
상품 추천 알고리즘 Item-CF의 최적화 여정
Machine Learning Engineer
만 30개의 이커머스을 광고주로 삼고 있는 버즈빌. 이들을 위한 리타겟팅 광고 솔루션을 고도화하기 위해 도입된 상품 추천 알고리즘: Item-CF. 이 알고리즘 최적화와 적용 과정에 대해서 알아보겠습니다.
버즈빌의 리타겟팅 광고 솔루션
버즈빌에서는 매출의 20% 이상을 리타겟팅 광고 상품으로 발생시키고 있습니다. 전통적으로는 리타겟팅 광고는 유저가 이커머스 플랫폼에서 관심을 보였던 상품을 그대로 광고 지면에 보여줘서 광고 클릭과 상품 구매를 유도하는 광고 솔루션입니다.
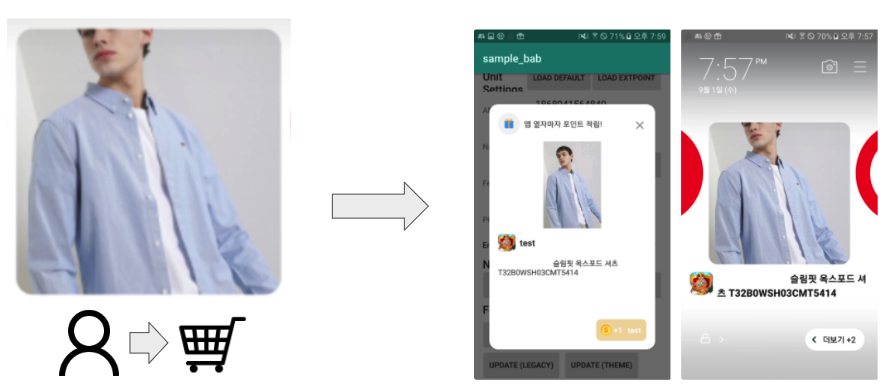
리타겟팅 광고의 예시. SSG에서 유저가 상품을 장바구니에 담고, 버즈빌의 광고 지면에 들어오게 된다면 동일한 상품을 광고 소재로 보게 된다.
버즈빌에서는 홈쇼핑부터 쿠팡 등의 대형 종합 커머스 몰까지 30개에 이르는 다양한 이커머스를 대상으로, 맞춤형 리타겟팅 광고 솔루션을 제공하고 있습니다. 이런 개인화된 광고를 보여주기 위해, 각 커머스에서부터 유저와 상품 간의 활동 이력을 3rd-party 데이터로 받고 있습니다. 이 데이터를 기반으로, 유저가 본 상품을 위 이미지처럼 그대로 보여주는 전통적인 방법보다, 추가 구매를 유도할 수 있는 다른 상품을 찾아 보여주는 방법이 있는지 고민해봤습니다. 결국, 버즈빌에서는 리타겟팅을 추천 문제로 삼아, 머신러닝으로 이를 풀어볼 수 있는지 연구와 개발을 꾸준히 해오고 있습니다. 그 과정에서 도입된 Item-CF 알고리즘을 Python으로 구현한 과정과, 대규모의 이커머스들에게도 Scale-out이 가능하도록, 최적화 방안들에 대해서 소개해드리겠습니다.
Item-CF란?
Item-CF는 Collaborative Filtering (CF) 이라는 추천 알고리즘의 Item 중심적인 유형입니다. CF나 Item-CF의 간단한 이해를 위해 유저와 아이템 간의 Interaction Matrix를 상상해보겠습니다. 가상의 이커머스에 대한 Interaction Matrix를 예시를 들어 설명해보겠습니다.
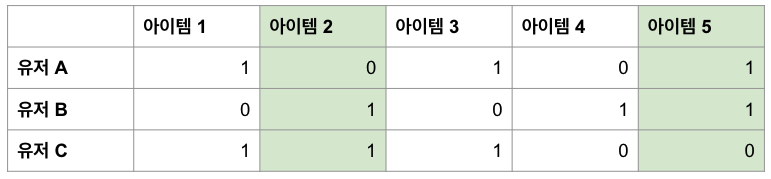
3명의 유저와 5개의 상품만을 가진 가상의 이커머스의 Interaction Matrix. 예시로 상품 2와 5의 벡터를 초록새으로 표시.
각 유저가, 각 상품을 샀으면 1, 안 샀으면 0으로 각 셀을 기입을 했습니다. 각 행은 각 유저를 뜻하는 벡터이고, 각 열은 각 아이템을 뜻하는 벡터가 됩니다. 여기서 CF의 직관은 비슷한 유저는 비슷한 상품 구매 패턴을 가질 것이다라는 것입니다. 그러면 한 유저에 대해 추천을 하려면, 그 유저와 가장 비슷한 유저들을 찾아, 그 사람들이 구매한 상품을 보여줍니다.
