
-
 Zune Seo
Zune Seo
- 30 Apr, 2024
AWS 비용 최적화 Part 1: 버즈빌은 어떻게 월 1억 이상의 AWS 비용을 절약할 수 있었을까
버즈빌은 2023년 한 해 동안 월간 약 1.2억, 연 기준으로 14억에 달하는 AWS 비용을 절약하였습니다. 그 경험과 팁을 여러 차례에 걸쳐 공유합니다. AWS 비용 최적화 Part 1: 버즈빌은 어떻게 월 1억 이상의 AWS 비용을 절약할 수 있었을까 (준비중) …
Read Article Raf Kim
Raf Kim

안녕하세요. 버즈빌의 데이터 엔지니어 Raf입니다. 이전 포스팅(DynamoDB를 사용하는 Go 서비스의 응답 시간 최적화 #1 AWS Credential Token)에 이어, Go 서비스에서 DynamoDB를 사용하면서 응답 시간 최적화를 시도한 경험을 공유드리도록 하겠습니다. 이번 편은 해결책을 만들지 못했지만, DynamoDB와 Go HTTP Client를 사용하면서 배우게 된 것에 대해 공유하고자 합니다.
리워드 서비스를 런칭하고 난 뒤 몇 개월이 지나면서 트래픽은 점점 늘어났습니다. 어느 순간부터 극히 일부의 gRPC 요청이 높은 응답시간을 가지는 Datadog 알람을 몇 번씩 보게 되었습니다. DynamoDB의 쿼리 응답시간 대시보드를 보았더니 최댓값이 100ms를 넘기는 경우를 보게 되었습니다.
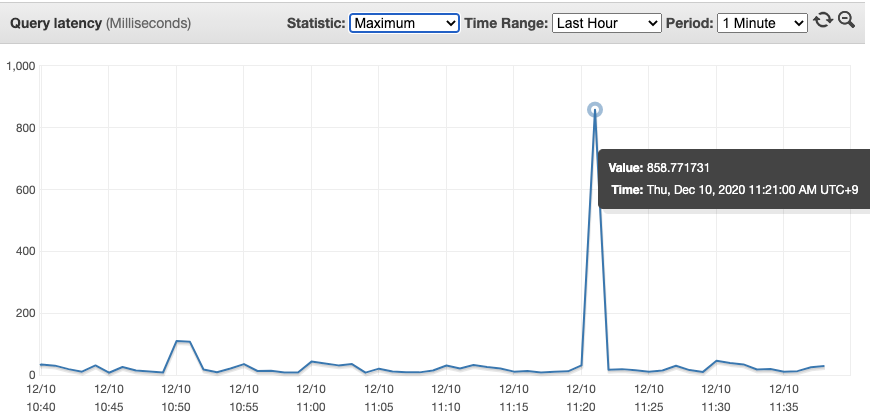 그림 1) DynamoDB 쿼리 응답시간 대시보드
그림 1) DynamoDB 쿼리 응답시간 대시보드
DynamoDB Metrics and Dimensions에 따르면, 위의 대시보드는 네트워크, 클라이언트의 시간이 아닌 서버에서의 요청 처리 시간만 포함된다고 합니다. 로드테스트를 수행하던 때에는 DynamoDB의 응답시간은 짧다고 가정하였고 DynamoDB에서도 응답 시간이 짧게 나오는 상황은 생기지 않았지만, 이번에는 DynamoDB의 응답 시간이 길어졌으므로 이전과는 완전히 다른 문제로 판단하였습니다. 검색을 해보니, Tuning AWS Java SDK HTTP request settings for latency-aware Amazon DynamoDB applications 문서에서 DynamoDB 요청에 타임아웃을 걸어두고 타임아웃이 지나면 재시도를 하는 Java AWS SDK의 설정에 대해 소개가 되어 있었습니다. 하지만 Go AWS SDK에서는 지원하지 않고 있으므로, 아래처럼 타임아웃이 지나면 재시도를 하는 로직을 구현하여 사용해 보기로 하였습니다.
