
Self Serving Data Platform 구축하기 (feat. Airflow)
Data Engineer
Introduction
안녕하세요. 버즈빌 데이터 엔지니어 Bernard입니다. 이번 포스팅에서는 저희 팀에서 어떻게 셀프 서빙 데이터 플랫폼을 구축했는지 소개하고자 합니다. 셀프 서빙 데이터 플랫폼이란, 특정 팀에 의존하지 않고 구성원 누구나 원하는 데이터를 스스로 생산 및 소비할 수 있는 플랫폼을 의미합니다. 과거에는, 서버팀 혹은 데이터 분석팀에서 데이터 파이프라인 생성 요청이 들어오면 데이터 엔지니어가 필요한 파이프라인을 구축했습니다. 그러나 버즈빌의 서비스와 분석 도메인이 다양해지면서 모든 파이프라인을 운영, 관리하는데 인지 부하가 발생했습니다. 또한 각 팀에서도 데이터를 적시에 조회하기 위해 데이터 엔지니어에게 의존하게 되어 불편함이 커졌습니다. 이에 도메인의 전문성을 적극 활용할 수 있는 셀프 서빙 데이터 플랫폼을 개발하기 시작했습니다.
버즈빌의 데이터 인프라
먼저 버즈빌 데이터 인프라에 대해서 간략하게 소개해 드리겠습니다. 저희가 사용하는 주요 데이터 컴포넌트들은 다음과 같습니다.
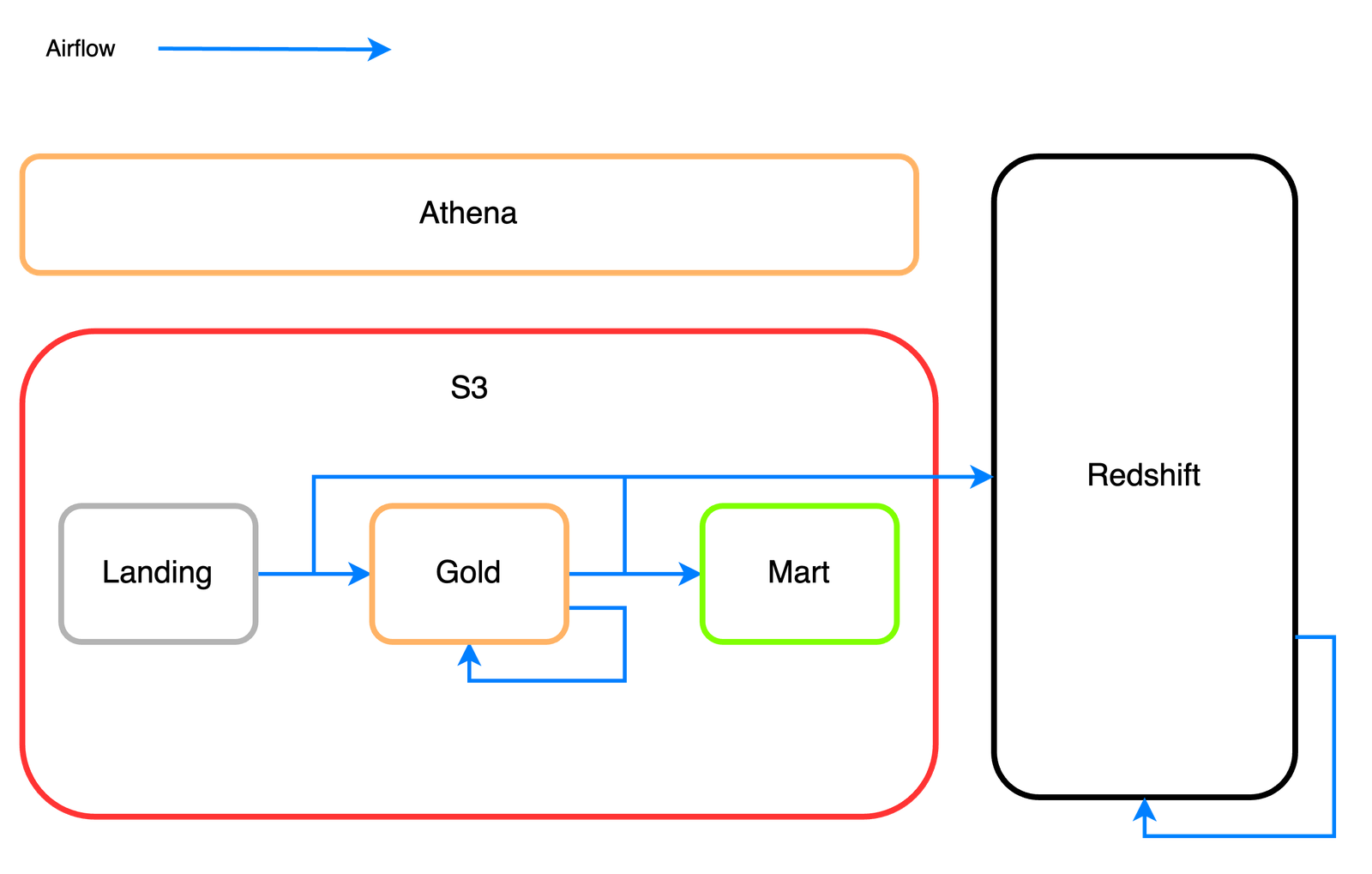
- Athena/S3
S3는 AWS에서 제공하는 스토리지 서비스입니다. 확장성이 뛰어나며, 저장하는 데이터양에 비해 비용도 저렴합니다. 버즈빌에서는 모든 데이터를 S3로 1차 저장하며 SSOT(Single Source of Truth)로 활용하고 있습니다. S3에 저장하고 있는 데이터 종류는 다음과 같습니다.
- landing: 운영계로부터 최초 수집된 데이터
- gold: 저장/압축 및 간단한 전처리를 적용한 데이터
- mart: 비즈니스 레벨에서 자주 조회가 필요한 메트릭들을 집계한 데이터
