
Elasticsearch 검색에서 확률 사용하기
Software Engineer
이 블로그에서는 Elasticsearch에서 검색할 때 효과적으로 각 Document에 확률을 사용하는 두 가지 방법을 설명하고,
각 방법의 간략한 성능 비교와 장단점을 설명합니다.
독자는 Elasticsearch의 Search API에 간단한 쿼리를 (term, bool 등) 작성할 수 있다고 가정합니다.
서론
버즈빌에서는 빠른 광고 서빙을 위해서 Elasticsearch에 광고를 캐싱하고 있습니다.
RPS가 높으므로 모든 광고를 inverted index에 올려놓고 광고 요청이 왔을 때 매칭되는 광고를 빠르게 찾아내는 것이죠.
광고 서버에서는 다양한 이유로 각 광고의 랜덤성을 조절해야 할 필요가 있습니다.
예를 들어 광고 A1, A2가 있고, 요청 R1, R2이 있을 때,
R1 요청을 분석해보니 A1과 A2는 각각 20%와 80% 확률로 나가야 하고, R2 요청은 A1과 A2가 각각 70%, 100% 확률로 나가야하는 경우가 발생합니다.
이러한 동적인 정보는 사전에 알 수 없으므로 inverted index에 미리 색인할 수 없습니다.
그 때문에 term, range 같은 기본적인 쿼리로는 이 목적을 달성할 수 없고, Elasticsearch에서 제공하는 다른 기능을 활용해야 합니다.
가정
핵심만 전달하기 위해 서론의 상황보다 간소화된 환경을 가정하겠습니다.
각 광고는 alloc_rate이라는 필드를 가지며 0~100의 값을 가질 수 있습니다.
이 필드는, "해당 광고는 모든 요청에서 alloc_rate% 의 확률로 할당된다"라는 의미입니다.
그 때문에 100이 설정되어있다면 모든 요청에 항상 할당되고, 10가 설정되어있다면 요청마다 10%의 확률로 할당되는 것입니다.
Elasticsearch
Elasticsearch의 Index는 아래와 같이 설정되어있다고 가정합니다. 도메인에서 정의한 것과 같이 0~100의 값을 저장합니다.
{
"settings": { ... },
"mappings": {
"properties": {
...,
"alloc_rate": {
"type": "short",
"index": true
},
...
}
}
}
방법 0. range
틀린 방법이지만 (글쓴이 포함) 쉽게 빠지는 함정이 있어서 가장 먼저 설명합니다.
바로 애플리케이션 코드에서 0~100의 랜덤한 값을 구한 후 ES query에 상수로 넣는 것입니다.
예를 들어 Python 광고 서버의 경우 아래와 같이 구현될 것입니다.
query = {
"range": {
"alloc_rate": {
"gt": random.randint(0, 99)
}
}
}
es_client.search(query)
어떤 문제가 발생할까요?
예를 들어 광고가 총 3개 있는데 모두 alloc_rate이 10이라고 가정했을 때, randint()가 10 초과일 경우 항상 3개의 광고가 모두 할당됩니다.
반대로 randint()가 10 이하일 경우 항상 3개 광고가 모두 할당되지 않습니다.
방법 1. script
첫 번째 방법은 Script query를 사용하는 것입니다.
{
"script": {
"script": "doc['alloc_rate'].value > Math.random() * 100"
}
}
쿼리 자체만 봤을 때 직관적이고 쉽게 이해할 수 있습니다.
각 Document(ES에 색인된 광고)에 대해서 [0, 1)의 랜덤값을 구하고 alloc_rate과 비교함으로써 랜덤한 할당을 구현하는 것입니다.
Document마다 랜덤값을 새로 계산하기 때문에 방법0의 문제를 해결할 수 있습니다.
하지만 Script query 공식 문서의 최상단에 적혀있는 것처럼, script query는 성능이 좋지 않습니다.
script의 성능에 관한 공식 문서에 성능 문제를 회피할 수 있는 몇 가지 방법들이 적혀있지만,
저희 경우를 해결할 수 있을법한 방법은 없습니다.
