
DynamoDB를 사용하는 Go 서비스의 응답 시간 최적화 #1 AWS Credential Token
Data Engineer
안녕하세요. 버즈빌의 데이터 엔지니어 Raf입니다. 이전 포스팅에서 Go의 HTTP 커넥션 풀에 관해 설명해 드렸습니다 (HTTP connection pool in Go explained). 이 포스팅에서는 Go 서비스에서 HTTP 요청에 대한 Trace를 남겨 DynamoDB 요청의 응답 시간에 큰 영향을 미치는 Credential Token 발급 로직을 찾아내고 최적화한 내용을 담았습니다.
Amazon DynamoDB는 낮은 응답 시간과 strong consistency를 지원하는 NoSQL 데이터베이스입니다. 사용자에겐 노출되지 않지만 읽기, 쓰기 요청이 진행 중일 때에도 수평적 확장이 가능하므로 확장성, 가용성이 뛰어납니다. DynamoDB의 데이터 모델은 파티션 키와 정렬 키뿐만 아니라 다른 정렬키를 사용하는 LSI, 다른 파티션 키를 사용하는 GSI까지 지원하기 때문에, 다양한 접근 패턴에도 유연하게 대응을 할 수 있습니다.
버즈빌에서는 주로 Write intensive 한 테이블에 대해 DynamoDB를 활용하고 있습니다. 이런 워크 로드에서 DynamoDB를 사용하면 MySQL보다 Migration 같은 운영적인 부담이 훨씬 줄어드는 이점이 있습니다. 이 중 유저가 광고를 볼 때 받아 가는 리워드에 대한 적립 기록을 관리하는 리워드 테이블은 Write intensive 하면서도 낮은 응답 시간, 높은 처리량을 요구하여 DynamoDB를 사용하기로 하였습니다. 하지만 새로 리워드 서비스를 구현하면서 그동안 인지하지 못했던 에러들을 보았습니다.
적은 트래픽에서 간헐적으로 높은 응답 시간을 보이는 현상
리워드 서비스를 구현하면서 로드 테스팅 프레임워크인 Locust를 같이 도입하였습니다. Locust는 파이썬이나 Go로 코드를 작성할 수 있어 버즈빌의 기술 스택과 일치하므로 도입하는데 부담이 적었습니다. 또한, 단순히 HTTP 요청을 보내는 것뿐만 아니라 GRPC 요청을 하거나 메시지 큐에 이벤트를 전달하는 것 등 로드테스트를 실행하는 대상에 대한 제약이 없어서 Locust를 선택하였습니다. 로드테스트는 트래픽을 점진적으로 늘리면서, 1000 RPS까지 안정적으로 처리하는 서비스를 만드는 것을 목표로 하였습니다. Locust에서 동작하는 테스트 에이전트가 리워드 서비스를 호출할 수 있도록 간단한 코드를 작성한 뒤 3 RPS 정도의 낮은 트래픽을 보내면서 모니터링을 하였습니다. 그런데 한두 시간에 한 번씩 응답 시간이 2초 가까이 튀는 요청이 한두 개씩 발생했습니다. 트래픽이 점점 늘어난다면 높은 응답 시간을 가지는 요청의 비중이 점점 더 커질 위험도 있었으므로 원인을 파악해야만 했습니다.
Trace를 심어 원인을 파악해보자
먼저 DynamoDB에 대한 CloudWatch 대시보드를 확인했습니다. 최대 응답 시간이 이 정도로 나온다면 DynamoDB 안에서 요청을 처리하는 데 많은 시간이 걸렸다고 판단을 할 수 있습니다. 하지만 대시보드에서는 2초나 되는 응답 시간을 가지는 요청은 없었습니다.
그렇다면 문제는 DynamoDB에 요청을 보내는 리워드 서비스에서 많은 시간을 소요했다고 볼 수 있습니다. 버즈빌에서는 서버의 각 레이어에 Trace를 심고 Datadog APM을 통해 볼 수 있어, 쉽게 긴 실행 시간을 가지는 함수를 파악할 수 있습니다. 따라서 DataDog이 제공하는 AWS Trace를 활용하여 AWS Session에 Trace를 심어 APM을 확인하였습니다. 그림 1은 Trace를 심어 DataDog APM을 통해 본 결과입니다 (당시의 스크린샷이 없어 그림으로 대체하였습니다). 리워드 서비스의 repository 레이어에서 DynamoDB의 Query 커맨드를 호출할 때 남긴 Trace의 수행시간은 대략 2초였지만, DynamoDB의 커맨드가 수행되는 시간은 대략 20ms 미만으로 나왔습니다. 즉, Go AWS SDK 내부에서 2초에 가까운 시간동안 커맨드 수행이 아닌 다른 일을 하고 있었던 것입니다.