Athena는 표준 SQL을 사용해 Amazon S3에 저장된 데이터를 간편하게 분석할 수 있는 대화식 쿼리 서비스입니다. 서버리스 서비스로 관리할 인프라가 없고 실행한 쿼리에 대해서만 비용을 지불하면 됩니다. Trino 기반의 쿼리 엔진을 사용 중이며 대용량 데이터 처리에 강점을 가집니다. 버즈빌에서는 Athena를 통해 Redshift에서 처리하기 힘든 대용량 데이터들을 전처리 및 쿼리 합니다.
- Redshift
Redshift는 AWS의 데이터 웨어하우스 서비스입니다. 대량 병렬 처리를 통해 복잡한 쿼리라도 빠른 속도로 실행 가능하며, 일반 RDBMS처럼 쿼리가 가능하기 때문에 Athena보다 사용성이 높습니다. 또한, 온디맨드로 클러스터 비용을 지불하는 방식이라 스캔한 데이터 양에 비례하여 비용을 지불하는 Athena보다 쿼리 비용에 대한 부담이 적습니다. 때문에, 비즈니스단에서 adhoc 한 쿼리를 실행하거나 대시보드를 생성하는 용도로 사용합니다.
- Airflow
Airflow는 Airbnb에서 개발한 오픈소스 데이터 파이프라인 관리 툴입니다. 다양한 스케줄링 기능들을 제공하며 WEB UI를 통해 상세한 모니터링이 가능하다는 점에서 많은 기업이 채택하여 사용 중입니다. 버즈빌에서는 운영계 데이터를 분석계로 동기화하는 작업, 마트 데이터 집계 및 스케줄링을 하는 데 주로 사용하고 있습니다.
분석가/엔지니어를 위한 셀프 서빙 플랫폼
데이터 파이프라인을 생성하기 위해서 위에 소개해 드린 데이터 플랫폼 컴포넌트들을 학습해야 합니다. 예를 들어, 데이터 분석가가 Daily Active User 정보가 담긴 Athena 테이블을 집계하고 스케줄링하려고 합니다. 이때, 아래와 같은 사항들을 고려해야 합니다.
-
파티셔닝을 어떻게 적용할 것인가?