이와 달리 Item-CF는 비슷한 유저들이 아닌 비슷한 아이템들을 찾는 기법입니다. 각 아이템에 대하여, 제일 비슷한 아이템들을 기록하는 Item Similarities 테이블을 만들고, 실제 추천 상황일 때, 유저가 이전에 구매한 아이템들로 테이블을 조회해서 나오는 가장 비슷한 아이템들을 보여줍니다.
Item-CF는 아마존에서 20년 전에 널리 퍼뜨린 알고리즘으로 유명합니다. 더 디테일한 CF와 Item-CF에 대한 정보를 얻기 위해서는 아마존의 원본 논문을 참고하는 것을 추천합니다. 다음 섹션에서는, 이 논문에서 공유한 Item Similarities 테이블을 만드는 알고리즘을 구현하고 최적화한 것에 대해서 다루겠습니다.
Python으로 재구현하기
similar_items_table = defaultdict(list)
for product in product_catalog:
products_bought_together = set()
for user in users_who_purchased_product[product]:
for product_bought_together in products_purchased_by_user[user]:
products_bought_together.add(product_bought_together)
for product_bought_together in products_bought_together:
score = cosine_similarity(product, product_bought_together)
similar_items_table[product].append((product_bought_together, score))
논문에서는 Pseudocode로 공유를 한 것을 Python으로 재구현했습니다. 이 코드는 위 예시의 커머스나 버즈빌의 가장 작은 이커머스들 대상으로는 문제없이 돌아갔습니다. 하지만 유저들이 60만 명, 상품들이 40만 개가 되는 저희 중간 스케일의 이커머스에 대해서는 같은 말을 할 수 없었습니다. 알고리즘이 걸리는 시간이 무려 300일이 예상되었습니다.
최적화 #1: Sparse Vectors
10줄 이내의 Python 코드를 보면 최적화할 수 있는 부분이 쉽게 보이지는 않았습니다. 사실상 For-Loop들 이외에 최적화 할 수 있는 부분은 라인 9, 즉 두 아이템 벡터 간의 Similarity를 계산하는 부분이었습니다. Similarity를 계산하는 수식을 보면서 생각해보겠습니다.
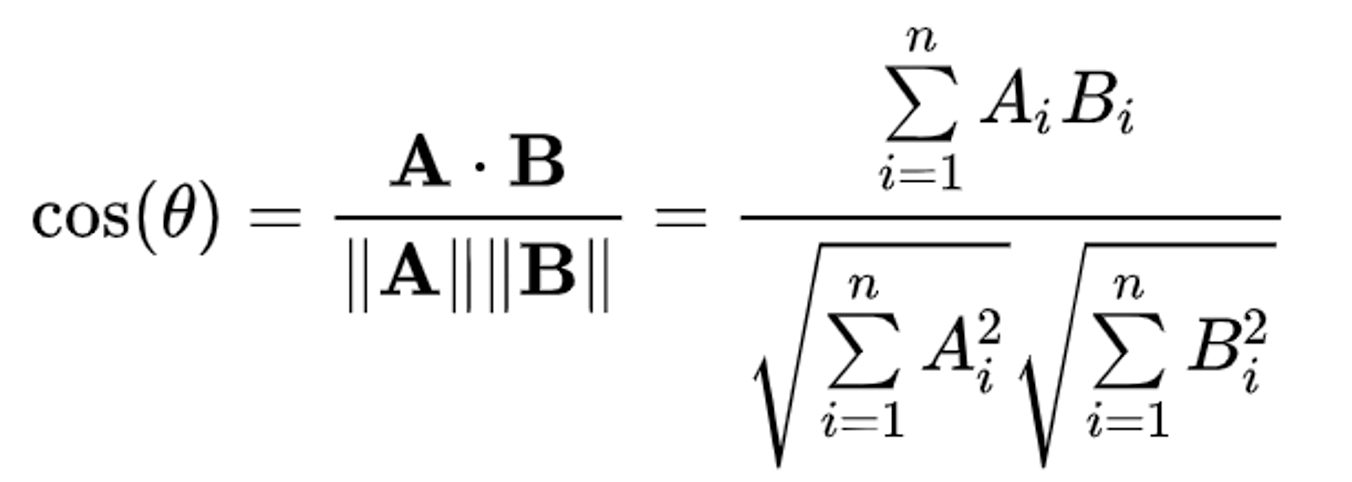
분자를 구할 때 A와 B 벡터의 각 디멘션을 (i) 참조를 해야 하는 상황입니다. 하지만, 각 벡터의 디멘션 중 하나라도 0이라면 곱해지는 현상 때문에 마지막 결과에 0을 더하는 케이스가 돼버립니다. 0을 더하는 경우는 굳이 계산을 안 해도 된다는 인사이트와 함께, A와 B 벡터에서 같은 디멘션이 둘 다 0이 아닐 경우에만 연산하면 됩니다. 따라서, 벡터에 0이 많을수록, 즉 벡터가 Sparse 할수록, Cosine Similarity 계산의 Time complexity는 줄어드는 것입니다.
