
-
 Zune Seo
Zune Seo
- 30 Apr, 2024
AWS 비용 최적화 Part 1: 버즈빌은 어떻게 월 1억 이상의 AWS 비용을 절약할 수 있었을까
버즈빌은 2023년 한 해 동안 월간 약 1.2억, 연 기준으로 14억에 달하는 AWS 비용을 절약하였습니다. 그 경험과 팁을 여러 차례에 걸쳐 공유합니다. AWS 비용 최적화 Part 1: 버즈빌은 어떻게 월 1억 이상의 AWS 비용을 절약할 수 있었을까 (준비중) …
Read Article Liam Hwang
Liam Hwang

안녕하세요, 버즈빌 DevOps 팀의 Liam입니다.
버즈빌은 리워드 기반 애드테크 플랫폼으로서 월간 2천만 이상의 오디언스에게 최적화된 광고를 노출하고 성과를 극대화하기 위해 노력하고 있습니다. 최적화된 광고 서빙을 위해 다양한 데이터 소스로부터 수집된 오디언스의 행동 데이터를 바탕으로 오디언스가 더 관심을 가질 광고를 추천하며, 보상을 활용하여 최종적인 구매까지 도달하기 위한 여정의 허들을 낮추고자 노력하고 있습니다. 버즈빌에서는 시간이 지남에 따라 다뤄야 할 트래픽과 데이터의 양과 속도가 매우 빠르게 늘어났습니다. 이를 더 유연하고 효율적으로 구현하기 위해 수년에 걸쳐 기존의 모노리식 서비스를 수십 개의 마이크로서비스로 분리해 왔습니다.
버즈빌에서는 이러한 복잡한 광고 시스템을 운영하기 위해 매우 다양한 기술 스택을 활용하고 있으며 스택쉐어에도 공유되어 있습니다. 하지만 활용 중인 기술 스택의 종류가 매우 다양하고 각 기술이 회사에서 실제로 어떻게 사용되고 있는지에 관해서 확인하는 데에는 한계가 있다고 생각합니다. 이번 글에서는 버즈빌에서는 이런 복잡하고 대용량의 트래픽을 처리하는 광고 시스템을 운영하기 위해 어떤 백엔드 기술 스택을 활용하고 있는지 간략하게 소개해 드리고자 합니다.
백엔드 마이크로서비스는 대부분 Python 또는 Go로 작성되고 있습니다. 내부 서비스 카탈로그에는 2021년 10월을 기준으로 45개의 마이크로서비스가 작성되어 있습니다(백엔드 서비스만 포함). 언어별로는 Python으로 작성된 서비스는 21개, Go는 16개, Node.js 7개 등이 있습니다. 제품팀 내에서 주로 사용되는 Python과 Go의 채택률은 엇비슷한 편이지만 마이크로서비스 아키텍처를 중심으로 하는 개발 문화가 보편화한 이후에는 Go 언어로 작성된 gRPC 기반의 서비스가 근소한 차이로 더 활발히 생성되고 있습니다.
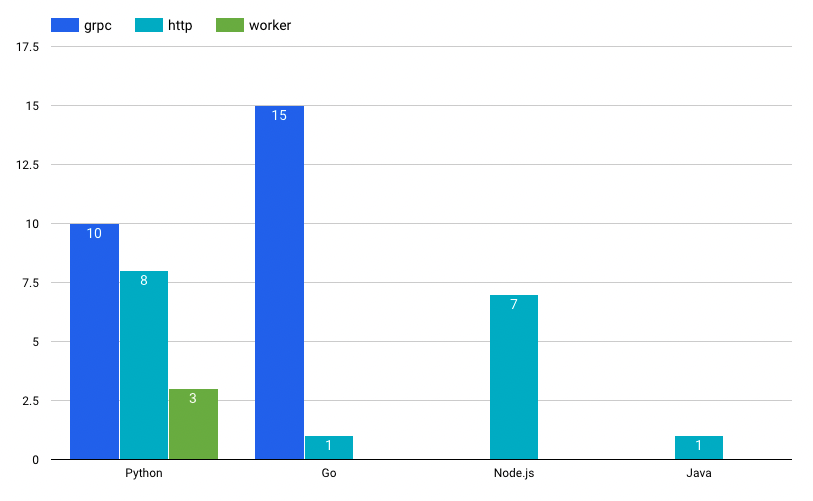
Python은 버즈빌이 가장 오랫동안 주력으로 채택해오고 있는 언어이고, 프레임워크는 Django를 주로 활용하고 있습니다. Django는 훌륭한 ORM이 제공되며 다양한 모델을 중심으로 한 비즈니스 로직 작성이 용이하여 사내에서 여전히 인기가 많은 프레임워크입니다. 마이크로서비스의 경우 특정 도메인 로직에 집중하고 Django가 제공하는 다양한 기능들이 필요 없는 경우가 많기 때문에 비교적 가벼운 Flask나 FastAPI를 활용하기도 하며, 최근에는 gRPC 기반의 Python 서비스가 더 많이 작성되고 있습니다.