- 파티셔닝이란 데이터를 분할 저장하여 일부 데이터만 검색할 수 있도록 하는 기법입니다. 파티셔닝 컬럼으로 필터링하여 쿼리 비용을 절감하고 쿼리 성능을 높일 수 있습니다. 특히 Athena는 스캔한 데이터 양에 비례하여 과금하기 때문에 파티셔닝을 적용하는 것이 중요합니다.
- 버즈빌 내에서는 공통으로
/year=2023/month=05/day=29/hour=12와 같이 hour 단위까지의 prefix를 파티션으로 활용 중입니다. 필요에 따라 daily, monthly 파티셔닝 적용이 되는 경우가 있습니다. - 쿼리로 직접 파티셔닝 컬럼과 저장 경로 prefix를 매핑해주거나 AWS Glue의 crawler 기능을 이용하여 자동으로 적용할 수 있습니다.
-
원천 데이터의 완전성을 어떻게 보장할 것인가?
- 원천 데이터가 완전하지 않은 상태에서 마트 테이블을 집계하는 경우가 종종 발생합니다. 예시로 Daily Active User를 계산할 때, 원천 데이터인 유저 행동 데이터가 delay로 인해 늦게 채워질 수 있습니다.
- 이를 해결하기 위해서는 Airflow에 Sensor 기능을 활용할 수 있습니다. Airflow에서는 ExternalTaskSensor를 통해 다른 Dag의 success 기록이 있어야만 해당 Dag가 실행될 수 있도록 dag 간의 dependency를 적용할 수 있습니다. 원천 데이터가 모두 채워져 있는지 체크하는 dag를 upstream dag로 설정하여 데이터의 완전성을 보장할 수 있습니다.
-
데이터 파이프라인이 멱등성을 보장하는가?
- 멱등성을 보장하는 데이터 파이프라인이란, 동일한 입력 데이터로 데이터 파이프라인이 여러 번 실행되더라도 결과가 달라지지 않는다는 뜻입니다. 멱등성을 보장하여 구성하면 장애 발생 시 재실행을 통해 쉽게 복구가 가능하다는 이점이 있습니다. 이를 위해서는 delete 로직을 앞에 넣어주어 과거 데이터를 초기화시켜 주는 작업이 필요합니다.
데이터 파이프라인 생성에 대한 가이드를 제공하더라도 러닝 커브는 여전히 높습니다. 버즈빌에서는 위 내용들을 추상화하여 간단한 YAML 파일 작성을 통해 Airflow Dag를 생성할 수 있도록 템플릿을 제공했습니다. 사용자는 Airflow, Athena, Redshift를 따로 학습할 필요 없이 빠르게 데이터 파이프라인을 생성할 수 있습니다. YAML 파일 예시는 다음과 같습니다.
---
pipeline_key: dau
pipeline_type: athena_process
pipeline_dag_configs:
start_date: 2023-03-01 15:00:00
schedule_interval: "0 15 * * *"
upstream_dependencies:
- dag_id: check_data_athena_ad_request__24hr_kst_existence
athena:
process_query: |
SELECT DISTINCT
viewer_id AS viewer_id,
DATE_TRUNC('day', date) AS kst_at
FROM
ad_request
WHERE
partition_timestamp >= TIMESTAMP'{var[start_time]}' AND
partition_timestamp < TIMESTAMP'{var[end_time]}' AND
output_bucket: "buzzvil-example-bucket"
output_prefix: buzzvil/gold/dau/year={var[year]}/month={var[month]}/day={var[day]}