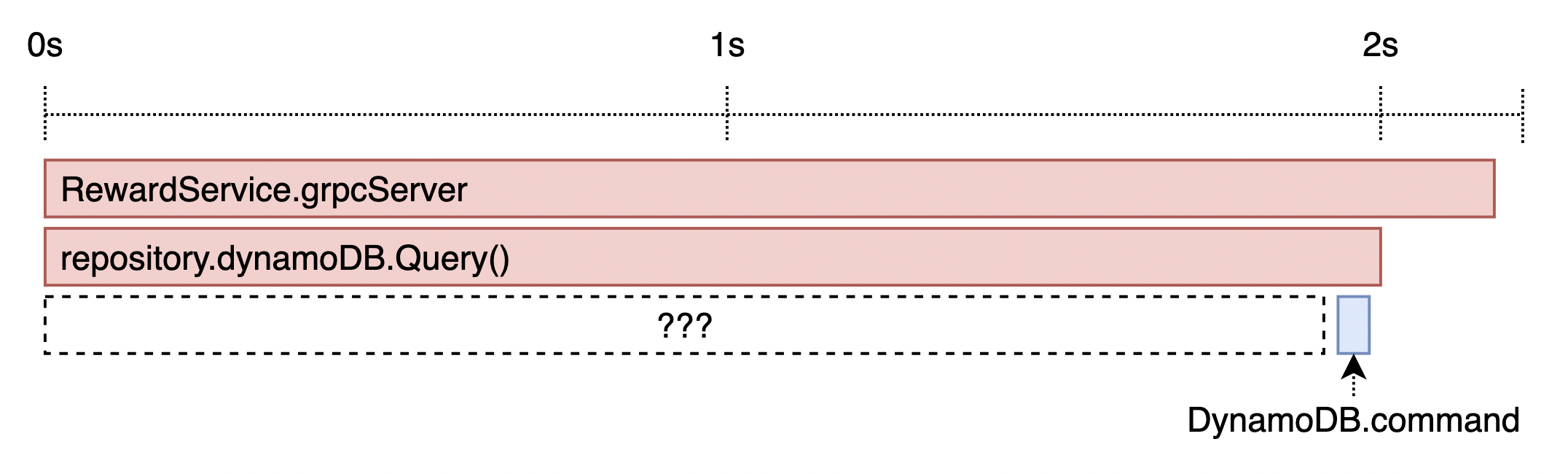 그림 1) DynamoDB에 Trace를 심고 난 후 DataDog APM
그림 1) DynamoDB에 Trace를 심고 난 후 DataDog APM
따라서 Go AWS SDK가 실제로 요청을 처리하는 로직을 살펴보았습니다. 주로 응답 시간이 길게 잡힐 것 같다고 추정되는 구간은 1) DynamoDB에 보내는 HTTP 요청과 2) SDK 내부에서 임시 자격 증명(토큰)을 재발급하기 위한 HTTP 요청이 있었습니다. 그림 1에서 DynamoDB에 보내는 HTTP 요청은 20ms 미만의 응답시간을 보이는 것을 확인하였으므로 인증 토큰 발급 로직이 원인이라 추정했습니다. 또한, SDK 내부에서 토큰이 만료될 때만 HTTP 요청을 보내고 있었으므로 “간헐적으로 응답 시간이 튀는 현상"을 설명하기에도 충분했습니다. 이를 직접 확인하기 위해, 토큰 발급 로직이 높은 응답 시간을 만든다는 것을 확인하기 위한 Trace를 심기로 하였습니다.
