지 지원되기 때문에 잘만 활용하면 간단한 추천 로직은 엘라스틱서치만 써도 해결할 수 있습니다.
예를 들어 유저 정보와 광고 정보를 벡터화 한 다음 두 벡터의 거리가 가까운 순서대로 광고를 정렬할 수 있습니다. 이를 구현하기 위해 엘라스틱서치 painless script에서 지원해주는 cosineSimilarity 함수를 활용하면 됩니다.
엘라스틱서치는 수십 GB에서 수백 TB 이상의 문서에서 검색을 수행할 수 있으며 이를 위해서 샤드와 레플리카를 지원합니다. 여러 개의 샤드를 이용해 데이터가 늘어나더라도 수평 확장 할 수 있으며 레플리카를 통해 검색 처리량을 높이고 안정적인 시스템을 구축할 수 있습니다.
하지만 광고 송출 시스템에서는 샤드가 필요 없습니다. 만약 웹사이트 검색엔진을 만든다고 하면 문서량이 많기 때문에 샤드가 필요하지만, 광고 송출 시스템에서는 활성화된 광고만 필요해 문서량이 그렇게 많지않습니다. 하루에 라이브 되는 광고의 숫자는 많아야 수십만 개 이하입니다. 광고 데이터의 사이즈가 수백 MB에서 수십 GB 사이가 될 것입니다. 이 정도면 하나의 샤드로도 충분한 크기입니다. 샤드가 많으면 한 번의 검색을 위해 모든 샤드에 다 요청을 보내야 하므로 비효율적입니다.
샤드를 한 개로 했으니 노드당 레플리카는 한 개만 존재하도록 설정하면 가장 효율적입니다. 기본적으로 엘라스틱서치는 레플리카의 개수를 고정하게 되어 있습니다. 만약 노드가 5개인데 레플리카의 개수가 4개로 설정되어 있다면 1개의 노드는 놀게 됩니다. 따라서 정확하게 노드 개수만큼 레플리카가 생성되도록 해야 하는데 인덱스 생성 시 "auto_expand_replicas": "0-all"와 같은 옵션을 줌으로써 해결할 수 있습니다.
성능과 관련해서 또 하나 고려해야 할 것은 coordinating 노드입니다. 여러 개의 샤드로 구성된 클러스터 환경에서는 특정 노드에 원하는 샤드가 존재하지 않을 수 있습니다. 모든 노드는 coordinating 노드의 역할을 하며 클라이언트로부터 요청받았을 때 데이터가 존재하는 노드로 요청이 전달될 수 있도록 라우팅하는 역할을 합니다. 1 노드, 1 샤드, 1 레플리카 환경에서는 모든 노드에 샤드가 존재하기 때문에 항상 로컬 노드에 데이터가 있는 것이 보장됩니다. 하지만 coordinating 노드는 제 나름대로 로드 밸런싱을 하느라 라운드 로빈 형태로 리퀘스트를 전달하는 것으로 보입니다. 이 때문에 로컬 노드에 데이터가 있음에도 불구하고 엉뚱하게 다른 노드로 리퀘스트를 전달하여 불필요한 네트워크 통신을 발생시킵니다. 이를 방지하기 위해서 search preference 에서 _only_local 옵션을 사용합니다.
마지막으로 데이터 사이즈가 작은 편에 속하기 때문에 디스크, 메모리보다는 CPU에 성능이 바운드되는 경향이 보입니다. 따라서 컴퓨팅 파워가 강한 인스턴스를 사용하는 것을 추천합니다.
버즈빌에서는 오토스케일링 그룹 안에 엘라스틱서치 클러스터를 구성하고 앞단에 ELB(Elastic load balancer)를 붙여 사용하고 있습니다. 트래픽이 증가하는 경우 인스턴스 숫자를 늘리기만 하면 쉽게 스케일 아웃을 할 수 있습니다. 이를 통해 특별한 노력을 기울이지 않고도 쉽게 수평 확장할 수 있는 시스템을 구축할 수 있습니다.
운영중인 클러스터의 평균 응답속도는 P95 기준 약 21ms 정도 됩니다. 스코어링 로직을 커스터마이징하기 위해 오버헤드가 존재하는 painless script를 활용하고 있는 점을 고려하면 괜찮은 수치라고 생각합니다. 엘라스틱서치에 메모리를 송출할 때 전체 시스템 메모리의 약 절반 정도만 송출하는 것이 가이드입니다. 이유는 나머지 반은 OS가 파일 시스템을 캐싱하는 용도로 쓸 수 있도록 하기 위함입니다. 앞서 말씀드렸듯이 전체 광고 데이터가 수 GB 정도밖에 안 되기 때문에 모든 광고가 파일 시스템 캐시의 형태로 메모리에 올라가 있는 상태라고 생각할 수 있습니다. 디스크 기반 데이터베이스이지만 인 메모리 데이터베이스에 가까운 성능을 기대할 수 있는 이유입니다.
글을 마무리하며 강조하고 싶은 부분은 최소한의 노력으로 원하는 시스템을 구축했다는 사실입니다. 광고 서버 엔진을 직접 구축하는 대신 검색엔진을 활용하여 구축함으로써 많은 시간을 절약할 수 있었습니다. 또한 엘라스틱서치라는 실 환경에서 충분히 증명되고 널리 쓰이는 기술을 사용함으로써 안정적으로 시스템을 운영할 수 있었습니다.
버즈빌에서 엘라스틱서치를 어떻게 활용하고 있는지 더 궁금하시다면 아래 아티클을 읽어보는 것도 추천드립니다!
Zune Seo
버즈빌은 2023년 한 해 동안 월간 약 1.2억, 연 기준으로 14억에 달하는 AWS 비용을 절약하였습니다. 그 경험과 팁을 여러 차례에 걸쳐 공유합니다. AWS 비용 최적화 Part 1: 버즈빌은 어떻게 월 1억 이상의 AWS 비용을 절약할 수 있었을까 (준비중) …
Read Article
 Abel Yoon
Abel Yoon
들어가며 안녕하세요, 버즈빌 데이터 엔지니어 Abel 입니다. 이번 포스팅에서는 데이터 파이프라인 CI 테스트에 소요되는 시간을 어떻게 7분대에서 3분대로 개선하였는지에 대해 소개하려 합니다. 배경 이전에 버즈빌의 데이터 플랫폼 팀에서 ‘셀프 서빙 데이터 …
Read Article