좋은 소식은 실제 이커머스들의 유저와 아이템 간의 Interaction Matrix를 보면, 대부분의 유저와 아이템 벡터들은 매우 Sparse 합니다. 전형적인 커머스에서는 대부분의 유저는 전체 상품 중 극소수의 상품들을 구매하며, 마찬가지로 대부분의 아이템은 극소수의 유저들에게만 구매가 됩니다. (물론, 생수 같은 상품은 정말 많은 사람에게 구매될 수가 있어, 해당 아이템 벡터는 Dense 합니다. 이러한 Dense 벡터는 하지만 전체 벡터 중 1%도 안 되었습니다)
결과적으로, 아이템 벡터들을 Sparse Vector 형식으로 저장하고, Cosine Similarity 계산 로직을 Sparse Vector 들을 대상으로 빠르게 계산할 수 있도록 로직을 바꾸었습니다.
from scipy.sparse import csr_matrix
from sklearn.metrics.pairwise import cosine_similarity
# Use sparse vector format
a = csr_matrix(...) # instead of np.array([0,0,...,0])
b = csr_matrix(...)
similarity_score = cosine_similarity(a, b) # 6x faster!
다행히 Sparse Vector 형태나 실제 Similarity 계산 로직을 재구현할 필요는 없었습니다. 기존에 Scipy와 Scikit-Learn 라이브러리들에서의 Sparse Vector 포맷을 쓰기만 하면, Cosine Similarity 계산은 내부적으로 알아서 최적화를 해주었습니다.
평균적으로, 6배 정도 빨라졌습니다. 이제 300일이 아닌, 50일밖에(?) 안 걸렸습니다. 하지만, 실제 광고 서비스에 도입하기에는 아직 너무 느렸습니다.
최적화 #2: Embarrassingly Parallel Workload
첫 번째 줄에 있는 For-Loop은 순차적으로 돌아야 하는지 확인해봤습니다. Item Similarities 테이블을 위해서 아이템 1번의 가장 Similar 한 아이템 벡터들을 구하는 작업을 할 때, 2번 아이템에 대한 작업은 굳이 1번에 대한 작업이 끝난 후 시작할 필요는 없었습니다. 모든 아이템은 독립적으로 Similarity 계산을 할 수 있다는 인사이트를 얻었습니다. Item-CF 알고리즘은 Embarrassingly Parallel한 Workload이었습니다.
따라서, 알고리즘의 Distributed 버전을 써서 최적화를 진행했습니다. Python 개발 환경 안에서 가장 쉽게 적용해볼 수 있는 Distributed Computing Framework를 찾는 와중, Ray라는 Framework를 적용했습니다.
import ray
ray.init()
# Put variables into shared memory using `put`
users_who_purchased_product_ref = ray.put(users_who_purchased_product)
products_purchased_by_user_ref = ray.put(products_purchased_by_user)
@ray.remote # Decorator turns regular function into asynchronous function
def compute_partial(partial_product_catalog, users_who_purchased_product, products_purchased_by_user):
partial_table = defaultdict(list)
for product in partial_product_catalog:
products_bought_together = set()
for user in users_who_purchased_product[product]:
for product_bought_together in products_purchased_by_user[user]:
products_bought_together.add(product_bought_together)
for product_bought_together in products_bought_together:
score = cosine_similarity(product, product_bought_together)
partial_table[product].append((product_bought_together, score))
return partial_table
# Split products e.g. If you had 10 products, you can call compute_partial() twice - first for 1~5, second for 6~10
futures = [compute_partial(partial_product_catalog_part_1, users_who_purchased_product_ref, products_purchased_by_user_ref),
compute_partial(partial_product_catalog_part_2, users_who_purchased_product_ref, products_purchased_by_user_ref),
...]
ray.get(futures) # After this line, `futures` has all partially computed similarities.
다른 Framework 후보들로 Spark와 Dask를 고려했지만, Spark는 Python 밖에서 JVM 클러스터 환경을 배포와 운영을 해야 한다는 큰 셋업 비용 때문에 피했고, Dask는 자체 Dask Dataframe, Dask Array 등의 데이터 타입을 써야 한다는 제약 때문에 피했습니다. 위 코드 블록에서 보이듯이 Ray를 썼을 때는 기존 알고리즘을 최소한의 변경으로 분산 처리 가능한 버전으로 전환할 수 있었습니다.
