
버즈빌의 ML 플랫폼 Buzzflow (1) - 모델을 개발하고 관리하기
MLOps Engineer
들어가며
안녕하세요, 버즈빌에서 MLOps 엔지니어로 일하고 있는 BK입니다. 버즈빌 광고 플랫폼 팀은 광고 성과 최적화를 위해서 다양한 머신러닝 모델을 활용하고 있습니다. 앞으로 두 편의 글을 통해 모델을 개발, 관리, 배포하기 위한 버즈빌의 머신러닝 플랫폼 buzzflow가 어떤 식으로 구성되어 있는지 여러분께 소개해 드리고자 합니다.
이번 글에서는 모델을 개발하고, 관리하기 위해 필요한 파이프라인이나 모델 저장소 등에 대해 다루고 이렇게 개발한 모델을 배포하는 방법에 대해서는 다른 글을 통해 보여드릴 예정입니다.
BB(Before Buzzflow)
buzzflow 개발 이전에는 머신러닝 파이프라인을 어떻게 작성해야 하는지에 대한 Best practice가 명확하지 않아 각자 다른 스타일로 파이프라인을 작성하고 있었습니다. 이는 다른 사람들이 작업을 리뷰하거나 추가 작업을 하기 어렵게 만들었습니다. 또 모델 저장소로 MLFlow와 Sagemaker Model Registry를 혼용하고 있어 이 또한 통일이 필요한 상황이었습니다.
게다가 권한이 있는 사람이면 누구나 자유롭게 파이프라인을 생성하고 변경할 수 있었기 때문에 상용 환경에서 실행되는 파이프라인과 Github에서 관리하는 버전이 다른 경우도 존재했습니다.
버즈빌에서는 머신러닝 파이프라인을 위해 AWS의 Sagemaker Pipeline을 사용하고 있는데요. 이 Sagemaker Pipeline SDK의 단점도 있었습니다. 파이프라인을 개발하는 입장에서 가장 불편하게 느껴졌던 부분은 머신러닝 프레임워크마다 다른 파라미터를 가지고 있거나 동일한 기능을 하는 파라미터임에도 불구하고 다른 이름을 사용하고 있는 것이었습니다.
예를 들어 Processing에 사용하는 Processor와 Training에 사용하는 Estimator의 네트워크 설정의 경우 사실상 동일한 기능을 사용하고 있지만 파라미터의 형태가 다릅니다. 코드를 확인해 보면 Processor의 경우 NetworkConfig 형태로 네트워크 관련 설정을 전달받고 있지만 Estimator의 경우 NetworkConfig 없이 바로 네트워크 설정을 전달받고 있다는 것을 확인할 수 있습니다.
class Processor(object):
"""Handles Amazon SageMaker Processing tasks."""
def __init__(
self,
...
network_config: Optional[NetworkConfig] = None, # processor는 NetworkConfig를 입력으로 받습니다.
):
...
...
class NetworkConfig(object):
def __init__(
self,
enable_network_isolation: Union[bool, PipelineVariable] = None,
security_group_ids: Optional[List[Union[str, PipelineVariable]]] = None,
subnets: Optional[List[Union[str, PipelineVariable]]] = None,
encrypt_inter_container_traffic: Optional[Union[bool, PipelineVariable]] = None,
):
class EstimatorBase(with_metaclass(ABCMeta, object)):
"""Handle end-to-end Amazon SageMaker training and deployment tasks."""
def __init__(
self,
...
# 그러나 Estimator는 NetworkConfig를 풀어낸 형태로 입력을 받습니다.
security_group_ids: Optional[List[Union[str, PipelineVariable]]] = None,
subnets: Optional[List[Union[str, PipelineVariable]]] = None,
encrypt_inter_container_traffic: Optional[Union[bool, PipelineVariable]] = None,
enable_network_isolation: Union[bool, PipelineVariable] = None,
):
이러한 차이로 인해 Sagemaker pipeline을 사용하기 위해 SDK에 대한 추가 학습이 필요했고 작업 과정에서 인지 부하가 발생하고 있었습니다.
앞서 말씀드린 buzzflow 이전의 문제점들을 정리해 보면 아래와 같습니다.
- Sagemaker Pipeline에 대한 컨벤션 부재
- Sagemaker Pipeline SDK에 대한 인지 부하
- Sagemaker Pipeline에 대한 권한 관리 부재
- 통일되지 않은 모델 저장소
이제 buzzflow가 이 문제점들을 어떻게 해결했는지 설명하겠습니다.
AB(After Buzzflow)
파이프라인 정의
buzzflow를 개발하면서 가장 먼저 목표로 한 것은 모델 코드와 파이프라인 코드를 분리하고 모두가 일관된 형태로 파이프라인을 작성할 수 있는 환경을 만드는 것이었습니다. 여기에 추가로 Sagemaker SDK를 개선해 파이프라인을 작성에 대한 사용성을 개선하고자 했습니다.