Go에서는 HTTP 요청이 진행되는 과정의 몇몇 구간에 대해 Trace를 심을 수 있으며, Go AWS SDK 또한 http.Client 주입을 통해 이 기능을 지원합니다.
http.Transport를 감싸는 구조체를 만들어 http.Client에 대해 Trace를 심었습니다.
http.Client에 Trace를 심는 방법은 이전 포스팅 (HTTP Connection Pool in Go Explained)를 확인하시면 됩니다.
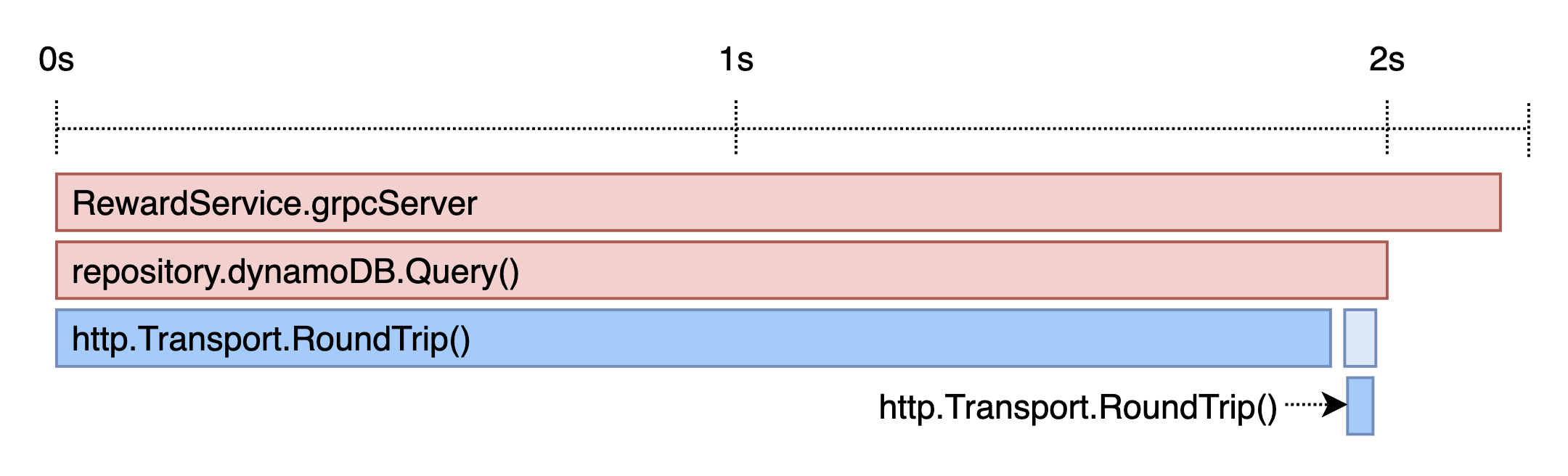 그림 2)
그림 2) http.Client에 Trace를 심고 난 후 Datadog APM
그림 2는 http.Client에 Trace를 심고 난 후 응답 시간이 긴 요청의 Datadog APM입니다.
예상하던 것처럼, 토큰을 재발급하기 위한 HTTP 요청이 2초에 가까운 시간을 보이는 것을 확인하였습니다.
따라서 토큰 재발급 로직에 대해 리서치를 해보기로 하였습니다.
백그라운드로 토큰을 업데이트해 보자
AWS SDK의 토큰 발급에 대해 검색을 해보니 STS 엔드 포인트를 전역 엔드 포인트 대신 리전별 엔드 포인트로 쓰면 응답 시간이 줄어든다는 문서(Managing AWS STS in an AWS Region) 가 있어 이를 바로 적용해 보았습니다.
적용하는 방법은 간단합니다. 환경 변수에 AWS_STS_REGIONAL_ENDPOINTS=regional을 추가하면 됩니다.
