
그리디 알고리즘을 이용한 중복 콘텐츠 클러스터링
Software Engineer
버즈빌이 제공하는 서비스 중 하나는 버즈빌과 제휴를 맺은 여러 콘텐츠 퍼블리셔들의 콘텐츠를 크롤링하여 유저들에게 서빙하는 것이 있습니다.
이렇게 크롤링한 콘텐츠들은 비슷한 내용을 가지는 중복 콘텐츠가 있기 마련입니다. 특히 뉴스 타입의 콘텐츠를 제공하는 퍼블리셔들은 그때그때 화제가 되는 주제를 가지고 콘텐츠를 만들다 보니 서로 비슷한 내용의 콘텐츠가 발행되는 경우가 많습니다.
그렇기에 크롤링한 콘텐츠 중에 서로 중복인 것들을 구분하고 중복된 다수의 콘텐츠 중 하나를 선택하여 유저에게 제공할 필요가 있습니다.
이 과정은 2가지 단계로 나눌 수 있습니다.
- 어느 콘텐츠가 어느 콘텐츠와 중복인지 분류한다.
- 중복인 콘텐츠 중에 어느 것을 대표로 선택할지 정한다
중복 분류와 중복 관계 그래프 생성
유저들에게 노출할 대표 콘텐츠를 선택하기 전에 먼저 어떠한 콘텐츠들이 서로 중복인지 판단할 필요가 있습니다.
콘텐츠의 중복 여부를 판단하는 프로세스는 이 포스팅의 주제는 아니지만 버즈빌에서 사용하는 방식은 간략히 설명하자면 다음과 같습니다.
- 각 콘텐츠의 이미지와 텍스트를 각각 적절한 알고리즘을 사용해 임베딩 벡터로 변환
- 모든 콘텐츠 사이의 이미지 임베딩 벡터의 cosine similarity와 텍스트 임베딩 벡터의 consine similarity 값을 구한다.
- 2번에서 두 스코어 중 하나라도 각 스코어의 threshold 값을 넘는 두 콘텐츠는 서로 중복으로 판단한다.
- 중복 여부를 판단하기 위해 모든 콘텐츠 간에 위 프로세스를 실행시킵니다.
두 콘텐츠 간의 중복인가 아닌가를 판단할 수 있는 프로세스가 존재한다면 콘텐츠 간의 중복 관계는 비 가중 그래프로 표현할 수 있습니다. 콘텐츠는 그래프의 노드가 되고, 서로 중복으로 판단되는 콘텐츠는 엣지로 연결됩니다.
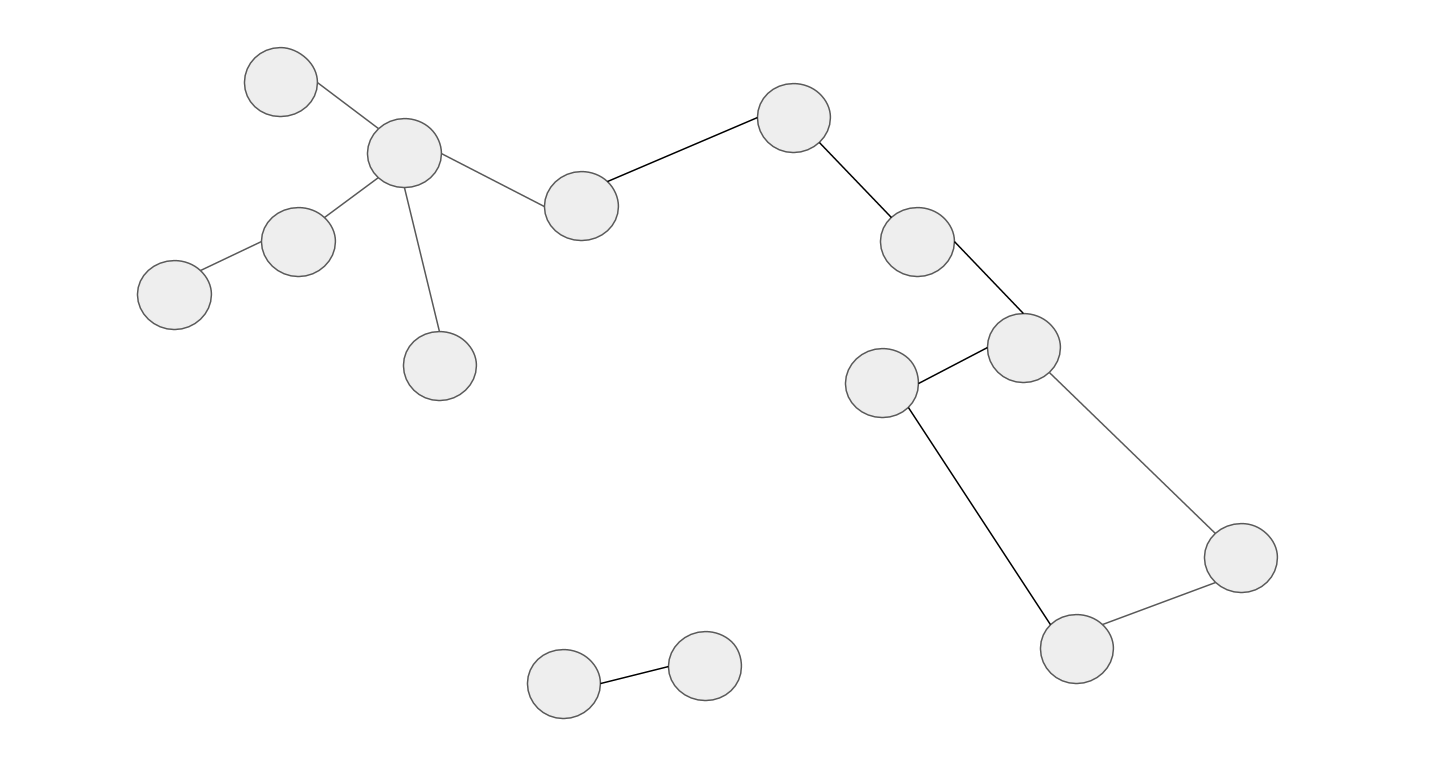 |
|---|
| Figure 1. 콘텐츠들 간의 중복 Relation 그래프 예시 |
중복 클러스터링
각 콘텐츠 간의 중복 관계 그래프가 완성된 후 어떻게 대표 콘텐츠를 선택하는 것이 바람직할까요?