30ms의 타임아웃으로 최대 3회까지 요청을 시도하며, 재시도를 해도 똑같은 에러가 나올 수밖에 없는 에러는 즉시 리턴해주고 타임아웃을 포함한 재시도 가능한 에러는 재시도를 수행합니다. 이 코드를 배포하였을 때 기대하는 것은 Datadog을 통해 gRPC 요청이 100ms 이내로 완료되는 것입니다.
이 코드를 배포한 뒤 응답 시간이 긴 gRPC 요청에 대해서 모니터링을 하였습니다.
하지만 일부 gRPC 요청에서 DynamoDB로 가는 요청에 타임아웃이 발생하면 다음 요청도 타임아웃이 발생하는 문제가 보였습니다.
제가 기대했던 것은 간헐적인 네트워크 등의 이슈로 인해 응답시간이 길어질 수 있지만, 재시도를 하게 되면 낮은 응답시간을 가질 수 있을 것이라 생각했습니다.
하지만 이런 상황은 간헐적이라기보다는 인과가 있는 듯한 모습을 보였습니다.
따라서 httptrace.ClientTrace를 통해 몇 가지 trace를 심어보기로 하였습니다.
httptrace.ClientTrace에 대해선 첫 번째 포스팅(HTTP connection pool in Go explained)을 참조 부탁드립니다.
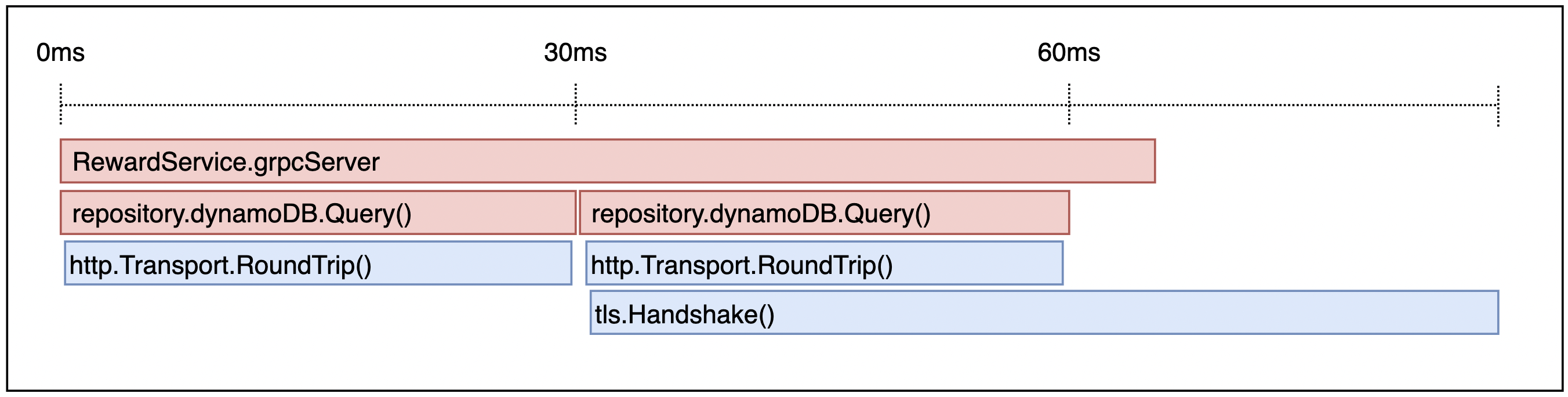 그림 2) Datadog APM
그림 2) Datadog APM
Trace를 심은 후 확인해 본 결과, 대체적으로 첫 시도에 타임아웃이 발생하면 두 번째 시도에서 TLS Handshake를 하고 있었습니다. 이 중 100ms를 넘어가는 gRPC 요청들은 모두 TLS Handshake를 수행하고 있었으며 이 중 일부는 TLS Handshake에 100ms가 넘는 시간을 쓰고 있었습니다. APM에서 TLS Handshake가 타임아웃 이후에도 발생하는 이유는 다른 Go routine으로 커넥션을 생성하기 때문입니다. TLS Handshake는 커넥션을 맺을 때에만 필요한 과정이므로 긴 응답시간을 가지는 요청들은 대부분 새로운 커넥션을 만들려고 시도한다는 것을 확인하였습니다.