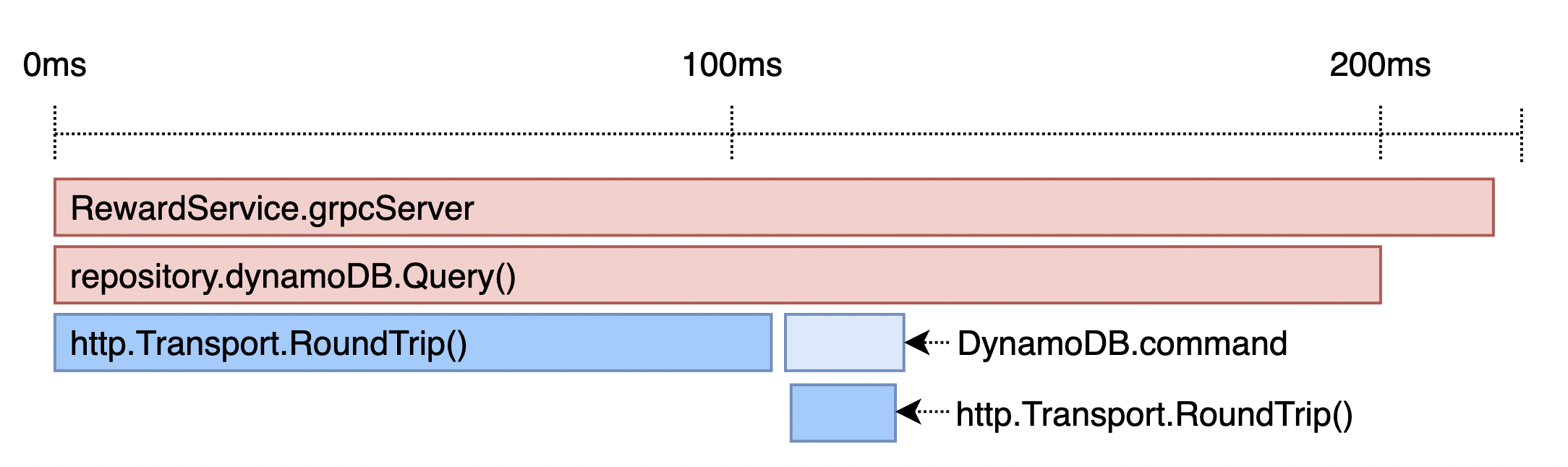 그림 3) 리전별 엔드 포인트를 사용하도록 변경한 뒤 Datadog APM
그림 3) 리전별 엔드 포인트를 사용하도록 변경한 뒤 Datadog APM
2초까지 나오던 토큰 재발급 요청의 응답 시간이 100ms 정도로 많이 줄어들긴 했지만, 여전히 서비스가 GRPC 요청을 처리하는 도중에 토큰 재발급 로직이 포함되면 꽤 높은 응답 시간을 보였습니다. 간헐적으로 나오는 상황이었으므로 평균 응답 시간은 문제가 없었지만, 토큰이 만료될 때마다 GRPC API의 타임아웃이 발생할 가능성이 훨씬 커지므로 잠재적인 위험을 안고 있다고 생각했습니다. 이 문제는 만료되지 않는 1) Access Key 기반의 토큰을 사용하거나, 2) 토큰의 만료 시간을 없애거나, 3) 토큰을 백그라운드로 발급받는다면 이 문제를 해결할 수 있을 것입니다. 하지만 만료되지 않는 인증 방식을 쓰는 것은 보안에 대한 취약점도 생기므로 불가능한 선택지라고 볼 수 있습니다. 세 번째에 대해 찾아보니 Go AWS SDK에서도 비슷한 이슈가 올라와 있었고, 코멘트에서는 백그라운드로 토큰을 재발급하여 해결하는 방법이 있었습니다. 다만 코드에 락을 사용하고 있어 로직에 대해 이해를 한 뒤 사용하기로 하였습니다.
다시 Go AWS SDK의 토큰 발급 구조를 보면서 이슈 코멘트에서 제안한 코드가 잘 동작할지 확인해 보기로 했습니다. AWS SDK에서 토큰이 발급되는 구조는 아래와 같습니다.
credentials.Credentials:credentials.Provider인터페이스를 통해 토큰 발급 요청과 토큰 만료 여부를 확인합니다.stscreds.WebIdentityProvider:credentials.Provider의 구현체로, 임시 자격 증명 방식의 토큰입니다. 이 구현체는 환경 변수에 들어간 값을 바탕으로 SDK 초기화 시점에 결정됩니다. 환경 변수로 주입한 Access Key를 활용하는 구현체는credentials.EnvProvider이며, 토큰이 만료되지 않습니다.