버즈빌에서는 기존에 광고 할당을 포함한 대부분의 API를 Django 기반의 Python 웹서버에서 서빙하고 있었지만, 광고 트래픽이 늘어나면서 인프라 이용량이 많이 증가하였습니다. 그중 가장 큰 비중을 차지하는 광고 및 콘텐츠 할당 로직을 Go로 포팅하여 큰 폭의 성능 개선을 끌어내었습니다(Go 서버 개발하기). 그 이후로 고성능 API가 필요한 경우 Go를 많이 활용하고 있습니다. Go는 단순함을 추구하는 버즈빌의 개발 철학과도 잘 맞으며, 고루틴을 통한 동시성 프로그래밍에 대한 지원이 뛰어나 매우 인기가 많은 선택지입니다. 프로젝트별로 언어를 선택하는 절대적인 기준은 없습니다만, 성능과 리소스 사용에 대한 고려가 더 많이 필요한 경우 Go를 권장하고 있습니다.
언어별로 해당 언어를 선호하는 개발자들이 모여 전문가 그룹을 구성하여, 추천하는 라이브러리나 프로젝트 구조 등에 대한 best practice를 고민하고 스타일 가이드나 빌드 파이프라인 등을 개선하기 위해 노력합니다.
마이크로서비스를 지향하다 보니 신규 서비스 개발이 잦은 빈도로 발생하였고 서비스를 처음부터 배포까지 빠르게 완료할 수 있도록 서비스 템플릿을 유지보수하고 있습니다. 이 템플릿에는 각 언어별로 권장되는 구성을 반영하여 해당 언어에 대해 이해도가 낮은 구성원이라도 손쉽게 프로젝트를 구성할 수 있도록 돕고 있습니다. 템플릿 프로젝트는 Cookiecutter라는 프로젝트 템플릿 도구를 활용하며, 추후 템플릿으로부터 손쉽게 프로젝트를 생성할 수 있도록 Backstage와도 연동할 계획이 있습니다.
마이크로서비스 간 통신을 위해 gRPC를 활용하기로 했는데, 단순히 성능적인 이득을 얻기 위함만은 아니었습니다. 마이크로서비스 아키텍처의 청사진을 그릴 때부터 수많은 마이크로서비스가 생성될 것이 예상되었고, 매번 API 문서를 작성하는 것으로는 변화무쌍함을 감당하기 어려울 것이라 생각했습니다.
gRPC는 기본적으로 protocol buffer라는 인터페이스 정의 언어(Interface Definition Language, IDL)을 지원하고 있습니다. 새로 생성할 서비스의 인터페이스와 각 RPC의 메시지 명세를 protobuf로 정의해서 IDL 저장소에 PR을 생성합니다. 이 PR에서 신규 기능을 제공하는 팀과 사용하는 팀이 함께 리뷰하면서 회의나 디자인 문서에서 합의된 내용이 잘 반영되었는지 검증합니다. API 정의는 시간이 지나면서 변하기 마련인데, Buf라는 도구를 활용하여 새로운 변경이 하위 호환성을 깨뜨리진 않는지 등을 검증하고 있습니다.
IDL 저장소의 CI는 새로 제안된 API 정의가 머지되면 각 언어별 codegen을 통해 클라이언트 및 서버 코드를 생성하며 언어별 패키지 저장소에 푸시합니다. Go의 경우 Go Module로 패키징하여 GitHub에 태그를 직접 푸시하며, PyPI, NPM 패키지 등은 사내 패키지 저장소에 배포합니다. gRPC를 활용하기 어려운 환경이나 레거시 클라이언트를 위해 gRPC를 JSON API로 transcoding하는 설정을 추가하고 있는데, 이때 필요한 proto descriptor set 또한 생성하여 S3로 업로드 합니다(gRPC를 쓰면 REST가 공짜!? 참조).
