버즈빌 AWS 활용기
버즈빌에서는 잠금화면 리워드앱인 허니스크린 한국,일본,대만 버전과 애드네트워크인 버즈애드 그리고 잠금화면 SDK인 버즈스크린을 운영하고 있습니다. 그런데 이 모든 서비스를 현재 단 6명의 개발자가 운영하고 있어서 서버 운영 리소스를 줄이기 위해 가능한 많은 부분을 AWS에 의존하고 있습니다. AWS가 없었다면 지금의 인원으로 이 모든 서비스를 운영하는 것은 불가능했을 것입니다. 버즈빌 초기에는 EC2, ELB, RDS, S3을 활용했고 그 후 Auto Scaling, CloudFront, Lambda, DynamoDB, Route 53, Kinesis, SNS, VPC 등을 사용하기 시작했습니다. 이번 포스팅에서는 그동안 사용했던 서비스들에 대해 소개하며 유용한 팁, 그리고 제가 느낀 점들을 공유하겠습니다. 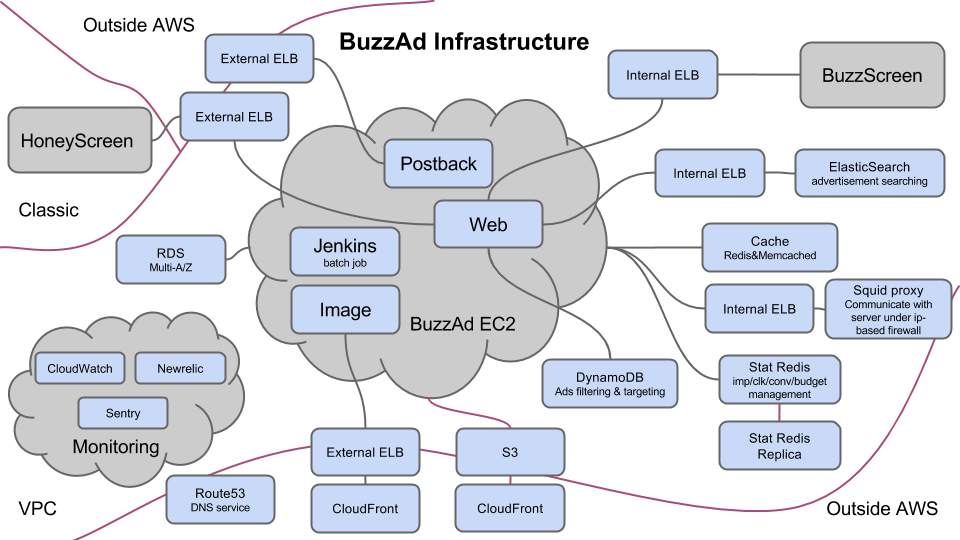 버즈애드 AWS 구조
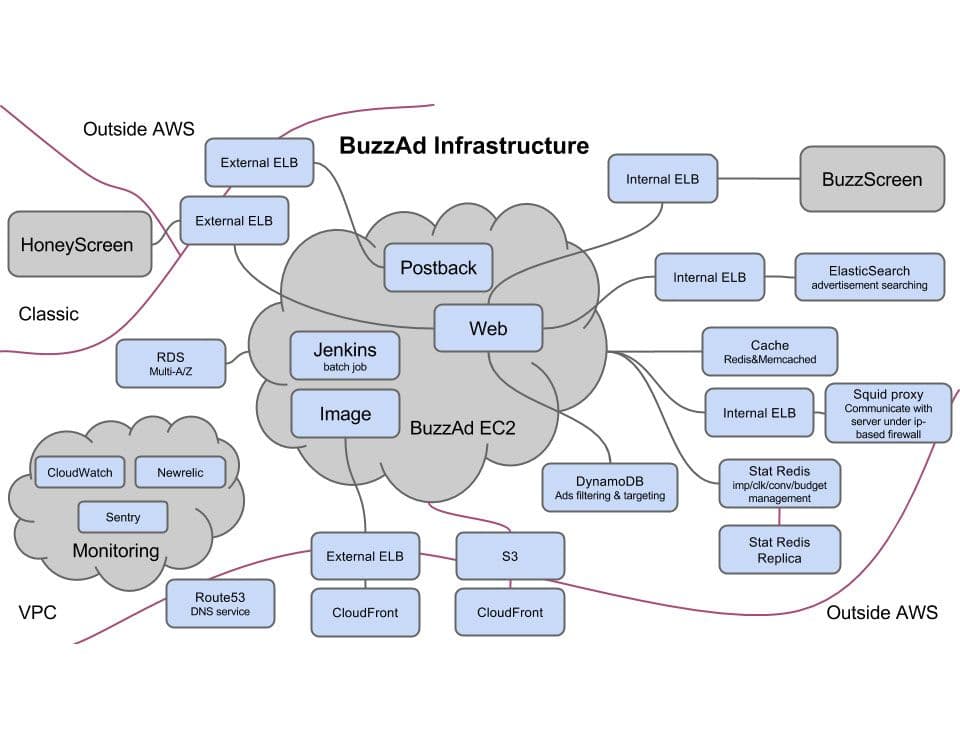
버즈애드 AWS 구조
EC2
AWS의 대표 서비스입니다. EC2인스턴스를 생성하고 사용하는 것은 간단하지만 보안성을 향상시키려면 몇 가지 고려해야 할 사항들이 있습니다. 버즈빌에서 생성하는 모든 EC2 인스턴스에는 IAM role을 적용하고 있습니다. 해당 IAM role에 각종 AWS 퍼미션을 설정해 놓으면 소스코드에 access key/secret key를 넣어놓지 않아도 되기에 보안성을 높일 수 있습니다. 이미 다양한 언어에 대해서 SDK를 지원하고 있고 IAM role이 적용된 인스턴스에서 SDK를 사용하면 별도의 설정 없이 해당 role의 권한으로 AWS서비스를 사용할 수 있습니다. Security group 설정시 source를 anywhere로 설정하지 않습니다. 실제 접속이 필요한 IP와 Port만 열어둡니다. AWS 내부 인스턴스끼리 통신이 필요할 때는 IP대신에 특정 security group에 속한 인스턴스에 대해서 접속을 허용하는 것이 가능해 버즈빌에서는 이 기능을 활용하고 있습니다. 