table: m_dau
columns:
- name: viewer_id
type: STRING
- name: unit_id
type: BIGINT
YAML 파일 내의 config 들에 대한 설명
pipeline_key: 파이프라인의 이름입니다. airflow에서 dag_id 생성 시 이 값을 사용합니다.pipeline_type: 파이프라인의 타입입니다. Athena 테이블을 생성하는 작업을 스케줄링하는 경우 athena_process 파이프라인을 사용합니다. 이외에도 redshift 테이블을 스케줄링 하는 경우, mysql에 있는 데이터를 s3로 내리는 파이프라인 등이 있으며 데이터 파이프라인 목적에 맞게 설정합니다.pipeline_dag_configs: start_date와 shedule_interval와 같은 dag config를 여기서 설정합니다. daily active user를 스케줄링하는 경우 매일 정각에 실행되기 때문에 “0 15 * * *”으로 설정했습니다.upstream_dependencies: dag 간의 upstream dependency를 설정하는 config입니다. 원천 테이블의 최근 24시간 데이터가 모두 들어왔는지 확인하는 dag를 upstream으로 설정합니다.athena.process_query: Athena에서 수행할 쿼리를 설정합니다. Jinja template을 적용하여 parameterize된 변수들을 활용할 수 있도록 커스터마이징했습니다. var[start_time]과 var[end_time]은 airflow의 data_interval_start와 data_interval_end가 채워집니다.athena.output_bucket: athena.process_query에서 수행된 결과 데이터를 저장할 S3 bucket name입니다.athena.output_prefix: athena.process_query에서 수행된 결과 데이터를 저장할 S3 bucket_prefix입니다. Jinja template이 적용되어 date_interval_start의 year, month, day 정보가 각각 {var[year]}, {var[month]}, {var[day]}로 변환됩니다athena.table,athena.columns: Athena 테이블 스키마 정보입니다.
위 YAML 파일은 아래 그림과 같은 Dag로 변환됩니다.
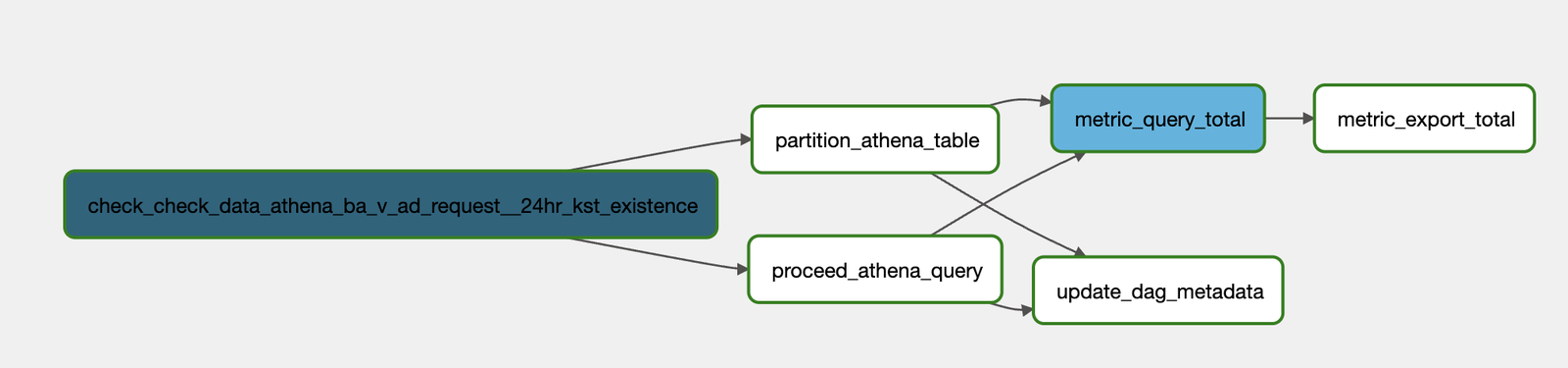
dag의 각 task에 대한 설명
check_data_athena_ba_v_ad_request__24hr_kst_existence: 소스 테이블인 ba_v_ad_request 테이블이 24시간 동안 데이터가 완전하게 들어왔는지 체크하는 dag입니다.
procced_athena_query: 입력된 쿼리를 바탕으로 Athena의 CTAS 쿼리를 실행하여 생성된 데이터를 s3에 저장하는 역할을 합니다. 멱등성을 보장하기 위해 해당 경로에 미리 생성된 데이터가 있다면 먼저 삭제를 진행하는 작업도 이 task 안에 포함되어 있습니다.
partition_athena_table: yaml 파일 내의 output_prefix 경로를 파티셔닝 컬럼으로 수동 매핑해줍니다. 수동 매핑 작업도 파이프라인에 포함되어 스케줄링됩니다.
metric_query_total, metric_export_total, update_dag_metadata : dag의 통계 정보들을 수집하는 task입니다.