데이터베이스로 MySQL(RDS), DynamoDB, Elasticsearch, Redis(Elasticache) 등을 주로 활용하고 있습니다. 각 마이크로서비스는 각자의 자체적으로 해당 도메인의 데이터를 소유하기 위해 중앙 데이터베이스를 공유하지 않고, 각 마이크로서비스가 직접 데이터베이스를 관리하는 것을 원칙으로 하고 있습니다.
대부분의 마이크로서비스에서 특별한 요구사항이 없다면 관계형 데이터베이스인 RDS for MySQL을 주로 사용하고 있습니다. 모니터링에는 pmm-server와 CloudWatch를 활용하고 있고, 무중단 스키마 변경을 위해 GitHub에서 개발된 gh-ost를 활용하고 있습니다.
광고 최대 게재빈도 제어, 리워드 발급 등 높은 읽기/쓰기 성능이 필요하거나 큰 규모로 확장이 예상되는 워크로드의 경우 완전 관리형 데이터베이스인 DynamoDB를 적극적으로 활용하고 있습니다. 프로비저닝 된 읽기/쓰기 용량(provisioned read/write capacity), 쿼리 쓰로틀링 여부 등만 잘 모니터링해주면 확장 축소가 용이하고 운영 코스트가 최소화되기 때문에 다양한 사용처에서 활용되고 있습니다.
사용자의 광고 요청에 대해 수많은 타게팅 조건에 부합하는 후보 광고 목록을 빠르고 효율적으로 선택하기 위해 Elasticsearch를 활용하고 있으며, 캐싱이나 실시간 통계 제공을 위해 Redis를 활용하고 있습니다.
AWS Lambda로 구성된 일부 엔드포인트를 제외하면 대부분의 서비스가 Kubernetes 클러스터에 배포되고 있습니다. 따라서 각 서비스가 내부적으로 어떤 기술을 사용하고 있는지 크게 상관하지 않고 컨테이너 기반으로 빌드만 되면 배포가 가능한 상태가 되는 것을 지향하고 있습니다. 이를 위해 Kubernetes에 배포되는 리소스의 manifest를 일관적으로 관리하기 위해 권장 설정이 포함된 Helm chart 템플릿을 관리하고, Kubernetes로의 배포를 위해 개발자가 챙겨야 하는 중요한 설정(Graceful shutdown, readiness/liveness probe 등)에 대한 가이드를 하고 있습니다.
Helm chart는 IDL 저장소와 유사하게 전사 차트를 모노리포 형태로 단일 저장소에서 관리하고 있으며, 각 서비스 개발자는 템플릿 차트를 기반으로 애플리케이션의 요구사항에 맞게 차트를 작성하면 DevOps 엔지니어가 리뷰하는 프로세스를 가지고 있습니다.