인스턴스 런칭 시 availability zone을 선택할 수 있는데 특정 availability zone의 장애 상황을 고려해서 시스템을 설계할 것이 아니라면 모든 인스턴스를 하나의 availability zone으로 몰아 넣는 것이 좋습니다. 같은 availability zone 안의 인스턴스 사이에서 발생하는 트래픽은 비용이 들지 않지만 다른 availability간에 발생하는 트래픽에는 비용이 청구되기 때문입니다. 작년에 burstable instance인 t2인스턴스가 출시되었습니다. 기본적인 소개는 유저 가이드에 잘 나와 있습니다. t2 인스턴스를 사용하면서 착각했던 부분은 t2.micro의 CPU 100% 상태의 성능이 t2.medium의 CPU 100% 상태의 성능보다 낮을 거라고 예상했던 것입니다. 사실 둘다 vCPU는 1개로 똑같기 때문에 credit이 남아 있는 한 똑같은 성능을 가집니다. 이 부분을 잘 이해하고 있으면 조금 더 t2인스턴스를 효율적으로 활용할 수 있습니다. 예를 들어 t1.micro 인스턴스로 충분히 burst 트래픽을 감당하는 것이 가능한데 단순히 응답 시간을 줄이기 위해서 t2.medium 인스턴스로 변경하는 판단을 하지 않을 수 있습니다. 마찬가지로 CloudWatch에서 CPU 사용량을 모니터링할 때도 주의해야 합니다. 만약 t2.micro인스턴스를 사용하고 있는데 CPU 점유율이 낮다고 방심하고 있으면 안됩니다. Baseline performance가 10%밖에 안되기 때문에 평균 CPU 점유율이 10%이상이 된다면 인스턴스 타입 변경을 고려해봐야 합니다. CloudWatch에서 남아있는 CPU credit과 사용한 CPU credit을 확인할 수 있으니 잘 체크해주어야 합니다. EC2 인스턴스를 많이 운영하다 보면 비용 절약을 위해 예약 인스턴스를 사용하는 경우가 있습니다. 가격을 보면 친절하게 온 디맨드 대비 절감액이 몇 %인지 나와 있습니다. 하지만 여기에 하나 더 변수가 있습니다. 바로 새 인스턴스 타입이 출시되거나 가격이 내려갈 수 있다는 것입니다. 예약 인스턴스는 한번 구입하면 타입을 바꿀 수가 없고(다만 같은 class내에서 변경은 가능합니다. 2대의 c3.large는 1대의 c3.xlarge로 변경 가능합니다.) 