
RDS MySQL IOPS 장애 대응기
Software Engineer
버즈빌에서 AWS RDS MySQL 데이터베이스를 운영하는 중에 맞닥뜨린 메모리 문제와 그 해결 방법에 대해 소개하는 글입니다.
들어가며
안녕하세요, 버즈빌 엔지니어 Summer입니다. 현재 버즈빌 광고의 월평균 사용자는 2천만명 정도이고 버즈빌 서버로 한달간 약 70억건 정도의 광고 요청이 들어옵니다. 마이크로서비스로 쪼개져있는 서비스중 광고 요청을 보낸 사용자를 조회 하는 서비스의 트래픽 RPS는 5000/s 정도 됩니다. 이번 글에서는 방금 언급한 user service에서 사용중인 AWS RDS 데이터베이스를 운영하던 중 발생했던 장애 상황과 이를 해결하면서 배웠던 점들을 소개하겠습니다.
장애 상황
당시 상황은 퇴근 직전(!) user 서비스에 에러율이 올라갔다는 슬랙 알람을 받으면서 시작했습니다. 지표들을 확인해보니 cpu는 throttle걸리고 있었고 메모리 사용량과 goroutine(user service는 golang으로 작성되어 있습니다) 수가 급격히 증가하고 MySQL replica의 connection수가 치솟고 있었습니다.
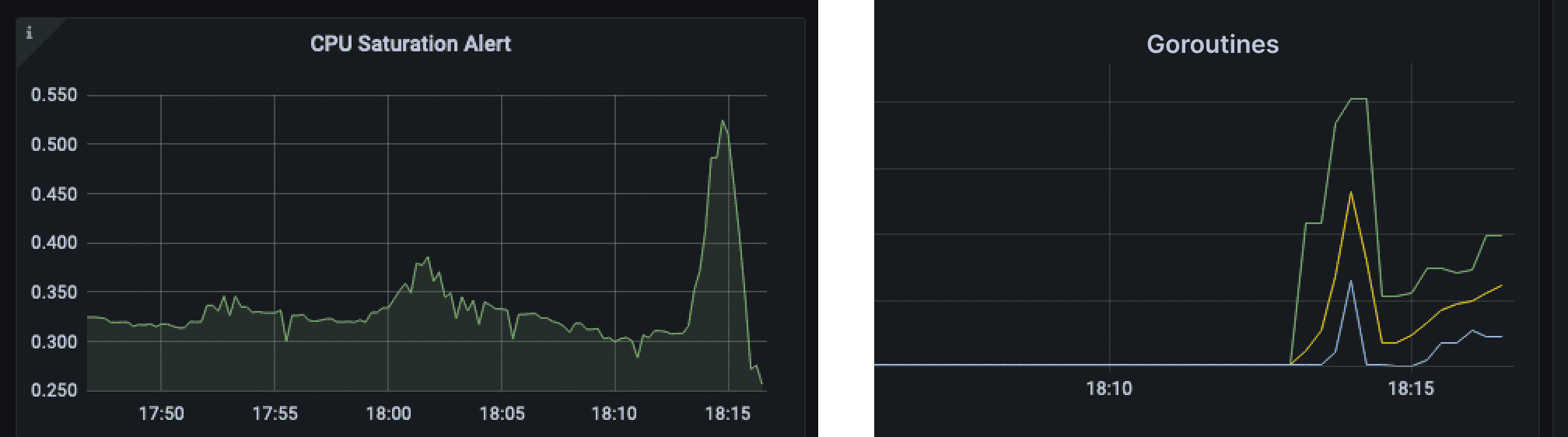

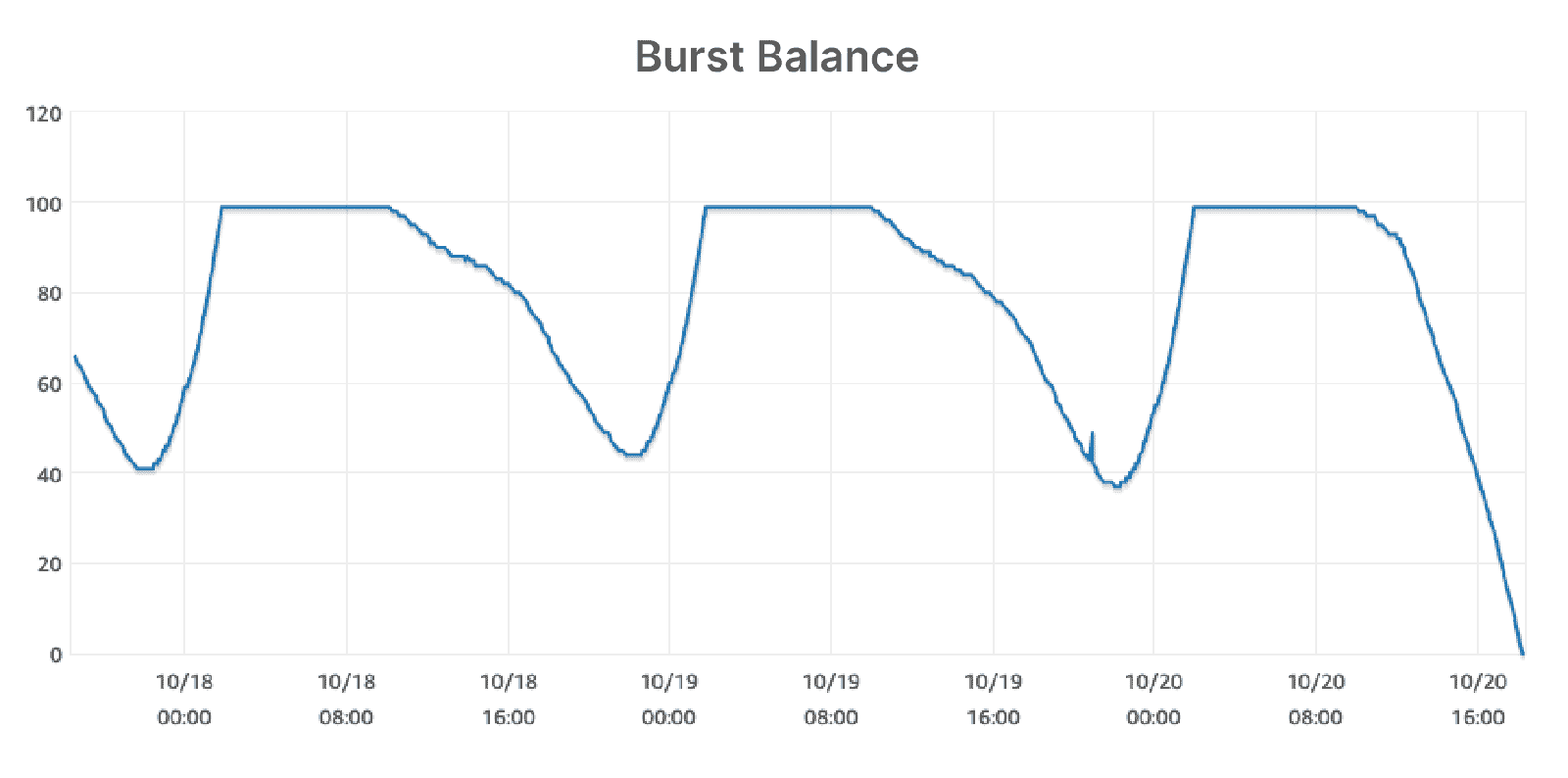