이것은 일종의 그래프 클러스터링 문제라고 볼 수 있습니다. 서로 거리가 가까운 노드들을 한 클러스터로 묶고, 각 클러스트에서 대표 노드를 선택하는 것이지요.
생각해볼 수 있는 간단한 방법의 하나는 그래프에서 서로 간의 경로가 존재하는 모든 노드를 같은 중복 클러스터로 묶고 각 클러스터에 속한 노드 중에 하나를 대표로 선택할 수도 있겠습니다. 그러나 이것은 대표 콘텐츠와 중복이라고 판단되지 않는 콘텐츠가 같은 중복 클러스터에 속하게 됩니다.
한국인이라면 아래의 동요가 익숙할 것입니다.
원숭이 엉덩이는 빨~개
빨가면 사과
사과는 맛있어
맛있으면 바나나
바나나는 길어
길면 기차
기차는 빨라
빠르면 비행기
비행기는 높아
높으면 백두산
원숭이가 사과와 비슷하다는 문구와 사과는 바나나와 비슷하다는 문구는 납득이 될 수도 있습니다. 어쩌면 사람에 따라서는 원숭이는 바나나와 비슷하다는 것까지도 납득될 수도 있겠죠.
그러나 원숭이가 백두산과 비슷하다는 주장까지 나온다면 이것은 납득하기 어려울 것입니다.
만약 경로가 존재하는 모든 노드를 한 클러스터로 묶는 방식을 사용한다면 원숭이는 백두산과 같은 클러스터에 속하게 될 것입니다.
원숭이를 구경한 유저들은 백두산이 원숭이와 중복이라는 이유로 구경하지 못하게 되는 일이 일어나게 되죠.
중복 클러스터링의 필수 원칙과 약한 원칙
유저들에게 중복이 아닌 콘텐츠를 효율적으로 골라서 보여주기 위해 중복 클러스터링 알고리즘은 다음과 2개의 필수적인 원칙을 지켜야 합니다.
- 그래프의 각 노드는 대표로 선택되었거나 대표로 선택된 노드와 이웃이어야 한다.
- 대표로 선택된 노드들은 서로 이웃이어선 안된다.
위 원칙을 지키고 대표 콘텐츠를 선택하여 유저에게 보여줄 경우, 모든 콘텐츠는 유저에게 노출될 수 있거나, 대표로 선택된 콘텐츠와 중복이 됩니다.
위 2개의 필수 원칙에 아래의 2개의 원칙 중 하나를 정책으로 추가할 수 있습니다.
- 가능한 최소한의 수의 클러스터를 생성해야 한다. (최소 수 대표 원칙)
- 가능한 최대한의 수의 클러스터를 생성해야 한다. (최대 수 대표 원칙)
위 “원숭이 엉덩이는 빨개” 노래에서 원숭이에서 바나나까지의 관계만 그래프로 표현한다면 관계도는 다음과 같습니다.