[는 열린구간,)는 닫힌구간이고[0, 1)는 0부터 1까지의 실수 중 0 포함 1 제외이고,(0, 1]은 0 제외 1 포함을 의미합니다.
방법 2. function_score
방법 0, 1의 문제를 모두 해결한 방법은 Function score query를 사용하는 것입니다.
공식 문서의
random_score설명에서 서술했듯seed와field를 설정하는 게 필요할 수 있습니다. 저희의 경우 모든 광고 할당에 서버에서 생성한 seed를 쿼리로 주입해주고 있습니다.
{
"function_score": {
"functions": [
{
"random_score": {
"field": "_seq_no",
"seed": ${some_random_value}
}
},
{
"field_value_factor": {
"field": "alloc_rate",
"modifier": "none",
"factor": 0.01,
"missing": 0
}
}
],
"score_mode": "sum",
"boost_mode": "replace",
"min_score": 1
}
}
function_score는 기본적으로 Document의 score 계산 방식을 조작할 수 있게 해주는 쿼리입니다.
이 기능을 이용해서 각 Document의 score를 랜덤하게 계산하고, 그 랜덤값을 alloc_rate과 비교하는 것입니다.
방법1도 기능만 봤을 때는 요구조건을 만족하기 때문에, function_score를 사용하는 방법 또한 같은 기능을 합니다.
쿼리를 부분별로 나눠서 역할 설명 후 전체적인 의미를 설명하겠습니다.
function_score.functions
현재 function_score는 score 계산 방식의 선택지로 아래 4가지를 제공하고 있습니다.
function_score.script_score처럼 하나의 선택지만 사용할 수 있지만,
function_score.functions에 배열 형태로 여러 선택지를 동시에 선택하고, score_mode로 선택지들의 결괏값을 어떻게 조합할지 정할 수 있습니다.
script_score- 공식 문서
- Script query와 같이 script를 각 Document의 score를 계산하는 painless 스크립트를 정의할 수 있습니다.
- Script query와 마찬가지로 성능이 좋지 않습니다.
random_score- 공식 문서
[0, 1)의 랜덤한 값을 생성합니다.
field_value_factor- 공식 문서
- Document의 특정 필드를 score로 사용할 수 있습니다.
- decay functions:
gauss,linear,exp- 공식 문서
- 어떤 기준을 정하고, Document의 특정 필드가 기준과 얼마큼 거리가 있는지를 (값이 차이 나는지) score로 사용합니다.
- 거리 계산 방식에 따라서
gauss,linear,exp로 나뉩니다.
function_score.score_mode
function_score.functions에 정의한 함수들이 각자의 score 값을 계산해낼 텐데, 그 값을 어떻게 조합해서 최종 score를 만들 것인지를 정합니다.
Python 코드로 묘사하면 아래와 같습니다. (이해를 위해 doc.score 계산 과정에서 boost_mode를 생략했습니다. 아래 해당 항목에서 최종 계산식을 확인해주세요.)
for doc in documents:
doc.score = score_mode(f(doc) for f in function_score.functions)
공식 문서에서 각각 어떤 score_mode가 있는지 확인할 수 있고,
여기서는 각 함수의 score 계산값을 모두 합하는 sum을 사용했습니다.
function_score.boost_mode
사실 function_score.score_mode가 최종 score가 되는 것은 아니고 function_score.boost_mode 연산을 한 번 더 거칩니다.
공식 문서를 보면 functions_score.query가 있어서 다른 쿼리를 중첩할 수 있고, 정의하지 않는다면 { "match_all": {} }와 같은 의미가 있습니다.
Elasticsearch에서는 아주 기본적인 term 쿼리만 날려도 score를 계산하기 때문에, query 또한 매칭되는 Document 들이 score를 가지게 됩니다.
그래서 score_mode의 결괏값과 query의 score 값 사이에도 연산이 필요할 수가 있고, boost_mode가 이때 사용됩니다.