MySQL replica 쪽에 문제가 있다고 판단해 RDS 모니터를 확인해 보니 IOPS가 늘어나 burst balance가 줄어들다 0이 되어 버려 DB 성능이 급격히 떨어지고 있었습니다. 광고업 특성상 timeout이 빡빡하게 잡혀 있던 user service에 timeout 에러가 나거나 db connection 에러가 나고 있어서 에러율이 높아진 상태였습니다. 해당 인스턴스에서 사용 중인 gp2 볼륨에서는 burst balance가 RDS storage 사이즈에 연동되기 때문에 storage가 부족한 상황이 아니었음에도 storage를 증설하는 것으로 장애 상황을 빠르게 마무리 할 수 있었습니다.
높은 Disk I/O 원인 조사
storage를 늘린 후 user service가 정상화된 것을 볼 수 있었지만 여전히 왜 RDS의 disk I/O가 이렇게 높은지는 의문이 남았습니다. 3일 기간으로 burst balance를 봤을 때 주기적으로 balance가 떨어졌다 다시 올라오는 것을 확인할 수 있었습니다. 광고 요청을 받아 사용자 조회가 많아지는 낮시간에는 지속적으로 burst balance를 쓰고 있다는 뜻인데 IOPS가 이렇게까지 많아지는 것이 의심스러워 팀에서 조사를 시작했습니다.