설계 과정에서 파이프라인의 경우 반드시 코드 형태로 작성할 필요는 없다고 생각했고, 실제로 버즈빌의 데이터 플랫폼에서는 YAML 형태로 파이프라인을 작성하고 있어 통일성 측면에서 YAML로 파이프라인을 작성하도록 만드는 것이 유리할 것으로 판단했습니다. 이에 모델 관련 코드는 코드 형태로 존재하고 이들을 엮어내는 파이프라인은 YAML 형태로 작성하게 했습니다.
variables:
project_dir_relative_path: projects/prod/project_name
common_dir_relative_path: ${variables.project_dir_relative_path}/common
common_dir_local_path: /opt/ml/processing/input/code/common
query_dir_relative_path: ${variables.project_dir_relative_path}/query
...
여기에 YAML 파싱을 위해 서드파티 라이브러리인 OmegaConf를 적용하고 Variable Interpolation 등의 기능을 활용해 중복 정의를 줄여 사용성을 개선했습니다. 이를 이용하면 위와 같이 자주 반복되는 값을 마치 변수처럼 필드 이름으로 접근할 수 있게 됩니다.
그다음으로 진행한 작업은 Sagemaker Pipeline SDK를 분석해 파라미터의 이름을 일치시키고, 기능을 통일하는 작업이었습니다. 이를 위해 SDK의 기능을 래핑하는 추상화된 래퍼들을 만들고 이 래퍼로부터 실제 파이프라인을 생성하도록 만들었습니다. 예를 들어 buzzflow 내에서 Processor와 Estimator는 모두 NetworkPolicy라는 클래스로 네트워크 설정을 관리합니다. 사용자는 network라는 필드로 네트워크 설정을 일관성 있게 명시하면 됩니다.
# pipeline.yaml
network:
security_group_ids:
subnets:
# data_model.py
class ProcessorConfig(pydantic.BaseModel):
...
network_config: NetworkPolicyConfig = Field(NetworkPolicyConfig(), alias="network")
...
class EstimatorConfig(pydantic.BaseModel):
...
network_config: NetworkPolicyConfig = Field(NetworkPolicyConfig(), alias="network")
이 래퍼들은 Pydantic으로 구현되어 있어 누락된 필드는 없는지, 필요한 형식대로 데이터가 들어왔는지 등등 입력에 대한 검증 과정을 수행합니다. 이를 통해 실제 파이프라인을 생성하기 이전에 문제가 될 수 있는 부분을 빠르게 파악할 수 있습니다.
사용자가 YAML로 파이프라인을 작성하면 래퍼들을 기반으로 실제 파이프라인을 생성합니다. 이때 장기적으로 Sagemaker Pipeline 외의 다른 워크플로우 오케스트레이션 도구로 전환할 가능성이 있기 때문에 MLOps 엔지니어가 래퍼로부터 파이프라인을 생성하는 코드만 수정하면 YAML 수정 없이도 쉽게 새로운 도구로 마이그레이션할 수 있게 만들었습니다.
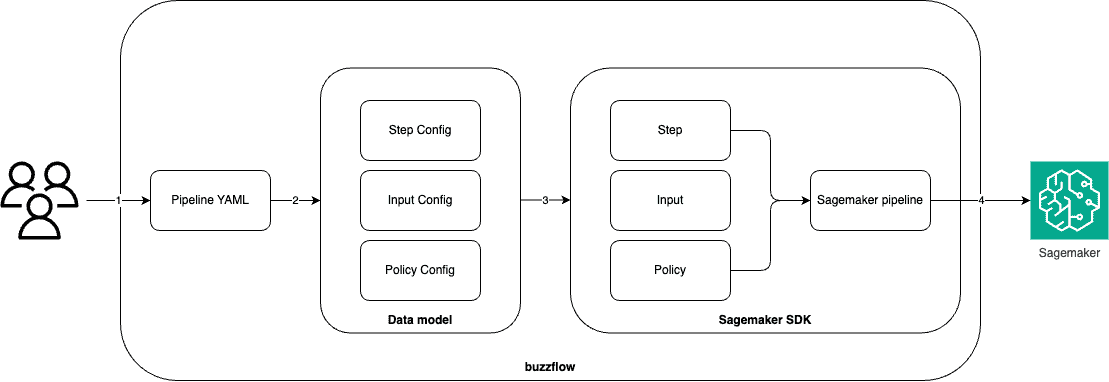
정리하면 파이프라인 생성은 아래와 같은 과정으로 이루어집니다.
- 사용자는 YAML 형태로 파이프라인을 작성합니다.