TLS Handshake의 응답시간을 줄일 수만 있다면, 문제는 쉽게 해결할 수 있을 것이라 보여 TLS Handshake 과정에 대해 알아보았습니다.
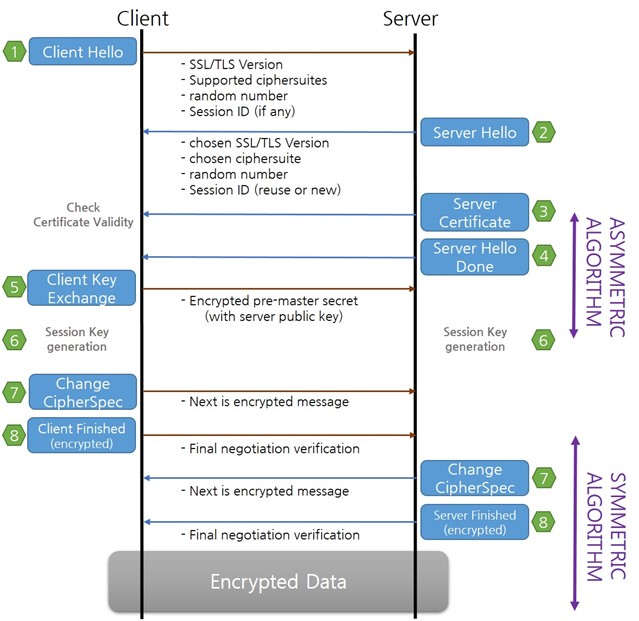 그림 3) TLS Handshake 과정 (출처: TLS Handshake)
그림 3) TLS Handshake 과정 (출처: TLS Handshake)
TLS Handshake에서 처음으로 주고받는 메시지인 Client Hello, Server Hello는 서로 커넥션을 맺기 위한 메타데이터를 공유하게 됩니다.
특히 TLS Session Resumption은 TLS Handshake 과정을 간소화하여 응답시간을 줄일 수 있습니다.
최초 한 번의 Handshake 이후, 새 TLS 커넥션을 만들 때마다 처음에 받은 Session을 재활용할 수 있습니다.
Session ID Resumption은 서버에서 Session을 캐싱하고 있으며, Session Ticket Resumption은 서버에서 캐싱 하지 않는 방식이라고 합니다.
이런 특징을 활용해서 여러 대안을 생각해 보고 이것들이 실현 가능한지 확인해 보았습니다.
하지 말아야 할 방법이지만 가장 간단한 방법이라 먼저 실현 가능성을 확인해 보았습니다. Infrastructure Security in Amazon DynamoDB 문서에 따르면, DynamoDB는 TLS 1.0 이상을 필수로 사용해야 하며, TLS 1.2 이상을 권장하고 있습니다. 따라서 TLS를 사용하면서 응답시간을 줄여야 합니다.
두 번째로 고민한 것은 hop을 최대한 줄이는 것입니다. Handshake의 응답시간이 10ms 정도가 일반적이고 에러가 나는 일부 요청에서만 100ms 가량 나왔으므로 Handshake에서 생기는 연산과정보다는 네트워크 응답시간이 주요 병목이 될 것이라 추정했습니다.
DynamoDB는 기본적으로 퍼블릭 인터넷을 통해 접근하지만, 보안 목적으로 퍼블릭 게이트웨이를 거치지 않고 AWS 내부망에서 통신을 하도록 VPC Endpoint를 설정할 수 있습니다 (Using Amazon VPC Endpoints to Access DynamoDB). 하지만 Amazon EKS를 사용해서 리워드 서비스를 띄우고 있었으므로 VPC 엔드 포인트를 사용하기 위해 필요한 인프라 설정이 필요하지만 응답시간을 줄일 수 있을지 확신이 없어 유보하게 되었습니다. 이후 AWS 솔루션 아키텍트 분들과 함께 가진 DynamoDB 클리닉 세션에서 위와 같은 상황에 대해 VPC 엔드 포인트를 사용하는 것이 어떤지 의견을 여쭤보았으나, 응답시간을 짧게 하려는 목적으로 VPC 엔드 포인트를 사용했을 때 효과는 크지 않을 것이라는 답변을 해 주셨습니다.