원숭이--사과--바나나
최소 수 대표 원칙을 따른다면 사과를 대표로 선택하면 됩니다. 원숭이와 바나나 둘 다 사과의 클러스터에 속하게 되며, 클러스터의 개수는 1개가 됩니다.
(원숭이--사과--바나나)
최대 수 대표 원칙을 따르고자 한다면 원숭이와 바나나를 대표로 선택하면 됩니다. 클러스터는 2개가 되며 두 대표인 원숭이와 바나나는 서로 중복이 되지 않습니다. 사과는 원숭이나 바나나 둘 중 하나의 클러스터에 속하게 하면 됩니다. 아래의 예시는 사과가 원숭이가 대표로 있는 클러스터에 속한 경우입니다.
(원숭이--사과)--(바나나)
보시다시피 최소 수 대표 원칙에서 선택되는 대표 콘텐츠는 더 많은 수의 콘텐츠들과 중복이며 그렇기에 가능한 많은 수의 콘텐츠를 대표한다고 할 수 있습니다. 대신 대표들의 수는 더 적습니다.
반면에 최대 수 대표 원칙에서 선택되는 대표 콘텐츠는 더 적은 수의 콘텐츠를 대표하고 더 많은 수의 콘텐츠가 대표로 선택되어 유저들에게 노출됩니다.
그러나 최소 수 원칙과 최대 수 원칙을 지킬 수 있는 알고리즘은 어려워 보입니다. 원숭이 엉덩이는 빨개 노래처럼 모든 노드가 일렬로만 연결된 단순한 그래프만 존재하는 것이 아니고서는 이것은 복잡한 그래프 조합 문제가 됩니다.
하지만 1, 2번 원칙과 달리 두 선택적 원칙은 반드시 지켜야 할 필요가 있지 않습니다.
1, 2번 원칙만 지켜지면 어쨌든 한 콘텐츠는 유저에게 노출될 수 있거나, 혹은 해당 콘텐츠와 중복되는 콘텐츠가 유저에게 노출될 수 있으니까요.
그래서 위의 선택 원칙을 가능한 한 지키면 좋지만, 반드시 지켜야 할 필요는 없는 약한 원칙으로 변경합니다.
- 될 수 있으면 적은 수의 클러스터를 생성해야 한다. (적은 수 대표)
- 될 수 있으면 많은 수의 클러스터를 생성해야 한다. (많은 수 대표)
이렇게 하면 위의 두 약한 원칙 중 하나를 선택하여 그리디 알고리즘으로 쉽게 구현이 가능합니다.
그리디 알고리즘
적은 수 대표 약한 원칙을 따르는 그리디 알고리즘은 다음과 같습니다.
- 그래프에서 가장 엣지가 많은 노드를 선택, 대표로 지정하여 클러스터를 만든다
- 1번에서 선택한 노드와 이웃인 노드를 모두 1번에서 만든 클러스터에 넣는다.
- 그래프에서 클러스터에 속한 노드, 그리고 노드와 연결된 엣지도 지운다.
- 모든 노드가 사라질 때까지 1~3번을 반복한다.
만약 많은 수 대표 약한 원칙을 따르고자 한다면 위 단계에서 1번을 다음과 같이 바꾸면 됩니다.
- 그래프에서 가장 엣지가 적은 노드를 선택, 대표로 지정하여 클러스터를 만든다
다음 두 그림은 Figure 1 그래프에 각각 적은 수 대표, 많은 수 대표를 적용한 그리디 알고리즘의 결과입니다. 파란색 노드가 대표로 선택된 노드를 가리킵니다.