- buzzflow는 YAML을 파싱하고 데이터 모델을 생성해 YAML을 검증합니다
- 데이터 모델로부터 실제 파이프라인의 구성요소들을 생성합니다.
- 해당 구성요소들을 조합해 파이프라인을 생성하고 Sagemaker에 반영합니다.
이렇게 파이프라인에 대한 통일된 컨벤션을 만든 후에는 여러 프로젝트에 걸쳐 공통으로 사용하는 기능을 하나의 패키지로 관리해 중복 정의를 막고 재사용성을 높였습니다. 예를 들어 쿼리 실행 등의 코드는 여러 프로젝트에서 사용할 수 있으므로 함께 관리하고 있습니다. 이런 공용 패키지는 파이프라인을 생성할 때 자동으로 사용할 수 있도록 구성해 두어 사용자는 파이프라인 명세에 공용 패키지에 대한 내용을 추가할 필요가 없습니다.
# global_common/query.py
def run_athena_query(athena_query: str, save_path=None, region="us-west-2"):
...
def load_query(query_file_path: str, **kwargs):
...
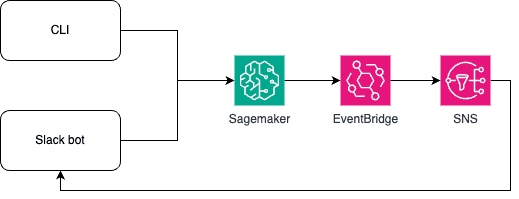
또한 CLI와 슬랙봇을 구현해 파이프라인 생성, 실행을 aws 콘솔 등에 접근하지 않고 수행할 수 있도록 만들었습니다. 사용자는 로컬 환경에서 코드를 작성하고 파이프라인을 생성, 실행할 수 있게 됩니다. 특히 슬랙봇을 사용하는 경우에는 AWS EventBridge, Simple Notification Service(SNS) 연동을 통해 파이프라인의 상태 변화에 대한 실시간 알람을 받을 수 있습니다.
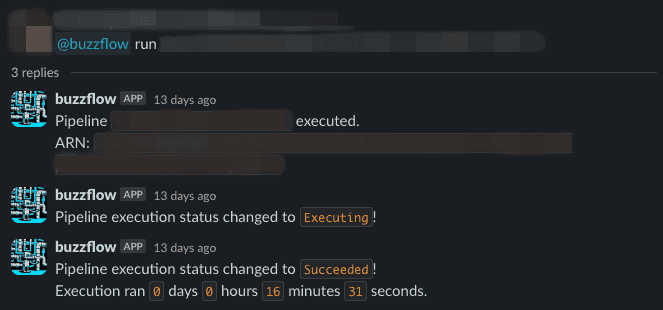
로컬 모드를 사용한 파이프라인 디버깅
Sagemaker pipeline의 특성 상 파이프라인 스텝을 실행하기 위해 인스턴스를 생성하고 컨테이너를 내려받는 시간이 필요한데, 이는 개발 과정에서 피드백 루프를 느리게 만듭니다. 또한 Sagemaker Pipeline의 경우 각 스텝에서 실행될 인스턴스 환경을 지정해 주어야 하는데요. 인스턴스 타입마다 가격이 다르기 때문에 CPU/메모리/디스크 등 리소스 사용량에 맞춰 인스턴스를 최적화하는 것이 중요합니다.
이를 위해 buzzflow는 로컬 모드 기능도 함께 제공하고 있습니다. 이를 이용해 로컬 환경에서 손쉽게 파이프라인을 생성해 테스트할 수 있습니다. Sagemaker에서 제공하는 로컬 모드를 기반으로 Prometheus, cAdvisor를 함께 사용해 파이프라인의 각 스텝이 어느 정도의 리소스를 사용하는지 확인할 수 있게 만들어 모델 개발자의 인스턴스 선택에 도움이 되도록 만들었습니다.
사용자는 이전과 동일하게 파이프라인을 YAML로 작성한 후에 CLI를 로컬 모드를 나타내는 플래그와 함께 실행하면 됩니다. 그러면 이제 생성한 파이프라인을 Sagemaker에 반영하는 대신 로컬 환경에서 도커를 이용해 파이프라인을 실행하게 됩니다. 파이프라인이 종료되면 cAdvisor와 Prometheus를 통해 수집한 메트릭을 출력합니다.