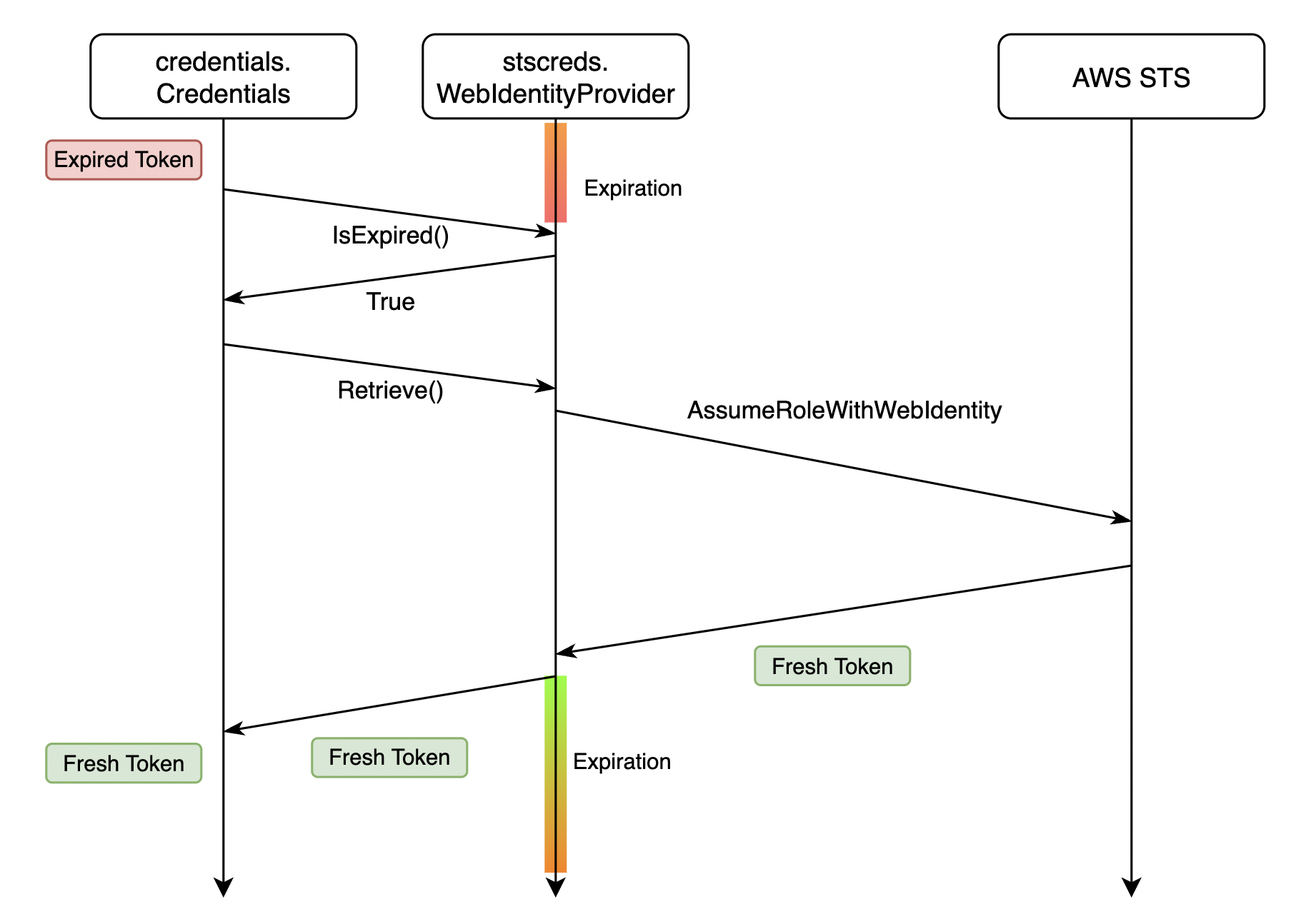 그림 4)
그림 4) stscreds.WebIdentityProvider를 사용하는 토큰 발급
그림 4는 타임라인에 따라 각 컴포넌트의 상호작용과 토큰의 상태를 나타내었습니다.
credentials.Credentials에서 토큰이 만료되면 stscreds.WebIdentityProvider를 통해 토큰을 발급받고, stscreds.WebIdentityProvider는 AWS STS 엔드 포인트로 HTTP 요청을 보냅니다.
stscreds.WebIdentityProvider는 내부 메소드로 만료 시각을 설정하고, 토큰을 리턴합니다.