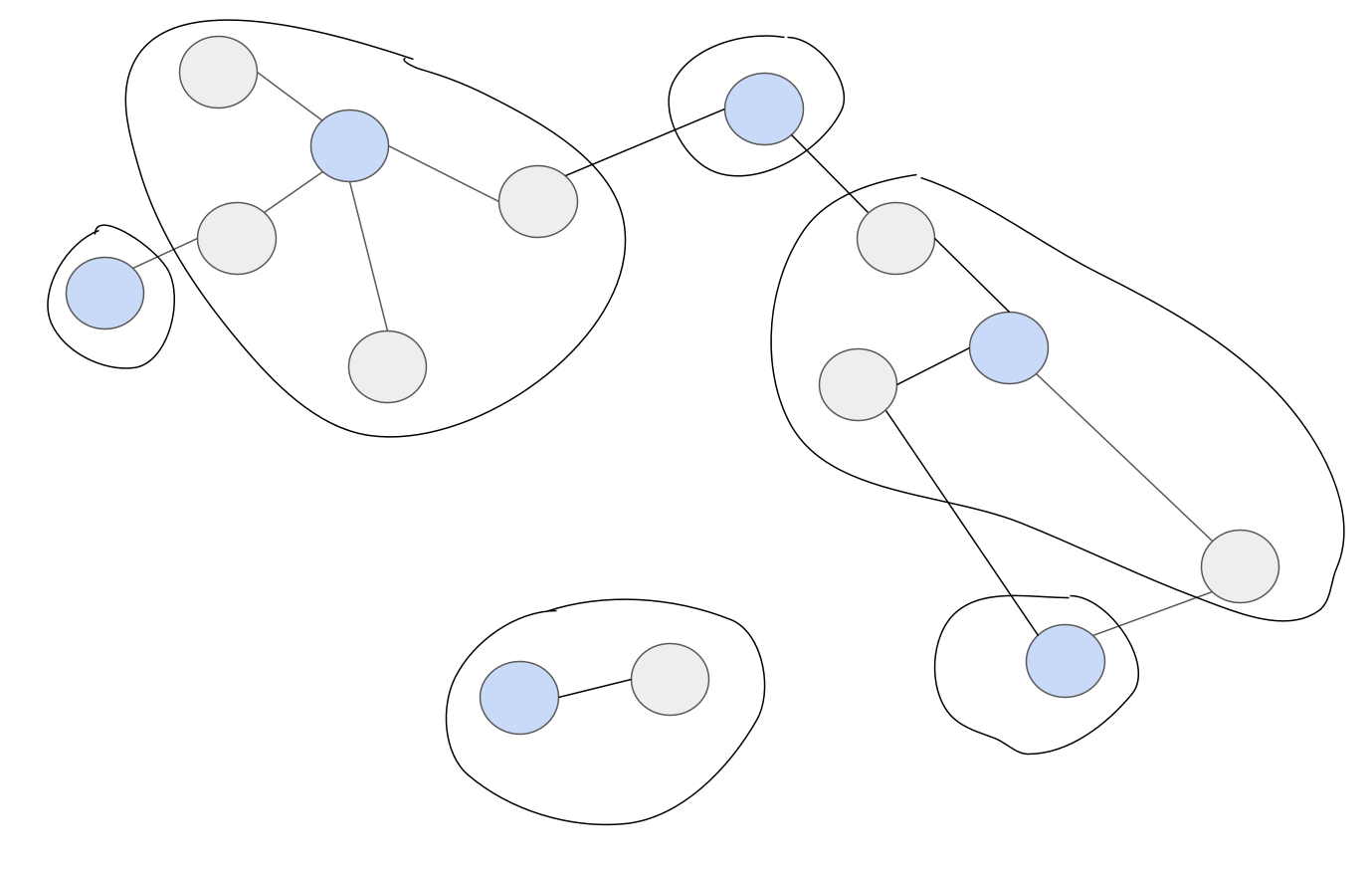 |
|---|
| Figure 2. Figure 1번의 그래프에 적은 수 대표 원칙 탐욕 알고리즘을 적용한 결과 |
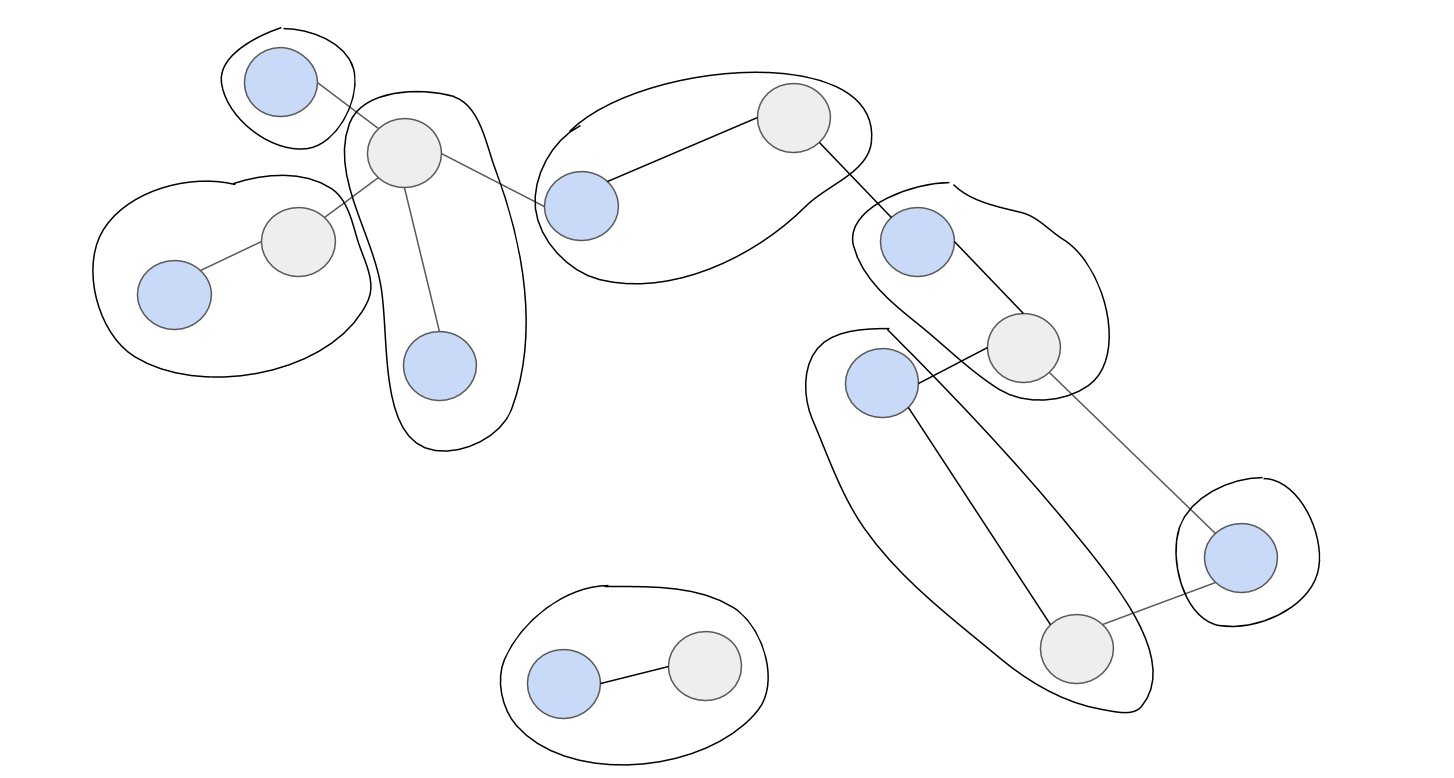 |
|---|
| Figure 3. Figure 1번의 그래프에 많은 수 대표 원칙 탐욕 알고리즘을 적용한 결과 |
배치 프로세스 그리고 찬탈
콘텐츠는 언제나 새롭게 생성되고 수명이 존재합니다. 아직 콘텐츠의 수명이 남아 있더라도 버즈빌에서는 유저들에게 최신 콘텐츠가 더 잘 보이도록 하므로 오래된 콘텐츠일수록 노출 빈도는 낮아집니다.
버즈빌에서는 위에서 설명한 중복 클러스터링 프로세스를 30분 간격으로 과거 6시간 동안의 콘텐츠에 배치로 적용합니다.
그렇기 때문에 한 번 대표로 선택된 콘텐츠는 30분 뒤에 다른 콘텐츠에 대표 자리를 찬탈당할 수도 있습니다.
만약 찬탈을 원하지 않는다면 위의 그리디 알고리즘을 실행하기 전에 이미 대표로 선택된 콘텐츠와 이웃한 콘텐츠의 노드는 모두 지운 뒤에 남은 노드만을 가지고 그리디 알고리즘을 실행하면 됩니다.
이미 대표로 선택된 콘텐츠와 이웃인 콘텐츠는 대표들의 클러스터에 흡수 된 것이 됩니다.
아래 그래프는 Figure 2에서 30분이 지났을 때의 상황을 보여줍니다. 새로운 콘텐츠가 들어오고, 오래된 콘텐츠는 사라집니다.