모델 저장소
통일되지 않은 모델 저장소의 경우 역시 Sagemaker 외의 다른 도구로 전환할 가능성이 있음을 고려하여 MLFlow로 마이그레이션 하기로 결정하였습니다. 일반적으로 MLFlow를 사용하는 경우 Host 등 몇 가지 설정이 추가로 필요한데요. buzzflow는 사용자 편의성을 위해 experiment manager라는 패키지를 구현하고 있어 모델 개발 시 설정에 대해 신경 쓸 필요 없이 바로 모델 저장소에 연결할 수 있습니다.
from experiment_manager.mlflow_manager import MLFlowExperimentManager
@MLFlowExperimentManager(experiment_name="")
def some_logic(param1, param2, ...):
...
mlflow.log_param()
mlflow.log_metric()
...
if __name__ == "__main__":
some_logic(param1, param2)
권한 관리
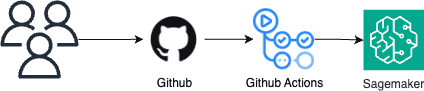
buzzflow는 리서치 코드의 수정이 프로덕션 파이프라인에 영향을 주지 않도록 프로젝트를 리서치와 프로덕션으로 구분해 관리하고 있습니다. 일반적인 사용자가 로컬에서 CLI를 통해 파이프라인을 생성하는 경우 개발 데이터베이스, S3 등에만 접근할 수 있습니다.
만약 프로덕션 파이프라인을 변경하고 싶다면 반드시 PR을 생성해 구성원의 리뷰를 받아야 합니다. PR이 반영되어 저장소의 main 브랜치에 변경 사항이 발생하면 파이프라인을 자동으로 생성하도록 Github Actions 기반의 CI를 구성했습니다. 필요하다면 테스트 코드를 함께 작성해 테스트 코드를 통과하는 경우에만 PR을 반영할 수도 있습니다.
주기적 재실행과 모니터링
머신러닝 파이프라인의 다양한 사용 사례가 생기면서 주기적으로 파이프라인을 재실행해야하는 요구 사항이 생겨났는데요. AWS EventBridge를 사용하면 주기적 재실행은 쉽게 구현할 수 있습니다. 하지만 실행 시점에 동적으로 파이프라인의 입력 파라미터가 달라지는 경우는 EventBridge로 대응이 불가능해 airflow를 통해 머신러닝 파이프라인을 트리거하는 형태로 운영 중입니다.
기존 사내 데이터 플랫폼과 연동하여 단순한 Cron뿐만 아니라 데이터 파이프라인이 완료되는 경우 머신러닝 파이프라인을 실행하는 등의 다양한 유스케이스를 지원하고 있습니다.
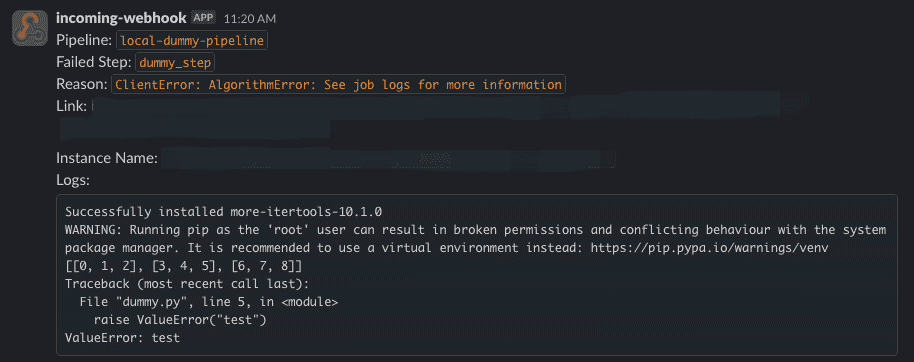
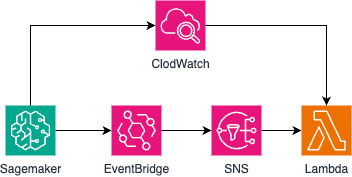
프로덕션 파이프라인의 경우 파이프라인의 상태를 적절하게 모니터링하는 것 또한 중요합니다. 여기에 로그 조회 기능을 추가해 파이프라인이 실패하면 로그를 함께 전송하도록 만들었습니다. 해당 기능은 EventBridge를 통해 파이프라인 실패를 탐지하고, SNS를 통해 lambda를 실행시켜 CloudWatch 로그를 출력하는 방식으로 구현되어 있습니다.
문서화

마지막으로 파이프라인 관련 작업을 위해 필요한 정보들을 버즈빌 내부 도구에 문서화해두어 문서를 참조해 파이프라인 개발을 진행할 수 있도록 했습니다.
마치면서
이번 글에서는 버즈빌의 ML 플랫폼 탄생 이전의 상태와 ML 플랫폼을 통해 달성하고자 했던 기본적인 목표 그리고 이를 어떻게 달성했는지에 대해서 소개드렸습니다. 이 플랫폼을 통해 학습한 모델의 배포와 관련해서는 다음 글을 통해 정리해보려 합니다.
읽어주셔서 감사합니다!