결론적으로, Item-CF 알고리즘을 CPU 코어 개수만큼 분산 처리가 가능하여지도록 만들어 런타임을 50일에서, EC2의 대규모 r5.12xlarge 인스턴스를 써서, 4시간으로 줄일 수 있었습니다!
r5.12xlarge의 48개의 코어들이 열심히 달리고 있는 모습 :running:
Single-core vs Multi-core 최적화
지금까지, Item-CF에 대한 간략한 소개와 해당 알고리즘을 Python으로 재구현하면서, 버즈빌의 리타겟팅 광고 시스템에 도입하기 위한 2가지의 최적화 방안을 소개했습니다. Sparse Vector를 쓸 수 있으면 이에 관여하는 로직의 공간 복잡도와 시간 복잡도를 줄일 수 있다는 것을 봤습니다. 더불어, Ray를 통해, 비교적 간단하게, Custom 한 Python 알고리즘을 Distributed 버전으로 치환했습니다.
이번 Item-CF를 최적화하고 상용화하는 과정을 전체적인 관점에서 돌이켜봤을 때, 다시 한번 Distributed 알고리즘의 개발 및 디버깅의 높은 난이도를 체감하게 됬습니다. Ray처럼 아무리 비교적 쉬운 Framework를 쓰더라도, 분산 처리의 최적화 작업은 Single-core 레벨에서의 최적화 작업에 비해 개발 시간이 배로 더 많이 들었습니다. 이를 삼아, 알고리즘 최적화는 Single-core 레벨부터 먼저, 그다음에 Multi-core 관점으로 접근하시는 것을 추천해 드립니다.
추천은 복잡한 문제
마지막으로, 버즈빌의 독특한 위치에 기반하여, Item-CF가 다른 추천 ML 알고리즘에 비해 주었던 장점에 대해서 소개해보겠습니다. 동일한 상품 추천이라는 문제를 풀고 있지만, 버즈빌은 광고 회사이지, 이커머스 회사가 아닙니다. 버즈빌의 ML 팀은 하나의 상품 카탈로그에 대해서 추천 문제를 풀고 있지 않고, 무려 30개의 카탈로그에 대한 문제를 풀려고 하고 있습니다. 따라서, 저희가 도입하는 ML 모델이나 추천 솔루션의 제일 중요한 성질 중에 하나는 Robustness입니다. 버즈빌의 추천 시스템은 하나의 광고주가 아닌, 모든 광고주를 만족시킬 수 있어야 합니다. 특히, 만년 리소스 부족이라는 스타트업 환경에서는, 다른 도메인에 적용할 때도 추가 비용 없이 도입할 수 있는 ML 모델들이 절실합니다.
Item-CF는 이런 니즈를 만족했습니다. 유저와 상품 간의 Interaction 들만을 가지고 모든 이커머스에 대해서 높은 질의 추천 결과를 만들어낼 수 있었습니다. 유저 성별과 나이, 상품 가격, 상품 카테고리, 등, 다른 메타데이터를 피쳐로 쓰지 않고 있습니다. 물론, Netflix나 Spotify 같은 타회사들의 사례처럼, 유저와 아이템 간의 Interaction 들과 더불어 이런 메타데이터를 썻을 때 추천 성능을 더 높일 수는 있습니다. 하지만, 이런 회사들에 비해 버즈빌이 다른 점은 바로 메타데이터의 데이터 퀄리티가 보장이 안 되어 있다는 것입니다. Interaction 데이터에 비해 메타데이터의 퀄리티는 제공해주는 이커머스마다 큰 차이가 있는 게 현실입니다. 버즈빌 추천 모델의 성능 관점에서는 이런 메타데이터는 긍정적인 첨가물보다는 병목의 원인에 더 가깝습니다.
결론적으로, 추천이라는 문제는 각 회사의 비즈니스 특색과 데이터 퀄리티에 기반하여 풀어야 하는 문제임을 한 번 더 강조하고 싶습니다. Applied ML은 Research ML과 달리, 순수 성능과 더불어, Robustness 같은, 더 실용적인 측면도 측정해야 합니다. 또한 SOTA를 달성하는 화려한 논문들에 현혹되지 말고, 모든 것을 다 해결할 수 있는 만능 추천 모델은 없다고 얘기하고 싶습니다. Item-CF도 절대 그런 모델은 아니니까요 :) 필요한 피쳐 대비 높은 질의 추천 퀄리티를 보장해주는 일명 가성비가 높은 모델이라고 생각하시기 바랍니다.
버즈빌에서 광고와 상품 추천의 문제가 흥미롭께 느껴진다면:

