
DynamoDB Limit 설정으로 RCU 97% 절감한 이야기
Server Engineer
안녕하세요, 버즈빌 Supply Platform 팀의 Jed입니다.
대규모 트래픽 환경에서 낮은 지연 시간과 높은 가용성은 중요한 요소입니다. 따라서 버즈빌에서는 "Single-digit millisecond performance at any scale"의 DynamoDB를 적극 활용하고 있습니다.
이 글에서는 DynamoDB RCU(Read Capacity Unit) 급증 이슈의 원인을 추적하고 해결책을 찾아가는 과정을 공유하고자 합니다. 비슷한 상황을 겪고 계신 분들께 도움이 되길 바랍니다.
TL;DR
- 상황: RCU ~1k → 130k RCU/s (130배 증가)
- 원인:
Limit미설정 + 불필요한 Strong Consistent Read- 해결:
Limit적용 + Eventually Consistent Read 전환- 결과: RCU 87~97% 절감
문제 발견과 원인 분석
1. 리포팅과 메트릭 확인
2025년 9월 초, 데브옵스 팀의 리포팅을 계기로 본격적인 원인 분석을 시작했습니다. 먼저 Datadog으로 RCU 사용량 추이를 분석한 결과, 특정 시점 이후 RCU가 점진적으로 증가한 것을 확인했습니다.
# RCU 추이 (A 테이블 + C 테이블 합산)
2025-05-01: ~1k RCU/s
2025-05-23: ~6k RCU/s (점진적 증가 시작, A 테이블 ~5k + C 테이블 ~1k)
2025-09-04: ~35k RCU/s (리포팅 시점, A 테이블 ~15k + C 테이블 ~20k)
2025-10-30: ~130k RCU/s (대형 매체사 오픈 후 최고점, A 테이블 ~60k + C 테이블 ~70k)
2025-11-07: ~10k RCU/s (최적화 배포 후, A 테이블 ~8k + C 테이블 ~2k)
2. 원인 추적
2.1 일단위 RCU 메트릭
| 날짜 | 평균 | 최대 | 오전 | 오후 | 비고 |
|---|---|---|---|---|---|
| 01-15 | 241 | 573 | 300 | 270 | 안정 상태 |
| ... | ... | ... | ... | ... | ... |
| 05-23 | 1,790 | 4,330 | 1,000 | 3,000 | 사용량 증가 |
| ... | ... | ... | ... | ... | ... |
| 10-27 | 11,800 | 23,800 | 16,000 | 10,000 | 최고점 |
이 표를 다음과 같이 활용할 수 있었습니다.
- 증가 시점 특정: 5월 23일 오후 2시 10분경 2.5k RCU 돌파
- 시간대별 패턴: 오후~저녁 시간대에 RCU가 더 높음
- 팀 공유: 명확한 근거 자료로 활용
2.2 배포 이력 자동화 추적
RCU 증가 시점과 배포 이력의 상관관계를 파악하기 위해 AI를 활용한 PR 분석을 진행했습니다. 다만 AI의 비결정적인 특성을 보완하기 위해 GitHub CLI 스크립트를 작성하여 명확한 산출물을 확보했습니다.
# 특정 날짜의 배포에 포함된 PR 목록을 자동 추출
function find_deployments() {
# ... 배포 조회
}
function find_merged_prs() {
# PR 조회
gh pr list --state merged --search "$sha" --base master \
--json number,title | jq -r '.[] | @tsv'
}
이 스크립트로 수동 확인 시 며칠 걸릴 작업을 자동화하여 원인 후보군을 빠르게 도출했습니다.
여담: 같은 달 네이선께서 SDD(Spec Driven Development)를 소개해 주셨는데, 스펙 문서로 컨텍스트를 명확히 관리하여 AI의 비결정적 특성을 보완할 수 있다는 점이 인상적이었고, 이후 AI 활용 시 스펙 기반으로 컨텍스트를 관리하고 있습니다.