백그라운드로 토큰을 발급하는 코드는 다음과 같이 동작하게 됩니다.
credentials.Provider를 감싸는 구조체인 RefreshProvider는 Go routine을 통해 토큰을 주기적으로 발급받아 구조체에 캐싱 해 둡니다.
그리고 credentials.Credentials에서 토큰을 발급받기 위해 Provider.Retrieve() 메소드를 호출하면 구조체 내부에서 들고 있는 토큰을 리턴합니다.
이 코드는 실제 토큰 발급 로직이 리워드 서비스의 요청과 분리되도록 해주기 때문에 문제를 해결할 수 있을 것이라 보였습니다.
언제나 하나의 토큰만 활용하도록 만들자
실제로 배포를 하고 테스트를 실행해 보니 다른 에러가 발생했습니다.
InvalidSignatureException 에러가 간헐적으로 발생했었고 다른 변경사항은 없었으므로 원인은 위의 코드가 분명했지만, DynamoDB 서버에서 에러를 내려주고 있어 근본적인 원인을 찾지는 못했습니다.
문서를 찾아보니 만료된 서명인 경우(Troubleshooting AWS Signature Version 4 errors) InvalidSignatureException 에러가 발생한다고 설명되어 있었습니다.
혹시 리워드 서비스가 동시에 두 개의 토큰을 가지고 있으므로 STS 서버에서 이전에 발급받은 토큰에 대해 만료 처리를 하지 않았을까 생각했습니다.