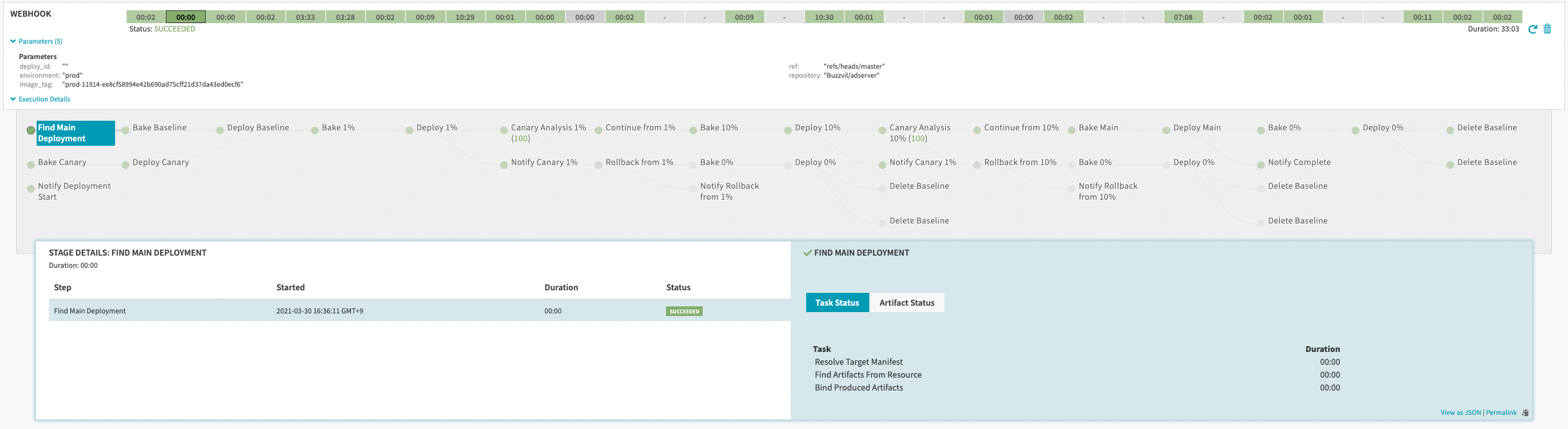
배포는 인하우스 Spinnaker를 이용해 팀별로 다양한 배포 방식을 설정하고 있으며, Managed Pipeline Template 기능을 활용해 환경별 배포 파이프라인을 구성, 관리하는 부담을 덜고 있습니다.
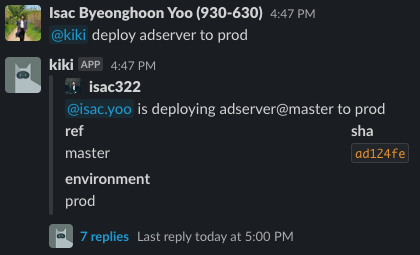
배포의 트리거는 ChatOps를 활용합니다. botkit 기반으로 개발된 내부 챗봇에 배포 트리거를 요청하면 배포된 변경사항에 대한 요약과 배포 상태가 슬랙을 통해 리포팅 됩니다. ChatOps를 활용하면 배포에 대한 가시성이 확보되고, 배포 슬랙 채널을 살펴보는 것만으로도 배포 과정에 대한 온보딩이 자연스럽게 이뤄진다는 장점이 있습니다.
서비스 메쉬로 Istio를 활용하고 있으며, 이는 마이크로서비스 아키텍처를 처음 도입하는 시점부터 활용하기로 하였는데요. 마이크로서비스 간 커뮤니케이션을 통제하는 복잡한 클라이언트 로직을 최대한 인프라 레벨로 내리고 서비스 레벨에서는 핵심 비즈니스 로직에만 신경 쓸 수 있게 하기 위해서였습니다. 특히 HTTP/2에 기반한 gRPC를 적극적으로 활용하기로 했지만 Kubernetes의 Service는 영구 연결(long-lived connection)에 대한 부하 분산에 대한 지원이 미비하기 때문에(참고) 클라이언트 코드에서 부하 분산을 처리하지 않고 그에 대한 고민을 Service Mesh로 넘길 수 있다는 장점이 매우 크게 작용했습니다.
그 외에도 gRPC-JSON 트랜스코더, 트래픽 전환(shifting), 미러링 등의 고급 트래픽 제어 기능을 활용할 수 있기 때문에 신규 기능을 테스트하거나 Django 모노리스의 일부 기능을 새로 작성한 마이크로서비스로 전환할 때 유용합니다. 신규 마이크로서비스로 기존 기능을 옮기고 나면, 기존 트래픽을 미러링하여 양쪽 서비스가 동일한 결과를 만들어내는지 검증하거나 기존 트래픽의 부하에 대응이 가능한지 확인합니다. 그리고 트래픽 전환을 활용해 트래픽의 일부 비율을 점진적으로 신규 마이크로서비스로 유입 시켜 최종적으로 이전을 완료하고 있습니다.