2.3 다중 서비스 배포 매트릭스
두 테이블을 직접 조회하는 5개 서비스의 배포 이력을 1월부터 9월까지 날짜별로 교차 분석했습니다.
| 날짜 | A 서비스 | B 서비스 | C 서비스 | D 서비스 | E 서비스 |
|---|---|---|---|---|---|
| 01-17 | #xxx | ||||
| ... | ... | ... | ... | ... | ... |
| 03-18 | #xxc | ||||
| ... | ... | ... | ... | ... | ... |
| 05-23 | #xxa | #xxb | |||
| ... | ... | ... | ... | ... | ... |
| 09-04 |
3. 의심 PR 발견
매트릭스 분석을 통해 3월 18일 머지된 C 서비스 PR이 의심 후보로 떠올랐습니다. 해당 PR을 분석한 결과, 두 가지 문제를 발견했습니다.
- Limit 미설정: 파티션 전체(평균 300개)를 순회
- Strong Consistent Read 추가: Eventually Consistent 대비 2배의 RCU 소비
// 문제의 코드
iter := r.table.Get("user_id", userID).
Order(dynamo.Descending).
Consistent(true). // 문제 2: Strong Consistent Read
Iter() // 문제 1: Limit 없이 전체 순회
Q: 3월에 머지했는데 왜 9월에야 발견되었나?
A: 코드 변경 자체는 잠재적 문제였고, 트래픽이 점진적으로 증가하면서 9월에 이상 징후가 눈에 띄게 되었습니다. 이후 10월 말 대형 매체사 오픈으로 트래픽이 급증하면서 비용 문제가 본격화되었습니다.
나아가 이 두 가지가 실제로 RCU 폭증을 일으키는지 확인하려면, DynamoDB Query의 동작 원리를 이해할 필요가 있습니다.
DynamoDB Query 동작 원리
1. Query API 내부 동작
DynamoDB Query API는 다음과 같이 동작합니다.
- 1MB 단위 페이징: 한 번의 Query 호출로 최대 1MB의 데이터만 반환 ("a maximum of 1 MB")
- Limit의 의미: 스캔할 최대 아이템 수 (필터링 전에 적용)
- RCU 계산 기준: 실제 반환된 데이터가 아닌, 스캔한 데이터 크기 기준
| Read 타입 | 4KB당 RCU |
|---|---|
| Eventually Consistent | 0.5 RCU |
| Strong Consistent | 1 RCU |
DynamoDB는 아이템 크기를 4KB 단위로 올림하여 RCU를 계산합니다.
이번 케이스의 파티션당 평균 아이템 수는 약 300개, 아이템 평균 크기는 400 bytes입니다. 요청 한 번에 최대 1MB까지 스캔하기 때문에, 평균 120KB(400 bytes × 300개) 규모의 파티션 전체를 스캔할 수 있는 상태였습니다.
2. guregu/dynamo 라이브러리
버즈빌에서는 아래 장점들을 고려해 guregu/dynamo를 적극 활용 중입니다. AWS SDK를 직접 사용하는 것 대비 주요 장점을 소개합니다.
2.1 Struct Binding
AWS SDK
// 필드별 수동 타입 변환 필요
output, _ := client.GetItem(&dynamodb.GetItemInput{...})
if v, ok := output.Item["UserID"]; ok && v.N != nil {
user.UserID, _ = strconv.Atoi(*v.N) // 각 필드마다 반복...
}
guregu/dynamo
type User struct {
UserID int `dynamo:"UserID,hash"`
CreatedAt time.Time `dynamo:",unixtime"`
}
// 타입 안전성과 자동 직렬/역직렬화
err := table.Get("UserID", 123).One(&user)
2.2 Chainable API
AWS SDK
// Expression 문자열 + AttributeValues 맵 조합
input := &dynamodb.QueryInput{
KeyConditionExpression: aws.String("UserID = :uid AND #time >= :t"),
ExpressionAttributeNames: map[string]*string{...}, // 예약어 이스케이프
ExpressionAttributeValues: map[string]*dynamodb.AttributeValue{...},
}
result, err := client.Query(input)
guregu/dynamo
// 메서드 체이닝으로 직관적 표현
err := table.Get("UserID", 613).