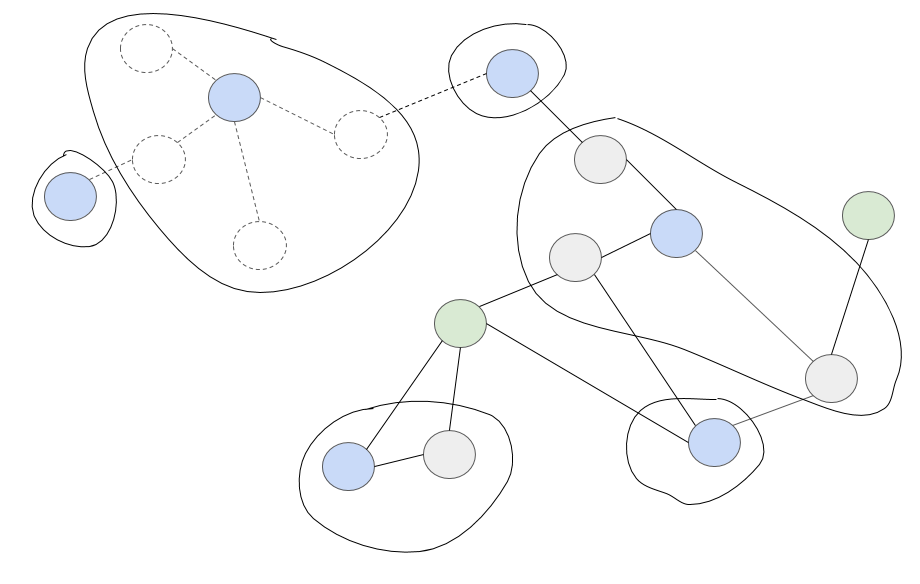 |
|---|
| Figure 4. Figure 2번에서 30분 뒤 |
| 새로 들어온 콘텐츠(초록색) |
| 6시간이 지나 더는 그래프에 존재하지 않는 콘텐츠(점선) |
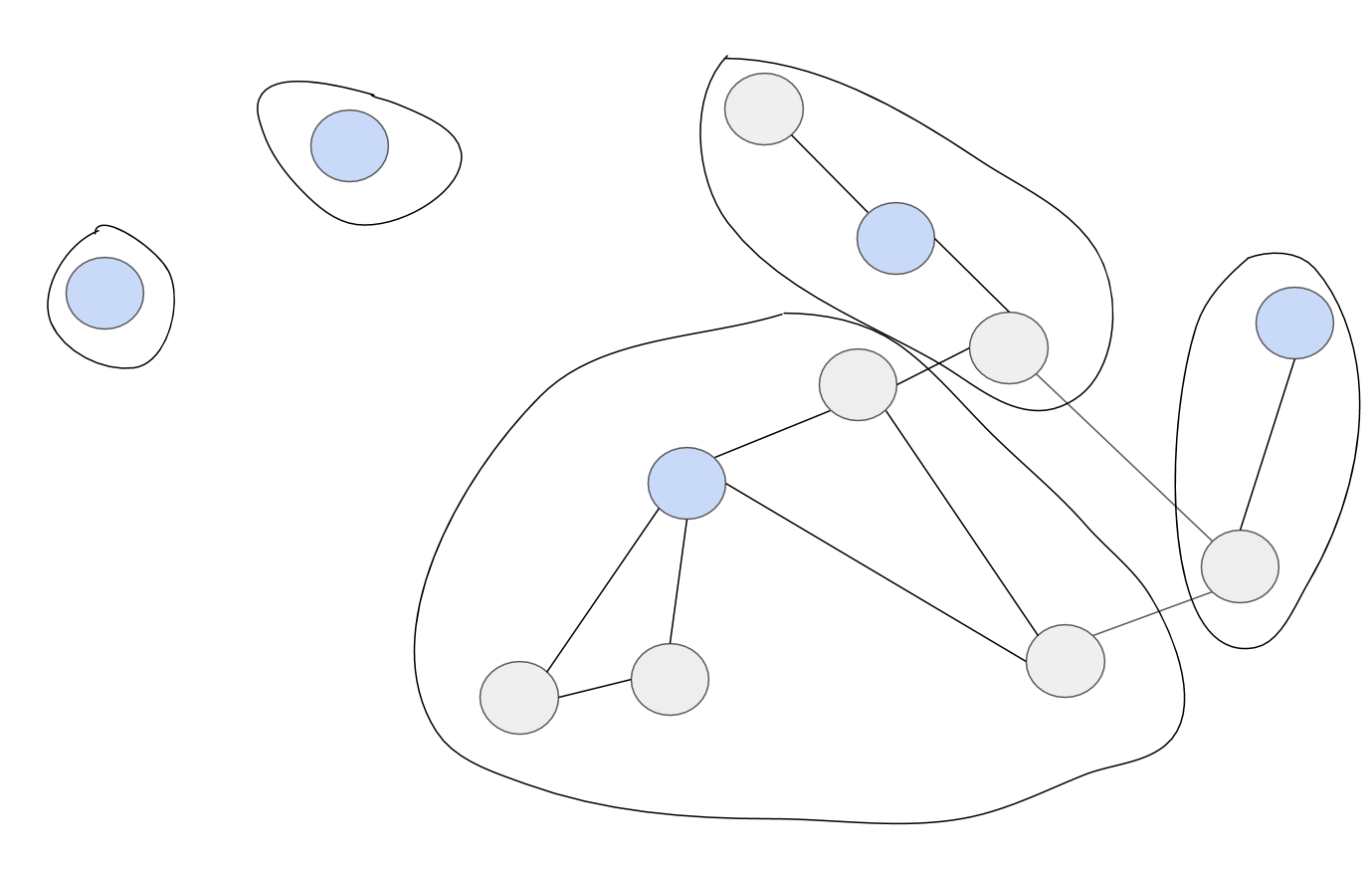 |
|---|
| Figure 5. 반란과 찬탈 허용 |
찬탈을 허용한다면 Figure 5와 결과가 나옵니다. 과거의 대표는 다른 노드에 대표 자리를 찬탈당할 수도 있습니다.
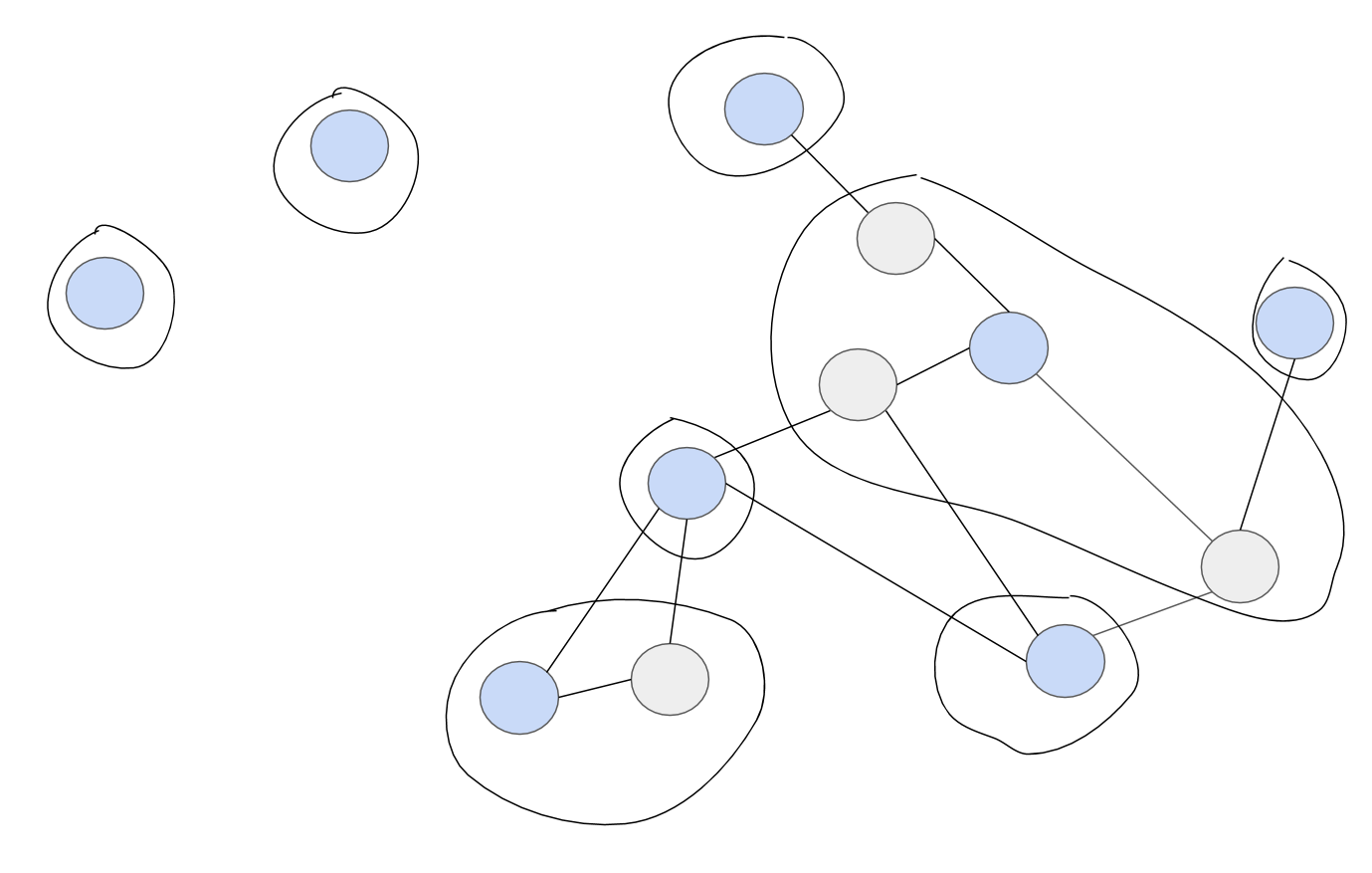 |
|---|
| Figure 6. 반란 불가 |
찬탈을 허용하지 않는다면 Figure 6에 보이듯이 한번 대표로 선택된 콘텐츠는 영원히 대표로 남습니다.