Python 코드로 표현하면 아래와 같습니다.
for doc in documents:
query_score = ... # `function_score.query`에서 `doc`의 score
doc.score = boost_mode(
score_mode(f(doc) for f in function_score.functions),
query_score,
)
공식 문서에서 각각 어떤 boost_mode가 있는지 확인할 수 있고,
여기서는 function_score.query의 score는 무시하고 function_score.functions의 결과만 사용할 것이기 때문에 replace를 사용했습니다.
function_score.min_score
function_score.boost_mode까지 거쳐서 각 Document의 최종 score가 결정됐다면, 그 값을 기반으로 Document를 결과에서 제외할지 아닐지를 결정할 수 있는 옵션입니다.
여기서는 min_score로 1을 설정했고, 최종 score가 1 미만인 Document는 쿼리 결과에서 제외한다는 의미입니다.
정리
위의 지식 파편들로 쿼리의 동작을 설명하겠습니다.
결국 방법2는 방법1의 최적화일 뿐 의미 자체는 동일 해야 하므로 해당 부등식을 functions_score에 적용할 수 있도록 조금 손봐야 합니다.
방법1에서 조건식은 아래와 같습니다.
(alloc_rate / 100) > rand (rand는 [0, 1)를 반환하는 함수라고 정의합니다)
여기서 양변에 (1 - rand)를 더하면 아래와 같습니다.
(alloc_rate / 100) + (1 - rand) > rand + (1 - rand)
최종적으로 우변을 정리하면 아래와 같습니다.
(alloc_rate / 100) + (1 - rand) > 1
여기서 rand의 정의상 [0, 1)를 반환하기 때문에 좌변의 (1 - rand)는 (0, 1]의 값을 가질 수 있습니다.
미묘하게 다르긴 하지만 rand와 거의 같은 값의 범위를 가진다고 볼 수 있습니다.
식과 ES 쿼리를 매핑해보면, 식에서 > 1 부분을 "min_score": 1로 해결합니다.
또한 functions의 random_score가 (1 - rand) 부분을 의미하고, field_value_factor는 (alloc_rate / 100)을 의미합니다.
Document의 alloc_rate는 0100의 값이기 때문에, 이것을 01로 스케일을 줄이기 위해서 factor로 0.01을 넣었습니다.
부연설명
사실 "min_score": 1는 > 1이 아니라 >= 1로 동작합니다.
그리고 (1 - rand)는 (0, 1]이기 때문에, 식만 보면 alloc_rate이 0일 때에도 할당 가능성이 있어 보입니다.
(대입하면 0 / 100 + 1 >= 1이고, 참이기 때문에 할당 가능)
하지만 실제로는 (1 - rand) 대신 rand를 쓰고 있고, [0, 1)의 범위이기 때문에 그렇한 문제가 발생할 여지가 없습니다.
총정리하면 위의 쿼리는 (alloc_rate / 100) + rand >= 1을 의미합니다.
부록: random_score가 0이 나올 확률
random_score는 균등 분포이기 때문에 [0, 1) 구간의 모든 값이 같은 확률로 나올 수 있습니다.
그 때문에 해당 구간에서 발생할 수 있는 모든 수의 개수를 N으로 구하면 1 / N으로 0의 등장 확률을 알 수 있습니다.
수학적으로만 생각하면 해당 구간은 실수이기 때문에 구간에 등장할 수 있는 가짓수는 무한입니다.
하지만 Elasticsearch의 random_score 구현 코드를 보면,
24bit 길이 정수를 기반으로 [0, 1) 랜덤값을 결정하는 것을 알 수 있고, 그 때문에 N은 2 ^ 24 = 16,777,216임을 알 수 있습니다.
결국 대략 1 / 10,000,000 확률로 0이 나온다는 것을 알 수 있습니다.
방법 3. function_score + linear decay
방법2로도 충분히 성능을 챙기면서 기능을 구현할 수 있습니다.
하지만 field_value_factor 말고 linear decay를 사용해서 같은 기능을 서빙할 수 있고, 또 다른 용례도 있어서 소개합니다.