Range("Time", dynamo.GreaterOrEqual, "2025-01-01").
Order(dynamo.Descending).Limit(10).All(&results)
2.3 Pagination 추상화 (aka Limit 누락의 시작점)
AWS SDK
// LastEvaluatedKey 루프를 직접 구현
for {
output, err := client.Query(&dynamodb.QueryInput{ExclusiveStartKey: lastKey, ...})
// ...
if output.LastEvaluatedKey == nil { break }
lastKey = output.LastEvaluatedKey
}
guregu/dynamo
iter := table.Get("UserID", 613).Iter()
for iter.Next(&result) {
// 응답 처리
}
Iter()와 All() 모두 내부적으로 LastEvaluatedKey를 확인하며 페이지를 자동으로 순회합니다.
함정: Iter()를 사용하면 for 루프에서 break로 일찍 빠져나올 수 있어, iteration 횟수만큼만 RCU가 소비되는 것처럼 오해할 수 있습니다.
// 3번만 iteration하면 3개만 조회하는 것 아닌가?
iter := table.Get("UserID", 613).Iter()
for iter.Next(&result) {
results = append(results, result)
if len(results) >= 3 {
break // 여기서 끊으면 3개만 조회한 거 아닌가?
}
}
실제로 라이브러리 내부를 보면, Next()는 페이지 단위로 조회한 결과를 순회합니다.
// guregu/dynamo v1.20.2 query.go - NextWithContext (간략화)
func (itr *queryIter) NextWithContext(ctx context.Context, out interface{}) bool {
// 1. 이미 조회한 결과가 있으면 버퍼에서 반환 (추가 Query 없음)
if itr.output != nil && itr.idx < len(itr.output.Items) {
itr.idx++
return true
}
// 2. 버퍼가 비었으면 DynamoDB Query 실행 (여기서 RCU 소비!)
itr.output, _ = client.QueryWithContext(ctx, itr.input)
// ...
}
즉, 첫 Next() 호출 시 DynamoDB Query가 실행되어 페이지 전체(최대 1MB)를 조회하고, 이후 Next()는 이미 가져온 결과를 순회만 합니다. break로 3개만 사용해도 페이지 전체에 대한 RCU는 이미 소비된 상태입니다.
3. DynamoDB Query API의 Limit, 제대로 전달하기
3.1 라이브러리 내부 구현
guregu/dynamo는 DynamoDB Query API의 Limit 파라미터를 두 개의 메서드로 제공합니다. Limit()과 SearchLimit(). 둘 다 동일한 API 파라미터로 전달되지만, 전달 조건이 다릅니다.
// guregu/dynamo v1.20.2 query.go - queryInput 메서드
func (q *Query) queryInput() *dynamodb.QueryInput {
req := &dynamodb.QueryInput{...}
// ...
if q.limit > 0 {
if len(q.filters) == 0 { // ⭐ 필터가 없을 때만 전달
req.Limit = &q.limit
}
}
if q.searchLimit > 0 {
req.Limit = &q.searchLimit // ⭐ 항상 전달
}
// ...
return req
}
3.2 Limit만 사용 시 페이징 동작
필터가 있으면 DynamoDB가 n개를 스캔해도 필터링 후 결과가 n개보다 적을 수 있습니다. 그래서 라이브러리는 클라이언트에서 원하는 개수가 모일 때까지 페이징을 반복합니다.