코드에서도 RefreshProvider는 새 토큰을 발급받고 있었지만 즉시 쓰이지는 않고, credentials.Credentials에서 이전 토큰을 사용하고 있다가 이전 토큰이 만료되면 RefreshProvider가 캐싱 해 둔 새 토큰으로 바꾸는 구조입니다.
즉 그림 5처럼, Go routine(파란색 화살표)을 통해 새 토큰을 발급받아도 credentials.Credentials는 가진 토큰이 만료될 때까지 긴 시간 동안 자신이 가진 토큰을 사용하게 됩니다.
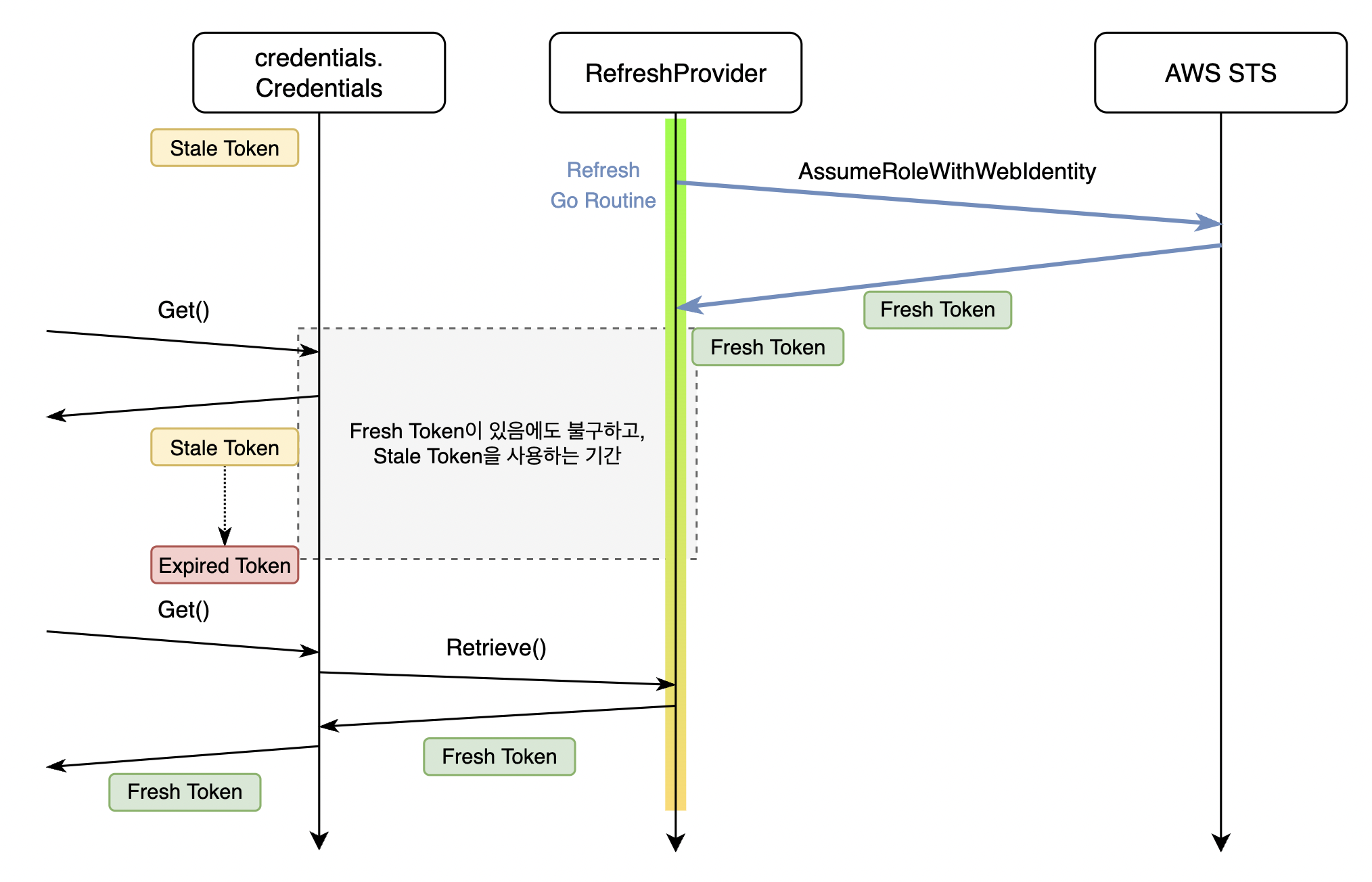 그림 5) 동시애 두 개의 만료되지 않은 토큰 중, 이전 토큰을 사용하는 상황
그림 5) 동시애 두 개의 만료되지 않은 토큰 중, 이전 토큰을 사용하는 상황
따라서 리워드 서비스가 하나의 토큰만 쓰도록 수정해 보기로 하였습니다.
RefreshProvider.periodicRefresh()에서 토큰을 발급받자마자 credentials.Credentials에서 새 토큰을 사용하도록 변경한다면, 리워드 서비스가 동시에 두 개의 토큰을 유지하지 않게 됩니다.
아래 그림 6은 제가 수정한 내용을 도식화하였습니다.
변경된 Go routine(파란색 화살표)는 10분에 한 번씩 토큰 발급을 요청한 뒤, 토큰 발급에 성공하면 Credentials.Expire()를 호출하여 credentials.Credentials가 가진 토큰을 만료시키고, RefreshProvider를 통해 캐싱 된 토큰을 받아 가도록 하였습니다.
이 코드는 Github Gist에 올려두었습니다.