YAML 템플릿에서 생성된 Dag는 데이터 파이프라인 생성 시 고려해야 하는 문제들을 다음과 같이 추상화하여 해결했습니다. 사용자는 Airflow의 다양한 기능 등을 학습할 필요가 없어졌으며, Athena 테이블을 조회하기 위해 필요한 작업을 직접 구현할 필요가 없어졌습니다.
-
파티셔닝을 어떻게 적용할 것인가?.
- YAML 파일에서 파티셔닝을 적용할 prefix을 설정해 주면
partition_athena_tabletask에서 매핑 작업이 자동으로 스케줄링 됩니다. 매핑 방법을 고민할 필요 없이 prefix를 입력만 해주면 파티셔닝이 함께 적용됩니다.
- YAML 파일에서 파티셔닝을 적용할 prefix을 설정해 주면
-
소스 데이터의 완전성을 어떻게 보장할 것인가?
- Airflow의 Sensor 기능을 이해할 필요 없이 yaml 내의
upstream_dependency값을 입력하면 자동으로 다른 dag와 dependency가 추가가 됩니다.
- Airflow의 Sensor 기능을 이해할 필요 없이 yaml 내의
-
데이터 파이프라인이 멱등성을 보장하는가?
proceed_athena_querytask에서 쿼리 실행 결과를 S3에 저장할 때 해당 경로의 파일들을 지우는 작업을 선행합니다. 사용자는 멱등성 개념을 직접 구현하지 않아도, 파이프라인에서 자동으로 적용이 됩니다.
코드 구성
지금까지의 예시는 Athena 테이블을 스케줄링하는 파이프라인이었습니다. 마찬가지로 Redshift 테이블을 스케줄링하는 파이프라인, S3에서 Mysql로 동기화하는 파이프라인 등 다양한 목적의 파이프라인들이 필요했습니다. 비슷한 형태의 파이프라인이 반복적으로 생겨났기에, 팩토리 패턴을 적용하여 반복적인 코드 작성을 줄이고 DAG의 생성과 관리를 자동화하였습니다. 팩토리 패턴의 구현은 아래와 같습니다
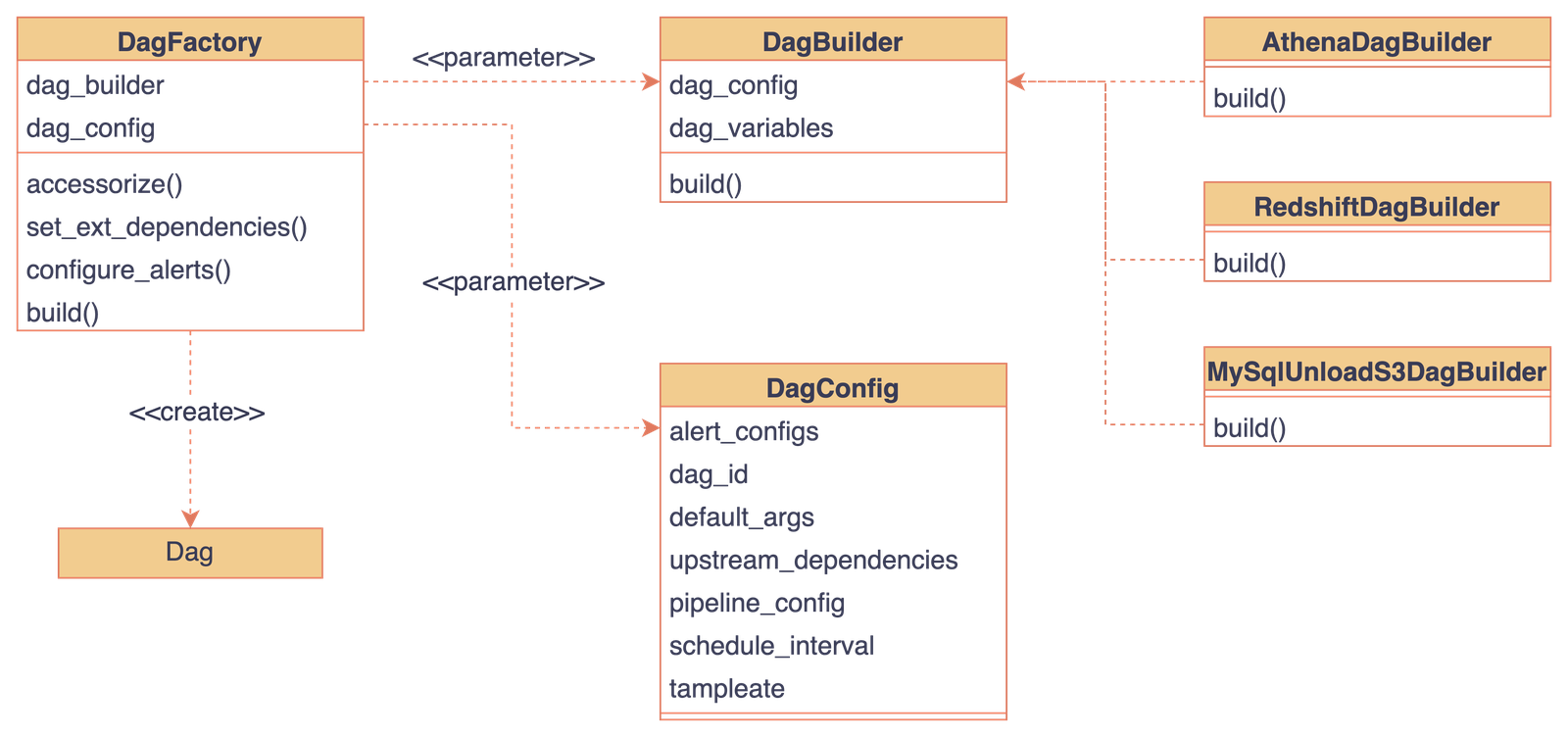