// guregu/dynamo v1.20.2 query.go:344-386 (간략화)
func (itr *queryIter) NextWithContext(ctx context.Context, out interface{}) bool {
if limit 도달 (n개 수집 완료) { return false }
if 현재 페이지에 아이템 남음 { return true }
// SearchLimit: 추가 페이지 요청 X
if 더 이상 페이지 없음 || searchLimit > 0 { return false }
// Limit만 설정: 다음 페이지 요청 후 계속 반복
itr.input.ExclusiveStartKey = itr.output.LastEvaluatedKey
}
핵심은 searchLimit > 0이면 한 번의 API 호출로 중단하고, 그렇지 않으면 itr.n이 limit에 도달할 때까지 페이지를 계속 요청한다는 점입니다.
3.3 페이징 시나리오 비교
Limit(10).Filter(...) 사용
[1차] Limit 미전달 → 1MB까지 스캔 → 필터 후 3개 → "7개 더 필요" → 다음 페이지
[2차] Limit 미전달 → 1MB까지 스캔 → 필터 후 5개 → "2개 더 필요" → 다음 페이지
[3차] Limit 미전달 → 1MB까지 스캔 → 필터 후 4개 → "10개 도달!" → 중단
총 스캔: 최소 768개 → RCU 폭발 (아이템 4KB 이하 기준)
SearchLimit(10) 사용
[1차] Limit=10 전달 → 10개만 스캔 → 끝
총 스캔: 10개 → RCU 절감 ✅
Limit vs SearchLimit
메서드 Limit 전달 페이징 동작 RCU 영향 Limit(n)필터 없을 때 n개까지 반복 필터 시 전체 스캔 위험 SearchLimit(n)항상 n개 스캔 제한 서버 측 스캔 제한 권장: RCU 최적화가 필요하다면
SearchLimit을 명시적으로 설정하세요.Limit만 사용하면 필터 유무에 따라 DynamoDB API에 전달되지 않을 수 있고, 이 경우 파티션 전체를 스캔하게 됩니다.
해결 전략 수립
1. 비즈니스 요구사항 분석
최적의 Limit 값을 결정하기 위해서는 비즈니스 컨텍스트가 필수였습니다. 이 API를 매체사에 도입한 윈으로부터 유스케이스에 대한 상세 정보를 얻을 수 있었습니다.
최근 기록 조회 API의 실제 유스케이스
- 사용자가 특정 액션을 수행하고 기록이 저장됨
- 액션 완료 후 "결과 확인" 화면으로 리다이렉트되어 최신 기록을 표시
2. 데이터 기반 의사결정: 협업을 통한 Limit 값 산정
Limit 값을 "적당히 50으로 설정하자"는 감에 의존하지 않고, 실제 데이터를 기반으로 결정했습니다. 윈께서 DA 팀에 데이터 분석을 요청해 주셔서, 다음과 같은 구체적인 질문에 대한 답을 얻을 수 있었습니다.
- "유저가 세션당 몇 번의 요청을 보내는가?"
- "P95, P99 기준으로 얼마나 여유를 두어야 하는가?"
분석 조건 (도메인 지식 기반으로 설정)
- 세션 기준: 30분 (요청 간격이 30분 이상이면 새 세션)
- 대상: 트래픽 비중이 높은 광고 타입
분석 결과
| 지표 | 값 | 의미 |
|---|---|---|
| avg_requests_per_session | 5.33 | 세션당 평균 요청 수 |
| median_requests_per_session | 3 | 세션당 요청 수 중앙값 |
| p95_requests_per_session | 18 | 95% 세션이 18회 이하 |
| p99_requests_per_session | 22 | 99% 세션이 22회 이하 |
| avg_session_duration | 201.64초 | 평균 세션 지속 시간 (~3.4분) |
| median_session_duration | 28.16초 | 세션 지속 시간 중앙값 |
Limit 값 산정 근거
P99 = 22 요청/세션
↓
기본 Limit = 22 × 1.5 ≈ 33 (안전 마진)
↓
최대 Limit = 33 × 2 = 66 (엣지 케이스 대응)
따라서 33~66개 아이템만 스캔하면 99% 이상의 요청을 충분히 커버할 수 있습니다.