{
"function_score": {
"functions": [
{
"random_score": {
"field": "_seq_no",
"seed": ${some_random_value}
}
},
{
"linear": {
"alloc_rate": {
"origin": 100,
"scale": 50,
"offset": 0,
"decay": 0.5
}
}
}
],
"score_mode": "sum",
"boost_mode": "replace",
"min_score": 1
}
}
linear의 입출력 값을 예시로 설명하면, alloc_rate 값이 0일 때 0을 score로, 100일 때 1을 score로 반환하며, 20일 때 0.2를 score로 반환합니다.
공식 문서에도 그림으로 잘 설명되어있지만,
alloc_rate과 score의 관계식으로 표현하면 아래와 같습니다. (지금은 i, ii만 보시면 됩니다)
┌─ 0 i) alloc_rate < 0 or alloc_rate > 200
│
score = ┼─ alloc_rate / 100 ii) 0 <= alloc_rate <= 100
│
└─ 2 - alloc_rate / 100 iii) 100 < alloc_rate <= 200
때문에 방법2와 같이 (alloc_rate / 100) + rand >= 1를 평가합니다.
또 다른 사용 사례
0일 때 할당을 막고 100일 때 할당하는 alloc_rate과 반대로 100일 때 할당을 막고 0일 때 할당해야하는 경우에는 어떻게 쿼리 해야 할까요?
예산의 소진 상태가 그러한 값을 가질 수 있습니다. 0%라면 예산이 하나도 쓰이지 않은 상태이고, 100%면 모든 예산을 소진했다는 의미입니다.
당연히 0%일 때는 ES 검색 결과에 나와야 하지만 100%라면 더 이상 소진이 되지 않도록 결과에 포함되면 안 됩니다.
위의 할당 조건을 부등식으로 표현하면 아래와 같습니다.
1 - budget / 100 > rand
부등식을 요리조리 수정하려 해도 Elasticsearch에서는 음수 score를 지원하지 않기 때문에 field_value_factor만으로는 해당 조건문을 구현할 수 없습니다.
이때 공식 문서의 linear 그래프를 보면,
origin보다 값이 큰 경우 기울기가 음수임을 알 수 있습니다.
이것을 이용해서 origin을 0으로 설정하면, budget이 0일 때 1의 score를, 100일 때 0의 score를 얻을 수 있습니다.
{
"function_score": {
"functions": [
{
"random_score": {
"field": "_seq_no",
"seed": ${some_random_value}
}
},
{
"linear": {
"budget": {
"origin": 0,
"scale": 50,
"offset": 0,
"decay": 0.5
}
}
}
],
"score_mode": "sum",
"boost_mode": "replace",
"min_score": 1
}
}
성능 비교
실제 프로덕션 광고 할당에 쓰이는 쿼리 일부분을 방법3의 linear decay와 방법1의 script의 성능을 비교해보겠습니다.
비교하기에 앞서 Elasticsearch는 접근 패턴과 데이터의 형태에 따라서 성능이 달라질 수 있음을 먼저 밝힙니다.
저희의 경우 총 라이브 광고가 엄청 많지 않고, write 대비 read가 압도적으로 큰 상황입니다.
아래의 결과는 Kibana의 Query Profiler를 사용했습니다.
방법1의 script
전체 쿼리의 수행시간 중 33%가 script 쿼리에 사용됐으며, 가장 오래 걸리는 쿼리가 됐습니다.