중간에 가격이 내려가더라도 이미 구입한 예약 인스턴스까지 가격 인하가 적용되지는 않습니다. 예전에 c3 인스턴스가 처음 나왔을 때는 기존 인스턴스를 c3으로 교체하는 것만으로도 체감 상 거의 30%정도의 비용 절감 효과를 누렸었습니다. 대략 12년에 한 번 꼴로 새 인스턴스 class가 출시되는 것으로 보이고 가격인하도 12년에 한 번씩은 하는 것 같습니다. 사실 저희도 지금 c4 instance를 예약 인스턴스로 구매하는 방안을 고려 중인데 아직은 조금 기다리고 있습니다. 실제로 2013년 11월에 c3 인스턴스가 출시됐고 2014년 11월에 c4 인스턴스가 출시됐습니다. 예약 인스턴스를 구매하기 전에 구매하려는 인스턴스가 출시된지 오래됐거나 가격 인하가 될 것 같은 느낌(?)이 오신다면 기다려보는 것도 좋은 방법입니다.
ELB
HTTPS가 필요한 경우 ELB에서 SSL termination이 가능합니다. ELB에서 HTTPS를 HTTP로 변환하여 내부 서버로 리퀘스트를 전달하기 때문에 웹서버의 부담을 줄일 수 있습니다. ELB에는 두 가지 종류가 있습니다. 하나는 외부 트래픽을 받아서 내부로 요청을 분산하는 External ELB이고 다른 하나는 AWS 인프라 내부에서만 사용 가능한 Internal ELB입니다. 참고로 Internal ELB는 Classic 환경에서는 사용할 수 없고 VPC에서만 사용할 수 있습니다. 내부 서버간의 통신에 트래픽 분산이 필요한 경우 Internal ELB를 적극 활용할 수 있습니다. ELB는 비용이 매우 저렴하고 안정적이며 거의 무한대로 확장 가능합니다. 마이크로서비스 아키텍처에서 Scaling이 필요한 서비스의 앞 단에 Internal ELB를 배치하여 활용하기에 좋습니다. 버즈빌에서는 광고 애드네트워크인 버즈애드 뿐만 아니라 프록시 서버/엘라스틱서치 서버와 통신하는 경우에 Internal ELB를 활용하고 있습니다. 엘라스틱서치는 자체적으로 로드 밸런싱을 지원하지만 ELB를 사용하는 것이 더 안전하다고 판단하였고 1-shard/multi-replica 설정으로 ELB를 활용하기 좋은 구조였기에 Internal ELB를 사용하였습니다.