매직 넘버는 코드에 주석으로 산정 근거를 명시했습니다. 시간이 지나면 왜 이 값인지 아무도 모르게 되기 때문입니다.
핵심 인사이트: 실제 사용 패턴을 분석한 결과, 대부분의 조회가 최근 기록만 필요했습니다. 이를 근거로 조회 범위를 제한하면 파티션 전체(수백 개)를 스캔할 필요가 없어집니다.
3. 비효율 검증
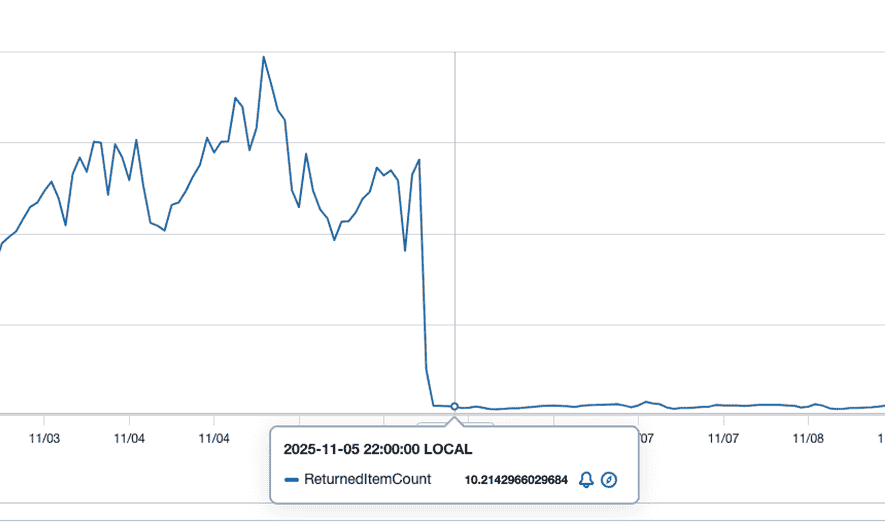
준께서 알려주신 AWS 콘솔의 "Query returned Item count" 지표를 통해 비효율을 검증할 수 있었습니다.
# AWS 콘솔 DynamoDB 테이블 메트릭
Query returned Item count (평균): 270개/요청
P99 기준 22개면 충분한 유스케이스에서 쿼리당 평균 270개를 스캔한다는 것은 심각한 비효율을 의미했습니다. 이 지표가 문제의 규모를 정량화하는 핵심 근거가 되었습니다.
4. Consistency 요구사항 재정의
Strong Consistent Read가 정말 필요한지 검토했습니다.
| 시나리오 | 소요 시간 |
|---|---|
| 액션 완료 → API 응답 | ~50ms |
| 클라이언트 리다이렉트 | ~200ms |
| 확인 화면 렌더링 | ~100ms |
| 총 지연 | ~350ms |
사용자가 결과 화면을 보기까지 약 350ms가 소요되므로, DynamoDB 복제 지연(수백 ms 이내)보다 깁니다. 따라서 Eventually Consistent Read로 충분합니다.
추가로, 클라이언트에서 최대 3회의 retry 로직이 존재하여 일시적인 데이터 미노출에도 안전합니다.
최적화 구현
핵심 변경: SearchLimit 적용
iter := r.table.Get("user_id", userID).