위에서 설명한 Session Resumption 기능을 활용할 수 있다면 큰 문제 없이 응답시간을 최적화할 수 있습니다.
하지만 이것에 대해 공식적으로 보이는 답변은 찾지 못하였고, Case Open을 통해 DynamoDB에서 Session Resumption 지원 여부를 물어보았습니다.
답변이 오는 동안 ServerHello 메시지에서 Session Resumption 지원 여부를 클라이언트에게 알려주는 점에 착안하여, Go의 TLS 계층에서 이 정보를 로그로 찍어보았습니다.
확인해 보니 ClientHello 메시지의 ticketSupported 필드에 true를 넣어서 보내도 ServerHello 메시지는 false를 리턴하였습니다.
또한 Session ID 방식은 Go에서 지원하지 않는 것으로 확인하였습니다.
이후 AWS에서 아래와 같은 답변을 받았습니다.
따라서 TLS Handshake를 피할 방법은 없다고 판단하였습니다. DynamoDB가 낮은 응답시간을 강조하고 있었음에도 실제 응답시간에 큰 영향을 미치는 TLS Handshake에 대해 Session Resumption을 지원하지 않는 것은 아쉬웠습니다.
TLS Handshake를 하는 것이 불가피하므로 TLS Handshake의 빈도를 최대한 줄이려면 커넥션을 최대한 재사용 해야 합니다. 하지만 재시도 상황에서 TLS Handshake를 시도하는 것을 보면 커넥션을 재활용하지 못하는 것처럼 보였습니다.
첫 번째 포스팅에서 커넥션이 커넥션 풀로 반납되는 과정에 대해 설명하였습니다.
하지만 이번 케이스는 커넥션이 커넥션 풀로 반납되지 않은 상황이므로 어떤 경우에 커넥션 풀로 반납되지 않을 수 있는지 확인해 보기로 하였습니다.
tryPutIdleConn()이 idleConn에 커넥션을 넣지 못하면 에러를 리턴하게 되고, persistConn.close() 메소드를 호출해서 커넥션을 닫게 됩니다.
petsistConn.close() 메소드는 readLoop(), writeLoop() Go routine이 종료되도록 합니다.
커넥션을 닫아주는 persistConn.close()를 호출하는 함수들을 따라가 보았습니다.
context의 타임아웃이 발생되는 경우 요청을 처리하는 readLoop(), writeLoop() Go routine이 타임아웃에 대한 정보를 받아 persistConn.close()를 호출하는 것을 확인하였습니다.
결과적으로 TLS Handshake를 지속적으로 만드는 원인은 짧은 타임아웃 값으로 인해 재시도가 생겨 오히려 역효과를 만드는 것이었습니다.
따라서 재시도가 자주 일어나지 않도록 하면서, 재시도가 동작할 경우 TLS Handshake가 성공할 수 있도록 타임아웃을 설정해 줘야 합니다.
저는 어느 정도 느린 DynamoDB의 응답시간에 대해 용인할 수 있도록 타임아웃을 70ms로 높였습니다. 70ms로 설정하면 재시도에서 TLS Handshake의 응답시간이 100ms 정도 될 경우 두 번째 시도에서도 실패하게 될 것입니다. 하지만 커넥션을 생성하는 과정은 gRPC 요청을 처리하는 Go routine과 다른 Go routine으로 동작합니다. 커넥션이 생성되고 난 뒤 커넥션을 사용할 Go routine이 없으면 이 커넥션은 유휴 커넥션이 되어 커넥션 풀로 들어가게 됩니다. 따라서 세 번째 요청에서 커넥션을 또다시 생성하려 하지만, 그 사이에 유휴 커넥션이 생겨 DynamoDB로 요청을 보낼 수 있을 것입니다.