Auto Scaling
인스턴스 scale in/out을 자동화 해주는 서비스입니다. Auto Scaling을 사용하기 위해서 고려해야 할 점이 몇 가지 있습니다. 우선 인스턴스 개수가 고정적이지 않기 때문에 소스코드 배포시 배포할 인스턴스를 동적으로 찾아내는 방법이 필요합니다. 버즈빌에서는 fabric을 사용하고 있고 Auto Scaling 인스턴스에 태그를 붙여 해당 태그를 기준으로 인스턴스를 검색하여 배포를 하고 있습니다. 이와 더불어서 로그수집을 중앙에서 해야 합니다. Scale-in으로 인해 인스턴스가 종료될 때 아무 처리를 해주지 않으면 로그가 유실됩니다. 이를 막기 위해 로그를 보존하는 방법이 크게 세 가지가 있는데 첫 번째로는 logstash나 fluentd같은 log shipper를 이용해 실시간으로 로그를 중앙 서버로 이전하는 방법, 두 번째로 splunk나 loggly같은 유료 로그 수집 서비스를 이용하는 방법, 마지막으로 termination hook을 이용해 termination을 잠시 연장시키고 그 시간에 로그를 한 번에 옮기는 방법이 있습니다. 최근에는 CloudWatch에서도 로그 수집 서비스를 지원하는 것으로 알고 있습니다. 서비스 트래픽 패턴마다 다르겠지만 트래픽이 급격하게 증가하는 경우가 많다면 scale-out이 빨리 완료되도록 하는 것이 중요합니다. 그러기 위해서는 서버 설정을 위해 필요한 패키지들을 미리 설치하고 어느 정도 셋업이 완료된 AMI이미지를 준비하는 것이 scale-out시마다 발생하는 서버 셋업 시간을 줄일 수 있는 방법입니다. 그리고 CloudWatch detailed-monitoring을 켜놓아야 합니다. Auto Scaling은 CloudWatch에서 수집되는 데이터를 기반으로 scale in/out을 수행하는데 기본적으로 5분 간격으로 데이터를 수집하기 때문에 그만큼 갑작스런 트래픽 증가에 빠르게 반응할 수 없습니다. detailed-monitoring이 켜져있으면 1분 간격으로 데이터를 수집하기 때문에 좀 더 빠르게 트래픽 변화에 대응할 수 있습니다. Auto Scaling에서도 스팟 인스턴스를 사용하는 것이 가능합니다. 버즈빌에서는 Auto Scaling으로 대응할 수 없는 갑작스런 트래픽 증가나 다수의 인스턴스가 동시에 장애가 발생하는 등 예측할 수 없는 상황을 대비해 EC2 인스턴스의 CPU점유율을 60% ~ 70% 이하로 유지하고 있습니다. 이러한 예외적인 상황에 대비하기 위하여 항상 필요 이상의 인스턴스를 유지하는 것이 비효율적일 수 있습니다. 이를 해결하기 위해 하나의 서비스에 대해 Auto Scaling Group 두 개를 유지할 수도 있습니다. 하나는 온-디맨드 인스턴스 Auto Scaling Group으로 기존의 다이나믹 스케일링 설정 그대로 사용하는 것이고 스팟 인스턴스용 Auto Scaling Group을 고정 사이즈로 지정하여 여유분의 EC2 인스턴스를 운영하는 방법입니다. 이때 고정 사이즈의 크기는 갑자기 해당 스팟 인스턴스 전체가 사라지더라도 서비스에 장애가 나지 않을 정도로만 설정하는 것입니다. 한마디로 일반적인 Auto Scaling운영에 더해서 혹시 모를 상황을 대비하여 여유분의 EC2 인스턴스를 스팟 인스턴스로 활용하는 방법입니다. 스팟 인스턴스의 숫자를 조금 더 효율적으로 설정하려면 Scheduled Scaling을 활용하는 것도 좋습니다. 하나의 서비스에 대해서 동시에 여러 개의 다이나믹 스케일링 그룹을 사용하면 예측할 수 없는 결과가 발생할 수 있으므로 추천하지 않습니다.
RDS
RDS MySQL을 Multi-AZ와 함께 사용하고 있습니다. 데이터베이스 백업부터 자동화된 failover까지 데이터베이스 운영/관리에 대한 지식이 부족한 저희에게 RDS는 큰 도움이 되었습니다. 직접 데이터베이스를 운영하다보면 당장 데이터가 늘어남에 따라 데이터를 백업하고 복구하는 것 조차 쉽지 않습니다. RDS에서는 이런 부분을 알아서 해주므로 관리에 들어가는 시간을 많이 절약할 수 있습니다. 버즈빌에서 운영 중인 서비스에서는 읽기 연산을 캐시로 해결하고 있고 대부분의 트래픽이 쓰기에서 발생하고 있어 read-replica는 사용하고 있지 않습니다. 하지만 데이터베이스 장애 시 다운 타임을 줄이기 위해 Multi-AZ를 사용하고 있습니다. Multi-AZ를 사용하게 되면 기존 대비 두 배의 비용이 들어가지만 서비스의 안전성을 위해 눈물을 머금고 사용하고 있습니다. 동작방식은 read-replica와 비슷한 것으로 알고 있지만 Multi-AZ로 생성된 replica 인스턴스에는 읽기 요청을 보낼 수 없고 오직 장애 상황에서 failover를 하는 데 사용하거나 인스턴스 재부팅 시에만 사용하게 됩니다. Mutli-AZ를 사용할 경우 인스턴스 scale-up이나 MySQL 버전 업그레이드와 같이 재부팅을 해야 하는 상황에서 발생하는 다운타임을 줄일 수 있습니다. 하지만 Multi-AZ를 사용한다고 해도 순식간에 재부팅이 되지는 않고 3분 ~ 5분 정도는 걸리는 것 같습니다. 한편 RDS를 사용하면서 도움을 많이 받는 부분 중 하나가 스냅샷을 통한 복구입니다. 예를 들어 스키마 변경 등의 큰 작업을 진행할 때 실제 데이터가 존재하는 상황에서 테스트를 해보고 싶을 경우 전날 스냅샷을 복구해서 테스트를 해보고 이를 실제 데이터베이스에 적용할 수 있습니다. 실제 데이터를 이용해 코드를 테스트해보고 싶은 경우에도 전날 스냅샷을 micro인스턴스로 복구해 사용할 수 있습니다. 최근 MySQL과 100% 호환이 되면서 성능은 다섯 배까지 좋다는 Aurora를 사용하려고 검토를 해봤으나 안타깝게도 Aurora가 micro 인스턴스를 지원하지 않아 포기하였습니다. 스냅샷을 통해 손쉽게 운영 데이터를 다른 인스턴스에 복구 할 수 있다는 것, micro인스턴스를 이용해 적은 비용으로 여러 가지 테스트를 해 볼 수 있는 것은 RDS의 큰 장점입니다. RDS 런칭 시 주의하셔야 할 부분 중 하나는 처음에 Allocated-storage사이즈를 필요 이상으로 크게 잡으면 안된다는 것입니다. 운영 중에 크기를 늘리는 것은 가능하지만 줄이는 것은 불가능합니다. 저희는 처음에 이를 모르고 1TB를 잡고 서비스를 런칭하였는데 스토리지 비용으로만 한달에 약 10만원 이상이 나갔습니다. 개발 시에는 10GB정도로 런칭시에는 50GB정도로 시작하여 점차 늘려나가는 것을 추천합니다.