SearchLimit(limit). // 핵심: 스캔 제한
ConsumedCapacity(&cc). // RCU 모니터링
Iter()
defer func() {
if cc.Total > 1.5 { // 평균 아이템 사이즈 기반, 엣지 케이스 모니터링
log.Info("DynamoDB RCU consumed", "total", cc.Total, "user_id", userID)
}
}()
예상 RCU 절감:
- Before: ⌈300개 × 400B ÷ 4KB⌉ × 1 = 30 RCU
- After: ⌈50개 × 400B ÷ 4KB⌉ × 0.5 ≈ 3 RCU (Limit 50 기준, 33~66 범위 중간값)
- 예상 절감률: ~90%
개선 결과
1. 사용량 개선
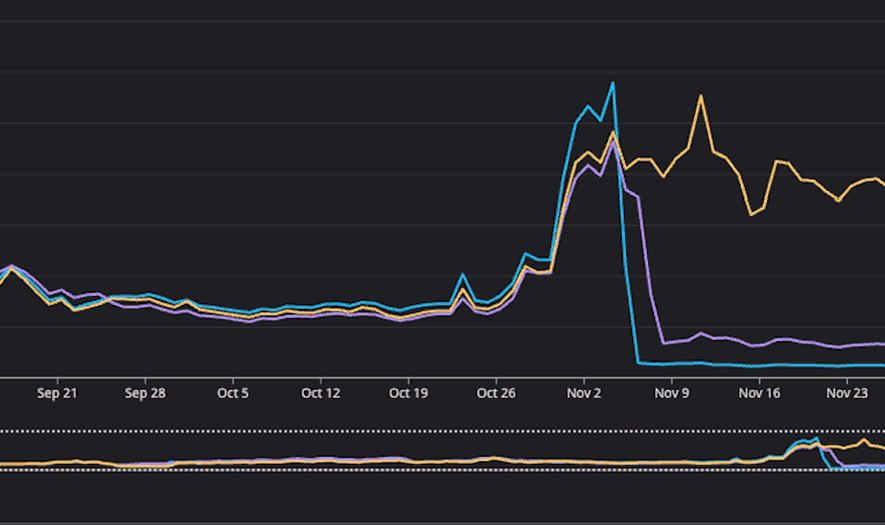
| 테이블 | 지표 | Before | After | 감소율 |
|---|---|---|---|---|
| A 테이블 | RCU | 60k/s | 8k/s | 87% |
| C 테이블 | RCU | 70k/s | 2k/s | 97% |
2. 서비스 품질
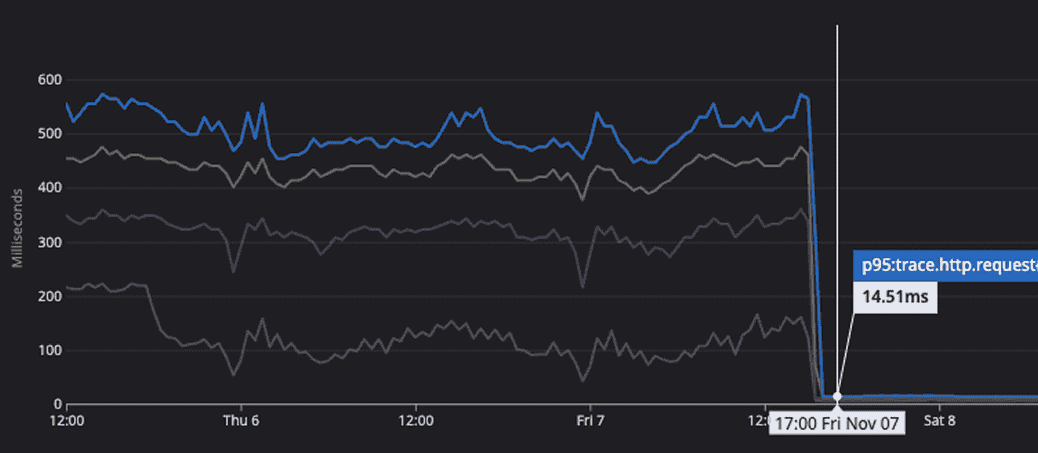
쿼리 개선 결과 API 성공률은 유지하면서, 응답 시간은 크게 개선되었습니다.