아래 그래프는 지난 1년간 user service의 IOPS 추세입니다. 1k에서 2k로 두배가량 높아진데가 점차 증가 추세에 있습니다. 게다가 user service의 RPS는 5k 가량인데 read IOPS가 1-2k로 요청 대비 I/O 비율이 너무 높은 상태이기도 했습니다.

Disk I/O가 높으면 데이터베이스 성능에 악영향을 주고, IOPS가 증가했을 때 특정 수준을 넘으면 AWS에서 추가 비용을 청구합니다. 먼저 cache miss가 많아서 I/O가 발생했을 것이라는 가정하에 MySQL innodb의 buffer pool hit ratio를 계산해 봤습니다. innodb의 buffer pool은 메모리 내에 데이터와 인덱스를 캐싱합니다. InnoDB Buffer pool hit ratio가 낮으면 Disk에서 InnoDB Buffer pool 로 로드되는 데이터 많다는 뜻으로 cache가 miss되어 disk I/O가 높아지는 현상을 설명합니다.
1 - (innodb_buffer_pool_reads / innodb_buffer_pool_read_requests)
출처:
InnoDB의 주요 구성 요소
위와 같은 식으로 계산해 봤을 때 buffer pool hit 비율은 98%였습니다. cache miss가 많지 않은데도 디스크 I/O가 많이 일어나고 있다는 뜻이라 좀 더 알아 보기로 했습니다. 메모리 쪽 문제라고 생각해 AWS 쪽 문서를 보다 Amazon RDS best practice를 발견했습니다. 이 문서에서는 자주 사용하는 데이터와 인덱스를 뜻하는 working set가 메모리에 대부분 올라가 있어야 낮은 Read IOPS를 유지할 수 있다고 말하고 있습니다. 적절한 IOPS를 찾기 위해 AWS에서 권장하는 방식은 더 이상 IOPS가 드라마틱하게 감소하지 않는 지점까지 메모리를 Scale up 해보는 것입니다.
innodb의 데이터와 인덱스 사이즈를 다음과 같은 쿼리로 측정해 보았습니다.
SELECT FLOOR(SUM(data_length+index_length)/POWER(1024,2)) InnoDBSizeMB
FROM information_schema.tables WHERE engine='InnoDB';
user service의 데이터와 인덱스를 합친 사이즈는 170GB였습니다. 기존 RDS RAM 사이즈인 32GB로 전체 데이터 크기인 170GB 중 몇퍼센트가 working set으로 메모리에 있어야 하는지는 알기 어렵지만 팀 내에서는 메모리를 사이즈업 해보면 좋겠다는 의견을 모았습니다. 또한 IOPS burst 소진율은 gp2 EBS 타입에 따라 달라지기 때문에 저희 요구사항에 맞는 인스턴스로 변경이 필요하다고 판단해 스케일업 하게 되었습니다.
기존 인스턴스인 m5.2xlarge 와 같은 비용 수준의 인스턴스 타입 중 메모리 최적화 타입인 r6g.2xlarge으로 변경하여 메모리를 32GB → 61GB로 변경했을 때 Read IOPS가 절반 이하로 떨어졌지만 그래도 여전히 높은 상태였기 때문에, 메모리 128G의 한 단계 더 좋은 인스턴스(r6g.4xlarge)로 스케일업했습니다. r6g.4xlarge는 20000 IOPS를 제공하기 때문에 저희 요구사항에서도 여유롭게 운영할 수 있습니다. 첫 스케일업에서는 아주 가파르게 IOPS가 떨어졌지만, 두 번째 스케일업에서는 천천히 IOPS가 감소하는 것을 확인했습니다. 두 번째 스케일업 이후로는 80 IOPS를 유지하고 있습니다. 충분히 낮은 숫자라고 생각해서 더 스케일업하지 않았고 이 상태로 유지하기로 했습니다.
개선 사항
DB인스턴스에 대한 가격이 두배가 되었기 때문에 인덱스 사이즈 최적화 등을 통해 다운사이징 할 수 있을지 검토가 필요합니다. 또한 동일 요구 사항에 대해 DynamoDB같은 다른 스토리지를 썼을때 성능/가격 차이를 비교하여 개선할 수 있을 것 같습니다.
IOPS 증가 문제에 대해 팀에서 고려했던 다른 옵션은 다음과 같습니다.
-
Storage 증설. 장애 대응으로 기존 800G → 999G로 증설하여 gp2 기준 Burst IOPS에 대한 추가 비용청구를 막아둔 상태였으나 IOPS가 지속적으로 증가하는 상황에서 계속 불필요한 스토리지를 올리는게 맞는 상황이 아니라고 생각했습니다.