DynamoDB
DynamoDB는 AWS에서 제공하는 NoSQL서비스입니다. NoSQL이기에 트랜잭션이 지원되지 않거나 인덱스를 추가하는 데 제약이 있는 등 여러 가지 불편한 점들이 있지만 운영하는 서비스의 특성에 맞게 잘 활용한다면 쉽게 성능 확장이 가능한 데이터베이스로 사용할 수 있습니다. 기본적으로 읽기에 비해 쓰기가 5배 비쌉니다. 게다가 Strongly Consistent Read가 아닌 Eventually Consistent Read를 활용하면 읽기 비용이 반으로 줄게되어 결과적으로 쓰기가 10배 비싸게 됩니다. 여기에 필요에 따라 secondary index를 몇 개 더 추가한다면 쓰기 비용은 또 몇 배 올라가게 됩니다. 따라서 DynamoDB를 write intensive한 목적으로 사용한다면 비용이 많이 들 수 있음을 우선 인지해야 합니다. 이를 조금이라도 해결하기 위해 쓰기 요청을 비동기로 처리하여 write peak를 줄이는 방법 또는 동적으로 capacity를 조절할 수 있습니다. 하지만 관리 리소스를 줄이기 위해서 DynamoDB를 사용하는데 비용 절약을 위해 또 다시 관리 리소스를 들이는 것이라 선뜻 적용하기에는 어려운 부분이 있습니다. Eventually Consistent Write나 Capacity Auto Scaling과 같은 기능이 AWS에서 직접 지원된다면 참 좋을 것 같습니다. DynamoDB는 비용 계산하는 것이 상당히 까다롭습니다. 예를들어 Read/Write시 item size에 따라 capacity 소비량이 달라지기 때문에 item size가 어떻게 계산되는지 알아야 합니다. 이때 Item size를 구하는 공식 또한 그리 간단하지 않습니다. 심지어 attribute name의 길이까지 item size에 크게 영향을 미칠 수 있기 때문에 read/write operation에서 capacity가 1이상 들어간다면 attribute name을 짧게 하는 것을 고려해야 할 수도 있습니다. 이 외에도 write operation에서 secondary index를 얼마나 사용하느냐, secondary index를 이용한 read 패턴이 어떻게 다른지에 따라 비용이 달라지는 등 고려해야 할 사항이 수도 없이 많습니다. 때문에 실제로 DynamoDB를 도입할 계획이 있다면 공식 문서를 처음부터 끝까지 정독하는 것을 권장합니다. 문서를 읽다보면 '아 정말 모든것이 돈이구나'라고 느끼게 됩니다. 관리비용은 0에 가깝지만 이를 제대로 쓰기 위해서는 초기 학습비용이 만만치 않습니다. 대신 잘만 활용한다면 유용한 서비스임에는 틀림 없는 것 같습니다.
ElasticCache
AWS에서 제공하는 서비스를 사용하는 것이 기본 정책이지만 버즈빌에서는 예외적으로 ElasticCache는 사용하지 않고 있습니다. Memcached의 경우 패키지 관리자를 이용하면 커맨드 한 번에 설치가 가능하고 설정 또한 memory limit과 허용할 IP설정 정도를 지정하는 것 외에는 특별히 건드릴 것이 없습니다. 게다가 Memcached가 충분히 안정적으로 동작하는 것이 검증되었기에 직접 운영을 한다고 해도 관리 비용이 크게 들지 않습니다. EC2위에서 직접 운영하는 것 대비 ElasticCache의 비용이 약 25%이상 비쌉니다. ElasticCache에서는 Memcached 외에도 Redis를 지원합니다. 버즈빌에서는 Redis를 cache로 쓰는 것에서 더 나아가서 광고의 Click/Impression/Conversion 데이터까지 관리하는 persistence로 사용할 정도로 적극적으로 활용하고 있습니다. 하지만 ElasticCache의 Redis는 persistence보다는 cache용으로 사용하는 것에 초점이 맞춰져 있는듯한 인상이 강합니다. 인스턴스 장애시 데이터 유실을 최소화할 수 있는 AOF옵션을 켤 수 있지만 ElasticCache는 EBS가 아닌 local instance store를 사용하기 때문에 인스턴스 재부팅시 데이터가 소실 됩니다. AOF대신 Multi-AZ를 사용할 것을 권장하지만 어쨌든 데이터가 디스크에 저장되어 있지 않고 메모리에 있다는 사실이 찜찜했습니다. 그래서 ElasticCache를 활용하는 대신 관리비용이 들더라도 Redis를 직접 설치해서 운영하고 있습니다.