마치며
이번 이슈는 메트릭을 일단위 표로 정규화하고, 배포 이력을 매트릭스로 교차 분석하면서 원인을 좁혀갈 수 있었습니다. AI를 활용한 스크립트 작성, 준의 이슈 리포팅과 지표 제안, 윈의 맥락 전달, DA 팀의 데이터 분석 등 협업 덕분에 해결 과정이 크게 단축되었고, 결과적으로 RCU 97% 절감이라는 성과를 얻었습니다.
DynamoDB를 사용한다면 Limit 설정, ConsumedCapacity 로깅, 그리고 Consistency 옵션(Strong vs Eventually)이 유스케이스에 적절한지 검토해 보시길 권장드립니다.
부록: 개발 중 만난 함정 - context.Canceled 에러
최근 기록 조회 API는 두 개의 DynamoDB 테이블을 병렬로 조회합니다.
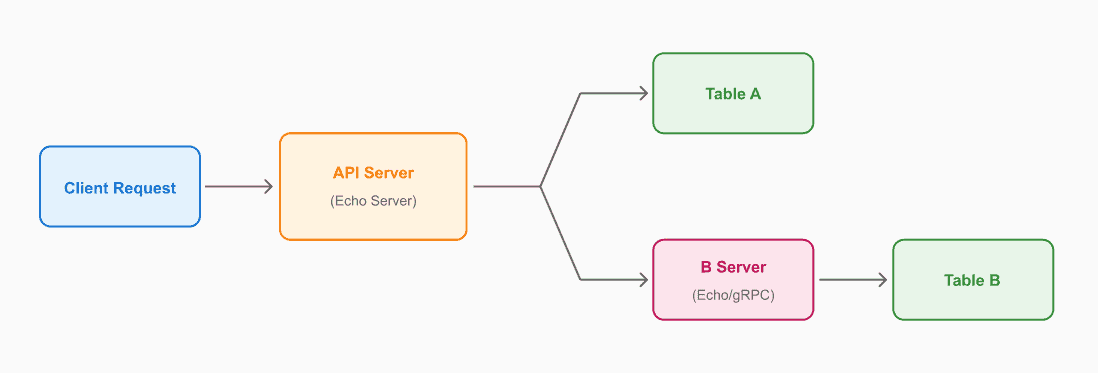
두 테이블에 동일한 데이터가 존재하며, 먼저 성공하는 쪽의 결과를 반환합니다.
// 병렬 조회 패턴 (예시)
go func() { resultCh <- queryTableA(ctx, id) }()
go func() { resultCh <- queryTableB(ctx, id) }()
select {
case r := <-resultCh: return r.Data // 먼저 성공한 결과 반환
case <-ctx.Done(): return ctx.Err()
}
이 구조 때문에 한 쪽이 성공하면 다른 쪽은 context.Canceled 에러가 발생합니다. 이는 정상적인 동작이므로 모니터링에서 예외 처리가 필요합니다. 특히 AWS SDK v1을 사용 중이라면 context.Canceled로 에러 변환 처리가 필요한데, 쿤의 리뷰 덕분에 빠르게 해결할 수 있었습니다. 결과적으로, 다음과 같은 예외 처리를 적용했습니다.
- 에러 집계(Datadog 등)에서
context.Canceled제외 - 알람(Sentry 등)에서
context.Canceled제외 - AWS SDK v1 사용 시
CanceledErrorCode를context.Canceled로 변환 처리
참고 자료
AWS 공식 문서
- DynamoDB Read Consistency - Strong vs Eventually Consistent Read
- DynamoDB Query API - Limit 파라미터, 1MB 페이징
- Read/Write Capacity Mode - RCU 계산 방식
- Best Practices for Querying - 쿼리 최적화 가이드
라이브러리
- guregu/dynamo v1.20.2 - 본문에서 분석한 버전
- guregu/dynamo Query 구현 - Limit vs SearchLimit 로직