커넥션 풀에 충분히 많은 유휴 커넥션을 유지하여 일부 커넥션이 닫힐 때 바로 유휴 커넥션을 사용하도록 만드는 방법도 생각할 수 있습니다.
첫 번째 포스팅(HTTP connection pool in Go explained)에서 MaxIdleConnsPerHost와 IdleConnTimeout 값을 조정하면 커넥션 풀에 서버가 실제로 사용하는 만큼의 커넥션을 넣어둘 수 있습니다.
그런데 IdleconnTimeout의 기본값은 90초이지만, 리워드 서비스는 10분에 한 번씩 트래픽이 급증하는 경향을 가지고 있어 10분이 적절한 값이지만 이만큼 높이는 것은 합리적인 설정이 아니라고 보았습니다.
또한 커넥션 풀은 LRU로 동작하고 Round-Robin과 같은 옵션을 제공하지 않아 모든 커넥션을 살아있는 상태로 오랜 시간 동안 유지하기는 어렵다고 판단하였습니다.
이 문제에 관해 AWS 솔루션 아키텍트에게 여쭤보니, IdleConnTimeout을 늘리더라도 DynamoDB 서버에서 커넥션을 끊어버릴 수 있어 실제로 잘 동작하지 않을 것이라고 말씀해 주셨습니다.
나중에 Amazon DynamoDB의 아키텍처에 대해 깊게 설명한 영상을 보면서 DynamoDB가 수많은 인스턴스가 존재하는 Request Router가 요청을 받고 파티션을 가진 Storage Node에 요청을 전달하는 구조임을 알았습니다.
이 구조를 보고 DynamoDB 클라이언트가 특정한 Request Router 인스턴스와 통신하는 것이 아니므로 클라이언트의 커넥션을 임의로 끊는 것이 서버의 가용성을 높게 유지할 수 있지 않을까 생각하게 되었습니다.
AWS에서 제안하는 방법으로는 커넥션을 통해 더미 트래픽을 보내 커넥션을 유지하는 것도 해결책이 될 수 있다고 합니다. 하지만 이 방식은 코드의 복잡도를 높이는 방식이 될 것 같아 채택하지 않았습니다.
처음 목표는 gRPC 요청의 타임아웃을 100ms 이내로 만드는 것이었지만, 간헐적인 요청들에 대해서까지 모두 최적화하려다 보니 오히려 커넥션 풀에 악영향을 줄 수도 있는 결과를 보았습니다. 적절한 타임아웃을 설정하여 응답시간이 긴 요청의 대다수는 해결했지만, 계속해서 긴 응답시간을 보이는 극히 일부의 요청은 아쉽게도 버려질 수밖에 없었습니다. 원인을 파악하기 위해 Go의 HTTP 커넥션 풀과 DynamoDB를 깊게 보면서 매우 값진 경험을 하게 되었습니다. 특히 DynamoDB를 더 관심을 가지게 되었고 아키텍처가 어떤 식으로 구성되어 있는지, 현재 지원하는 기능들은 어떤 방식으로 구현했는지 찾아볼 수 있게 되었습니다. DynamoDB의 아키텍처가 궁금하시다면 아래 두 개 영상을 추천드리며 마치겠습니다. 긴 글 읽어주셔서 감사합니다!
 Zune Seo
Zune Seo
버즈빌은 2023년 한 해 동안 월간 약 1.2억, 연 기준으로 14억에 달하는 AWS 비용을 절약하였습니다. 그 경험과 팁을 여러 차례에 걸쳐 공유합니다. AWS 비용 최적화 Part 1: 버즈빌은 어떻게 월 1억 이상의 AWS 비용을 절약할 수 있었을까 (준비중) …
Read Article
 Abel Yoon
Abel Yoon
들어가며 안녕하세요, 버즈빌 데이터 엔지니어 Abel 입니다. 이번 포스팅에서는 데이터 파이프라인 CI 테스트에 소요되는 시간을 어떻게 7분대에서 3분대로 개선하였는지에 대해 소개하려 합니다. 배경 이전에 버즈빌의 데이터 플랫폼 팀에서 ‘셀프 서빙 데이터 …
Read Article