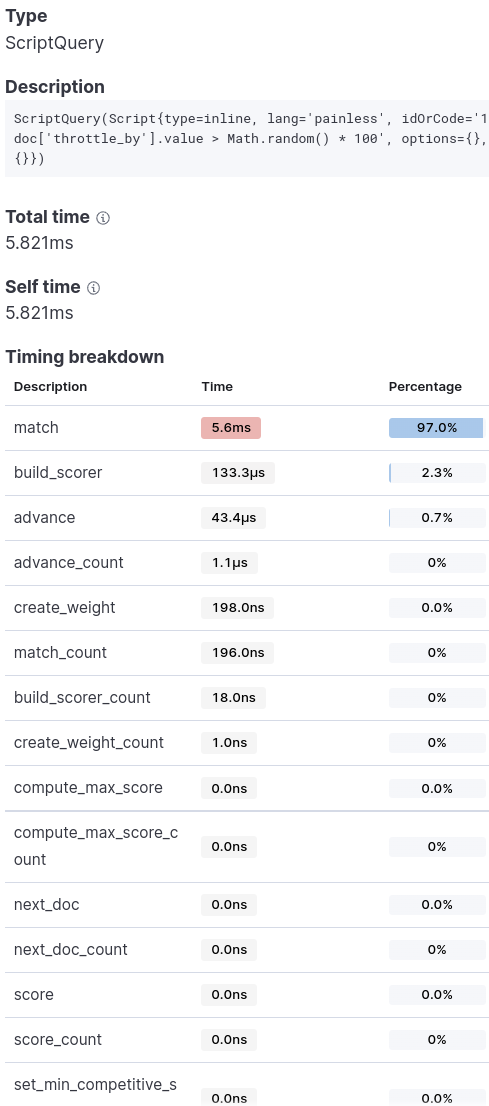
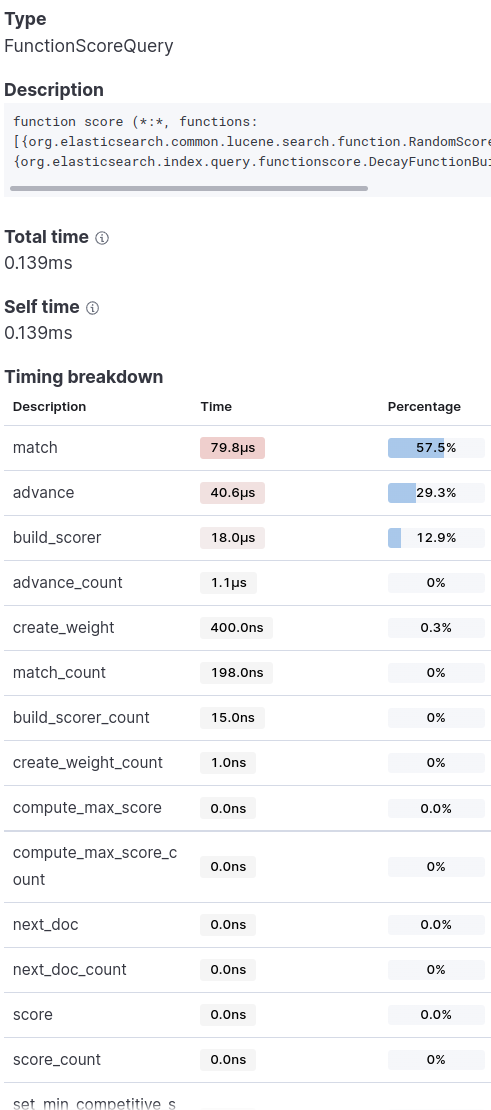
방법3의 linear decay
script 대비 40배 넘게 최적화됐고, 소요 시간이 쿼리 중에서도 하위권에 속합니다.

장단점
script vs function_score로 봤을 때, function_score가 항상 성능이 좋습니다.
하지만 function_score를 거치면 각 Document score가 [0, 1)로 계산되는 단점이 있습니다.
저희의 경우 scoring을 사용하지 않는 filter context를 사용하고 있어서 이런 단점은 문제가 되지 않았습니다.
마치며
function_score.query까지 커스텀하면 서론에서 설명했던 좀 더 복잡한 확률 시나리오도 효율적으로 구현해낼 수 있습니다.
실제 광고 할당 서버에서는 이 쿼리를 거의 모든 확률 쿼리에 사용하고 있습니다.
성능 비교 문단에도 적었지만, 인덱싱 구성과 접근 패턴에 따라서 ES는 상당히 다른 성능 결과를 볼 수 있습니다. 심지어 어떤 경우는 script를 사용하는 게 일반 쿼리를 조합하는 것보다 더 빠른 경우도 있습니다. 사용 사례에 따라서 다양한 쿼리와 인덱싱 구성을 테스트해 보시고 적용하는 것을 추천해 드립니다.