-
Read cache 추가. Redis같은 캐시를 추가하는 방안을 생각했는데, 시스템에 복잡도가 증가하고 캐시에 장애가 발생했을때 DB로 burst가 발생되는 상황에 대한 대책을 마련해둬야 합니다. 또한 Redis가 memory에서 처리되기 때문에 빠르지만 MySQL buffer가 충분하면 이미 대부분의 워크로드를 메모리에서 처리하는 것이나 마찬가지라 Redis 도입이 크게 장점이 없다고 판단했습니다.
시스템 복잡도와 성능 등을 고려했을때 scale up으로 right sizing을 달성하는 것이 현재 요구 사항에서 적합한 해결책이라고 판단했습니다.
스케일업 후 메트릭 변화
다음은 2번에 걸쳐 인스턴스 스케일업후 실제 DB 메트릭 변화입니다.
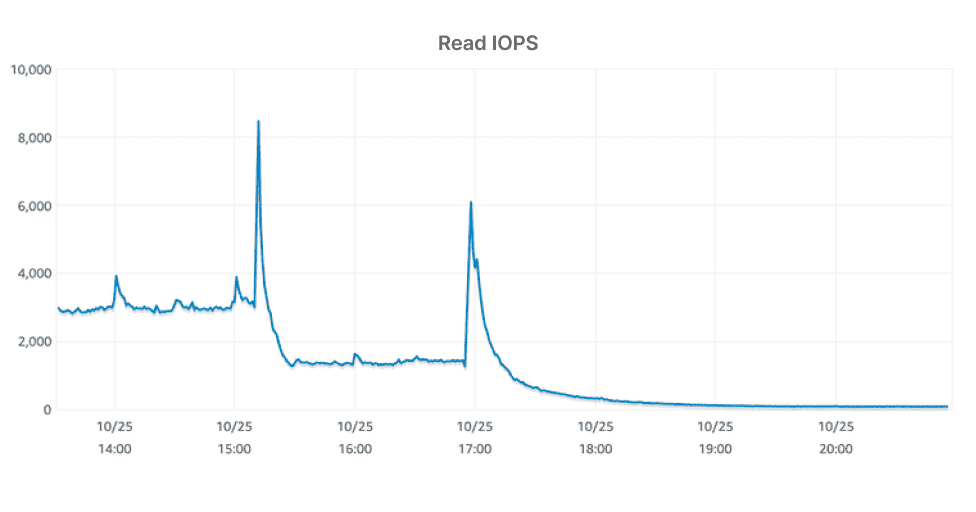
위 Read IOPS 그래프에서 보이는 두 번의 피크는 각각 인스턴스 교체 시점 입니다. 3000 가량 되던 IOPS가 첫 번째 교체에서 2000이하로, 두 번째 교체에서 80까지 떨어졌습니다. 이로써 적정 메모리 크기를 찾았다고 볼 수 있습니다.

메모리 사이즈를 키웠기 때문에 당연한 결과지만, 0에 수렴하던 Freeable memory가 두 번의 인스턴스 교체 후 여유로워졌습니다.
 Read throughput 그래프도 극적으로 변했습니다. 필요한 데이터를 buffer에서 다 처리해 주어 결과적으로 read throughput도 줄었습니다.
Read throughput 그래프도 극적으로 변했습니다. 필요한 데이터를 buffer에서 다 처리해 주어 결과적으로 read throughput도 줄었습니다.
마무리하며
데이터베이스를 운영하다 보면 이런 메모리 문제를 꼭 한 번쯤은 마주치게 됩니다. 데이터베이스의 memory size와 disk iops는 언뜻 보기에는 서로 연관이 없어보이지만 실제로는 관계가 있다는걸 배웠습니다. read iops를 최적화 할 때 지금처럼 working set이 memory에 충분히 캐싱되지 못한 경우라고 판단되면 memory size를 늘려서 최적화 할 수 있습니다. 이번에는 working set이 메모리에 다 올라가 있지 않아 Scale up으로 해결했지만 반대로 불필요하게 큰 인스턴스를 사용하는 곳에서는 Scale down으로 비용을 최적화할 수 있을것 같습니다. 이 글을 읽으시면서 다들 right sizing에 대해 한 번 더 생각해 볼 수 있는 기회가 되었으면 좋겠습니다. 또한 스케일업 해야 하는 타이밍과 기준에 대해 저희 팀에서 고려했던 부분이 다른 팀에도 도움이 되길 바랍니다. 읽어주셔서 감사합니다 :)