S3 & CloudFront
S3에 올려진 이미지 등의 컨텐츠들은 CloudFront를 통해서 서빙되고 있습니다. 요금표(S3, CloudFront)에서 볼 수 있듯이 S3과 CloudFront간의 비용 차이가 크지 않습니다. 도쿄 리전 기준으로 S3과 CloudFront에서 외부로 발생하는 트래픽 비용은 동일하며 요청 횟수당 비용이 CloudFront가 2배 정도 되는데 파일 사이즈에 따라 다르겠지만 트래픽 비용 대비 작은 부분을 차지합니다. 오리진에서 엣지 로케이션으로 전송하는 데이터 비용은 무료입니다. 따라서 가능하면 CloudFront를 활용하는 것이 좋습니다. 게다가 CloudFront는 10TB이상의 트래픽이 발생하면 연간 계약을 통해 할인을 받을 수 있습니다. 게다가 S3 오리진이 도쿄에 있는데 미국/유럽에서 트래픽이 많이 발생하는 경우 오히려 CloudFront를 이용하는 것이 더 쌀 수도 있습니다. 미국/유럽에서 발생하는 트래픽 요금이 상대적으로 싸기 때문입니다. CloudFront는 오리진으로 S3이 아닌 ELB 지정하는 것이 가능합니다. 만약 웹서버의 응답이 캐싱 가능하다면 CloudFront를 활용하는 것도 가능합니다. 버즈빌에서는 컨텐츠와 일부 광고 이미지를 자동으로 생성해주는 이미지서버가 있는데 CloudFront를 활용하여 한 번 생성한 이미지는 캐싱을 하여 사용하고 있습니다. 하지만 CloudFront 사용 시 file invalidation이 다소 불편합니다. Invalidation이 완료되기 까지 시간이 걸리고 추가 비용도 발생합니다. 따라서 파일을 수정할 필요가 있는 경우 이름을 변경하여 invalidation이 필요 없도록 하는 것이 좋습니다.
Route 53
ELB 또는 CloudFront distributions를 지정할 때 CNAME대신 Alias를 활용하고 있습니다. Alias쿼리는 무료이기 때문에 조금이나마 비용을 절약할 수 있습니다. Alias쿼리는 CNAME과 비슷하게 보이지만 실제 동작은 A 레코드를 리턴하는 방식이기 때문에 CNAME처럼 두 번의 DNS 쿼리가 필요한 경우가 없습니다. 따라서 DNS쿼리 성능에 있어서도 CNAME보다는 아주 조금이지만 더 좋다고 볼 수 있습니다. Alias를 사용하면 안되는 특별한 이유가 있지 않다면 Alias를 활용하는 것을 추천합니다.
Lambda
AWS 예제에 잘 나와있듯이 자동화된 이미지 리사이징을 위해 사용하고 있습니다. S3에 원본 이미지가 올라오는 이벤트를 받아 다양한 크기의 이미지를 재생성하여 업로드합니다. 버즈빌에서는 이미지 전송으로 인해 발생하는 트래픽을 줄이기 위해 WEBP포맷을 적극적으로 활용하고 있습니다. 하지만 성능이 낮은 클라이언트에서는 WEBP 렌더링 시간이 많이 걸리므로 JPEG포맷을 사용합니다. 이를 위해서 이미지는 항상 JPEG와 WEBP 두 개의 포맷으로 업로드해야 합니다. 현재는 웹서버 로직에서 WEBP변환을 하고 있지만 추후에는 이 부분도 Lambda를 이용해 처리할 계획입니다. 버즈빌에서 주로 사용하는 언어는 Python인데 현재 Node.js, Java에 더해서 최근에는 Python을 지원하기 시작해 조금 더 편하게 Lambda를 사용할 수 있게 되었습니다.