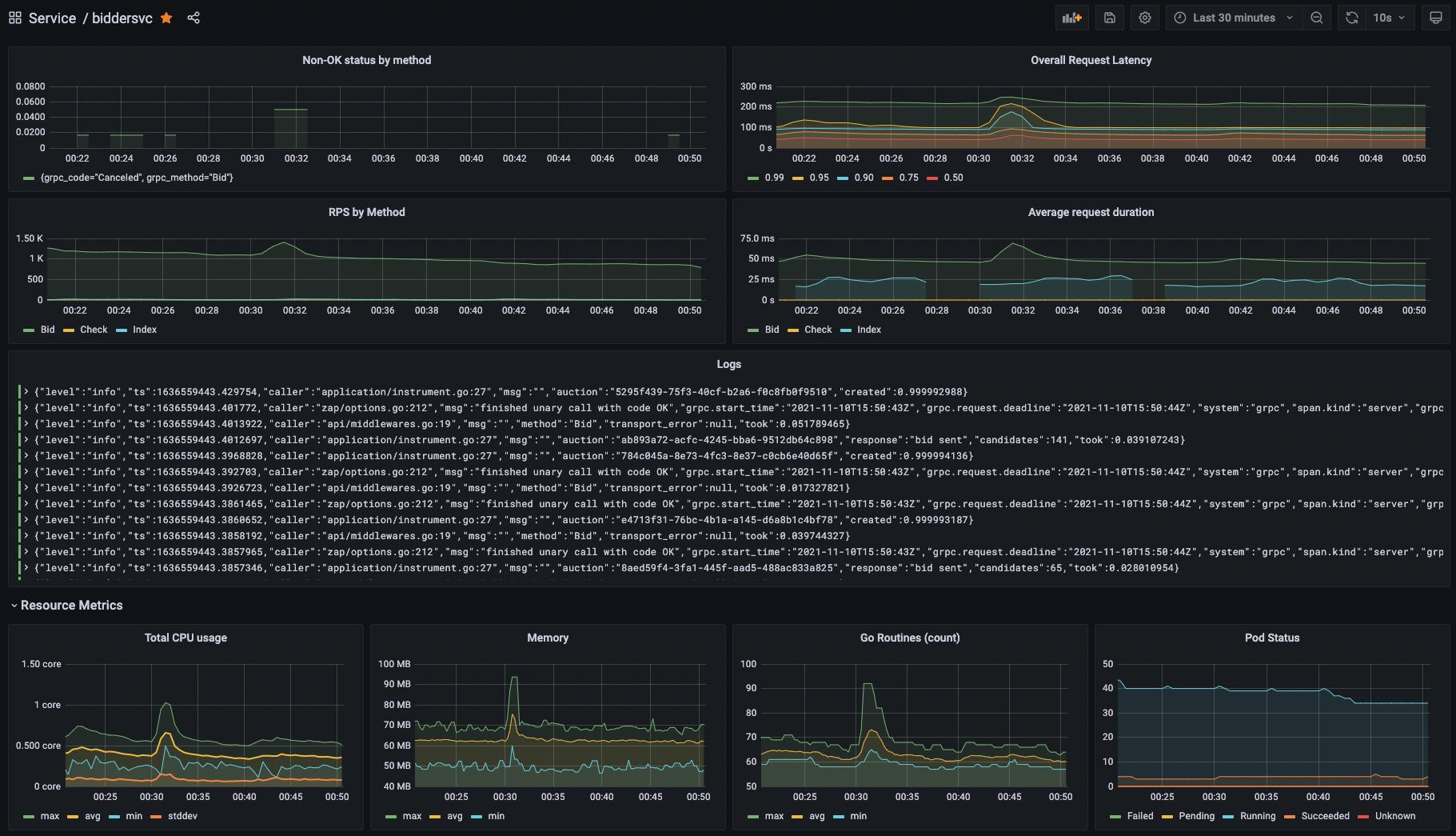
버즈빌은 관측성 스택으로 Datadog과 Prometheus 및 Grafana를 활용하고 있습니다. Kubernetes 환경을 구축하면서부터 Prometheus와 Grafana를 적극적으로 활용해오고 있지만, 전체 인프라 중 Kubernetes로 운영하는 워크로드 비율이 높아지면서 Prometheus가 처리하는 메트릭의 label cardinality가 너무 높아져서 메모리 사용량에 대한 관리가 매우 어려졌으며 OOM Kill 되는 현상이 빈번하게 발생하였습니다. 이를 해결하기 위해 Thanos를 기반으로 Prometheus HA 구성을 하고, 메트릭을 오브젝트 스토리지(S3)에 저장하고 오래된 시계열 데이터는 compaction을 통해 압축 및 다운 샘플링을 하게 되었습니다.