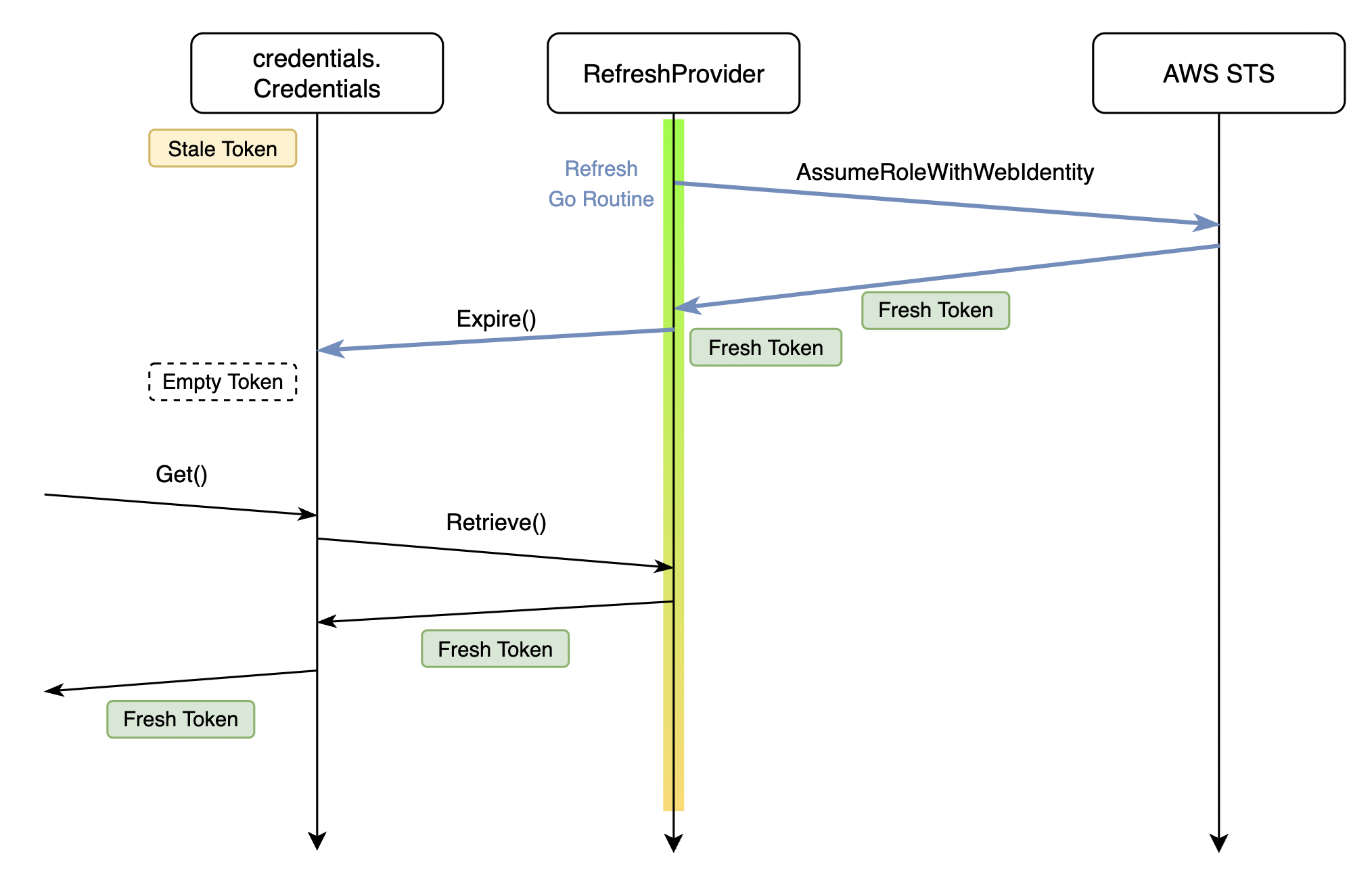 그림 6)
그림 6) RefreshProvider가 새 토큰을 발급받자 마자 credentials.Credentials의 토큰 만료 처리
며칠 정도 지켜보면서 InvalidSignatureException 이 발생하지 않는 것을 확인하고 토큰 발급 문제는 해결되었다고 판단하였습니다.
구현하면서 다소 아쉬웠던 점은 credentials.Credentials , credentials.Provider 둘 다 토큰을 캐싱하고 있고 이 둘을 새 토큰으로 업데이트하기 위해 강제로 Expire()를 호출한다는 점이 Circular dependency를 가지는 것 같아 좋은 구조는 아니라고 생각이 들었습니다.
Datadog APM을 활용하여 http.Client에 Trace를 심어 그동안 알지 못했던 AWS SDK의 토큰 발급 로직을 찾아내고, 이를 RPC 호출의 Critical Path에 포함되지 않게 하여 간헐적으로 생기는 높은 응답 시간을 없앨 수 있었습니다.
이후 며칠 동안 로드테스트의 트래픽을 점점 늘려보면서 서비스가 더 많은 요청에도 안정적으로 동작하는지 확인한 뒤, 로드테스트를 끝내고 서비스를 릴리즈하게 되었습니다.
하지만 릴리즈 이후 몇 개월 동안 트래픽이 서서히 늘어나며 DynamoDB에 저장되는 레코드들이 많아지면서 또다시 높은 응답 시간이 생기는 문제를 보았습니다.
이 이슈는 다음 포스팅을 통해 공유드리도록 하겠습니다.