한번 대표로 선택된 콘텐츠가 찬탈당하는 혼란을 원하지 않는다면 찬탈을 금지해야합니다.
그때그때 가장 적절한 콘텐츠가 대표가 되는 것을 원한다면 찬탈을 허용할 필요가 있습니다.
개선점
위에서 이야기했듯이 배치로 실행되는 중복 클러스터링은 새로 생성된 콘텐츠가 다음 배치 실행 전까지 대기해야 한다는 단점이 있습니다.
현재의 버즈빌의 방식
현재의 버즈빌의 중복 콘텐츠 프로세싱은 30분마다 배치로 돌아가고 있습니다만, 새로 생성된 콘텐츠가 유저에게 보이기까지 30분이 걸리지는 않습니다.
이는 대표가 아닌 중복 콘텐츠를 유저에게 노출되지 않도록 하는 방식이 아니라 페널티를 줘서 노출빈도가 줄어들도록 하기 때문입니다. 또한 콘텐츠는 최신 콘텐츠 일수록 노출 보너스가 붙기에 최신 콘텐츠가 무조건 오래된 대표 콘텐츠보다 노출 빈도가 낮아지지 않습니다.
최신 콘텐츠는 일단 아직 대표로 분류되지 않더라도 어느 정도는 노출이 되다가 대표로 선택되면 더 잘 노출이 되게 하고 있습니다.
매트릭 트리를 이용한 스트리밍 프로세스
배치 방식을 스트리밍 방식으로 바꾸기 위한 개선방식 하나는 매트릭 트리를 사용하는 것입니다.
각 콘텐츠의 중복 여부를 판단하기 위해 생성한 임베딩 벡터를 매트릭 트리에 저장합니다. 매트릭 트리를 이용해 새로 생성된 콘텐츠와 중복 관계인 콘텐츠를 빠르게 찾고 중복 관계 그래프에 새 콘텐츠 노드를 빠르게 추가하는 것이 가능해질 것입니다.
-
찬탈을 허용할 경우
- 새로 추가된 콘텐츠와 경로가 존재하는 모든 콘텐츠를 가져옵니다.
- 그리디 알고리즘을 적용합니다.
-
찬탈을 허용하지 않는 경우
- 새로 추가된 콘텐츠와 이웃인 대표 콘텐츠를 가져옵니다.
- 대표 콘텐츠와 이웃인 새 콘텐츠는 모두 대표 콘텐츠의 클러스터에 흡수됩니다.
- 남은 새 콘텐츠에 그리디 알고리즘을 적용합니다.
찬탈을 허용하지 않는 경우는 경우 새로 추가된 콘텐츠와 이웃인 콘텐츠만 가져오면 되지만, 찬탈을 허용하면 추가로 그래프 경로가 존재하는 모든 콘텐츠를 가져와야 하므로 시간이 더 걸릴 것입니다.
스트리밍 프로세스를 구현하기 위해서 생성되는 콘텐츠를 메시지 큐 형식의 버퍼에 보관해서 버퍼에 일정 수 이상의 콘텐츠가 쌓여있거나 일정 시간이 지났을 때마다 클러스터링 프로세스가 실행되도록 하는 것도 생각해 볼 수 있습니다.
되돌아보며
처음 중복 콘텐츠 문제를 접했을 때 이것을 그래프 문제로 해석한 뒤에 어떻게 해결할지 방침을 정했었습니다. 처음에는 약한 원칙 없이 필수적인 원칙만을 정하고 이를 해결하기 위한 알고리즘을 구현하고자 했습니다만, 그러면 복잡하고 시간이 오래 걸리는 알고리즘의 도입이 필요하다는 것을 깨닫고 약한 원칙과 필수 원칙을 구분하여 그리디 알고리즘을 적용하는 방식을 생각해 냈습니다. 그리고 클러스터링 알고리즘을 배치로 적용하였습니다. 현재 클러스터링 프로세스는 단순히 30분 주기의 배치로 적용되고 있고 이것만으로도 충분히 만족할 만한 퍼포먼스를 보여줍니다. 그러나 사실 콘텐츠의 유입은 데이터 스트림이라고 볼 수 있고, 클러스터링 프로세스도 배치가 아닌 스트리밍으로 적용할 수도 있습니다. 만약 클러스터링 프로세스를 스트림으로 적용하고자 한다면 이것을 지원하기 위한 메트릭 트리의 퍼포먼스, 콘텐츠를 보관하는 큐의 정책 등에 대한 고려가 필요할 것입니다.