하지만 여전히 관측성 스택을 인하우스에서 관리하는 부담이 매우 높았고, 마이크로서비스가 추가되면서 서비스 간 호출에 대한 가시성, 즉 분산 트레이싱에 대한 요구사항이 증가하였습니다. Istio와 기존에 활용 중이던 Grafana와도 궁합이 잘 맞는 Jaeger도 고려했지만, 직접 운영하는 부담을 줄이기 위해 관리형 모니터링 솔루션인 Datadog을 전면 도입하였습니다. 특히 Datadog APM(Application Performance Monitoring)을 적극적으로 활용하면서 마이크로서비스 호출 간 병목 파악, SLO 메트릭 관리, 이상 감지 등의 모니터링이 매우 수월해졌습니다. 그 외에도 장애 관리를 위한 Incident Management, Pagerduty 통합 기능 등을 활용하고 있습니다.
버즈빌은 로그를 광범위하게 활용하고 있습니다. 서비스 가시성 및 디버깅을 위한 로그에서부터 핵심 비즈니스 메트릭 수집까지 다양한 로그가 존재하며 매일 1TB 이상의 로그가 생성됩니다. 각 서비스는 다양한 지표를 로그 스트림으로 출력하고 있고, Kubernetes에 배포된 서비스들을 위해 로그를 포워딩하는 몇 가지 메커니즘을 운용하고 있습니다.
Kubernetes를 적극적으로 활용하기 이전에 구성된 서비스들은 fluentd를 사이드카 컨테이너 형태로 파드에 함께 배치하여 S3나 Kinesis Data Streams 등으로 로그를 포워딩하고 이를 Data lake에 적재하고 있습니다. Kubernetes 도입 이후 생성된 서비스는 Kubernetes Logging Architecture에 제안된 것처럼 stdout, stderr로 모든 로그를 출력하고, 각 노드에 배포된 fluent-bit이 fluentd deployment로 로그를 포워딩하여 최종적으로 S3에 로그를 적재하고 있습니다. fluent-bit은 로그 스트림 중 JSON structured log line이 있다면 예약된 type 키에 기반하여 Data lake의 약속된 경로로 라우팅하고 있습니다.
그 외에 수일 이내의 단기 로그 저장 및 조회를 위해 Loki stack을 운영하고 있으며 주로 서비스 디버깅, 트러블슈팅 용도로 활용하고 있습니다.
버즈빌의 백엔드를 구성하는 기술 스택에 대해 간단하게 살펴보았습니다. 복잡한 광고 시스템을 도메인 기반의 마이크로서비스 아키텍처로 풀어나가면서 직면한 여러 문제를 해결해 왔습니다. 이번 포스팅에서는 전반적인 기술 스택에 대해 소개해드렸지만, 기회가 된다면 각 영역에 대해 디테일한 예시와 깊이 있는 소개를 해드리도록 하겠습니다.
버즈빌에는 여전히 해결해야 하는 문제들이 산적해 있고, 이런 고민들을 함께 해나갈 수 있는 동료를 찾고 있습니다. 관심이 있으시다면 편하게 티타임을 요청 주세요!
Written By
버즈빌에서 DevOps를 담당하고 있습니다. Cloud Native 인프라를 구현하기 위해 여러 노력을 기울이고 있으며 새로운 기술들을 공부하는 것을 좋아합니다.
Zune Seo
버즈빌은 2023년 한 해 동안 월간 약 1.2억, 연 기준으로 14억에 달하는 AWS 비용을 절약하였습니다. 그 경험과 팁을 여러 차례에 걸쳐 공유합니다. AWS 비용 최적화 Part 1: 버즈빌은 어떻게 월 1억 이상의 AWS 비용을 절약할 수 있었을까 (준비중) …
Read Article
 Abel Yoon
Abel Yoon
들어가며 안녕하세요, 버즈빌 데이터 엔지니어 Abel 입니다. 이번 포스팅에서는 데이터 파이프라인 CI 테스트에 소요되는 시간을 어떻게 7분대에서 3분대로 개선하였는지에 대해 소개하려 합니다. 배경 이전에 버즈빌의 데이터 플랫폼 팀에서 ‘셀프 서빙 데이터 …
Read Article