Kinesis
웹 서버의 로그 수집을 위해 Kinesis를 활용하고 있습니다. 각 서버에서는 fluentd가 Kinesis로 실시간으로 로그를 전송하고 별도의 인스턴스에서 Kinesis로부터 로그를 가져와 저장합니다. 실제로 Kinesis를 사용해보니 한 가지 불편한 점이 있었습니다. Kinesis 스트림은 내부적으로 여러 개의 샤드로 구성되어 있고 처리량을 늘리기 위해서는 샤드를 늘려야 하는데 GUI 콘솔에서는 샤드 개수를 수정하는 것이 불가능합니다. 오직 API를 이용해서만 가능하며 이 또한 key rebalancing을 직접 고려해서 코드를 작성해야 합니다. 뿐만 아니라 스트림으로부터 데이터를 가져오는 consumer 쪽에서도 샤드 개수 변화에 따른 고려를 해줘야 합니다. 처음에는 Kinesis의 스트림을 하나의 커다란 큐로 보고 사용만 하면 되는 줄 알았지만 스트림 내부의 샤드를 고려해야 해 생각보다 관리에 있어서 불편한 점이 있습니다. Consumer쪽 로직은 아마존에서 제공하는 Kinesis Client Library를 적극 활용하는 것을 추천합니다. Application 로직을 제외한 모든 부분을 KCL이 잘 추상화하여 관리해주기 때문에 개발자 입장에서 편하게 개발 할 수 있습니다. Kinesis 사용기와 관련된 자세한 부분은 추후 블로그 포스팅을 통해 더 상세하게 다뤄보겠습니다.
계정관리
기본적으로 root account는 사용하지 않고 IAM 유저를 생성해서 사용하고 있습니다. 가끔씩 AWS계정을 해킹당해 엄청난 비용이 청구됐다는 글을 볼 수 있습니다. 이를 방지하기 위해서는 MFA설정을 하는 것이 좋습니다. MFA 설정을 하면 OTP를 이용해 한 번 더 인증을 진행하므로 보안성을 크게 향상시킬 수 있습니다. 그런데 root account에 MFA를 설정했다가 핸드폰이 고장나거나 분실되는 경우 이를 복구하는 것이 상당히 귀찮을 수 있습니다. 이를 막기 위한 한 가지 팁은 QR코드를 이용해서 디바이스를 등록 할 때 다른 기기(예를 들면 가지고 있는 아이패드)도 같이 등록하는 것입니다. 이렇게 하면 동시에 여러 개의 기기를 등록할 수 있어 핸드폰 분실 등 유사시에 대비를 할 수 있습니다. 또는 QR코드를 캡쳐해서 프린트한 뒤 따로 보관해도 됩니다. 하지만 캡쳐한 QR코드 파일을 컴퓨터에 보관하는 것은 위험하므로 꼭 삭제해야 합니다.
마치며
지금까지 버즈빌에서 사용하고 있는 AWS 서비스에 대해 소개했습니다. 기본적인 사용법에 관해서는 이미 많은 자료들이 있기 때문에 실제로 버즈빌에서 시스템을 운영하며 알게된 팁을 위주로 설명했습니다. 이 글을 정리하면서 느낀 점은 AWS 역시 계속 발전하고 있다는 것입니다. 사실 일 년에도 몇 개씩 새로운 서비스가 출시되고 있는 것을 보면 저걸 다 어떻게 유지, 보수를 하는건지 저희가 걱정이 될 정도입니다. 하지만 이는 그만큼 기술 혁신을 위해 아마존에서도 많은 노력을 하고 있다는 뜻입니다. 그렇기에 다른 클라우드 사업자들이 AWS를 따라잡기가 쉽지는 않을 것 같습니다. 또한 AWS에서는 여러 종류의 블로그를 운영하고 있습니다. 그 중에서도 AWS 공식 블로그에서는 각종 서비스 업데이트 소식, 새로운 서비스 런칭 소식, 가격 인하 소식 및 여러가지 팁 등을 소개하고 있어 많은 도움이 됩니다. 이것으로 버즈빌에서 AWS를 어떻게 활용하고 있는지에 대한 소개를 마치겠습니다. 앞으로도 AWS에서 유용한 서비스들이 많이 나왔으면 좋겠습니다. 다음 포스팅에서는 이러한 인프라 위에서 동작하고 있는 버즈애드 서버의 아키텍처에 대해서 자세하게 다뤄보겠습니다.