DagBuilder라는 추상 베이스 클래스를 만들고 이 인터페이스를 사용하여 필요한 파이프라인들을 추가합니다. 이를 통해, 기존 코드의 수정 없이 새로운 파이프라인을 추가/수정할 수 있었습니다. 예를 들어, Mysql에서 S3로 동기화하는 파이프라인이 필요한 경우 MysqlUnloadS3DagBuilder를 구현하여 새로 추가해 주면 됩니다. DagConfig 클래스는 Dag 구성에 필요한 명세들을 받습니다. 최종적으로 DagFactory 클래스에서는 Dag Builder와 Dag Config를 받아 Dag를 생성하게 됩니다.
사내에서 관리하는 airflow 깃 레포지토리 안에는 각 파이프라인에 해당하는 폴더들이 있습니다. 사용자는 각자 자신이 사용하려는 파이프라인 아래에 YAML 파일을 추가합니다. 각 YAML 파일은 폴더의 DagBuilder를 받아서 dag로 생성됩니다.
Airflow Pipeline
├── ...
├── athena_process
│ ├─- dau.yaml # athena_process_dau라는 dag로 변경됨.
│ ├── mau.yaml
│ ├── example_1.yaml
│ └── example_2.yaml
└── mysql_unload_s3
├── example_1.yaml # mysql_unload_s3_example_1 dag로 변경됨
├── example_2.yaml
└── example_3.yaml
마치면서
데이터 엔지니어가 사내의 모든 데이터 파이프라인을 관리하기는 어려운 일입니다. 데이터 파이프라인 생성에 필요한 데이터 맥락을 이해하는 데 큰 시간이 소요되며, 반복적인 업무는 디모티베이션을 일으킵니다. 버즈빌에서는 이러한 문제를 해결하기 위해 셀프 서빙 데이터 플랫폼 구축을 시도했고, 결과적으로 각 도메인의 전문성도 살리면서 데이터 엔지니어는 플랫폼 기능 강화에 더욱 집중할 수 있게 됩니다. 비슷한 고민을 하는 팀이 있다면 이 글이 도움이 됐으면 좋겠습니다.

